
Easily Run, Scalable, Fault Tolerant Graph Databases With Neo4j Autonomous Clustering

Graph Database Product Specialist, Neo4j
5 min read

What is Autonomous Clustering?
Neo4j Graph Database version 5 (“Neo4j 5”) introduces Autonomous Clustering, which makes it easier to run and administer fault tolerant and highly available Neo4j clusters compared to its predecessors. The new capability in Neo4j 5 can automatically decide how to distribute primary (writable, synchronous) and secondary (read-only, asynchronous) database instances or copies across servers (bare metal machines, virtual machines, or containers) according to the requirements and constraints that the database administrator provides when specifying the cluster topology.
Server-Side Routing (SSR) is turned on by default in Neo4j 5. This enables the use of standard network load balancers and other network abstraction cloud technologies – Neo4j SSR will transparently take care of routing the queries internally to an appropriate DBMS server. Autonomous Clustering automatically takes care of provisioning databases across the cluster, making it much easier to run highly available, highly scalable clusters.
For example, think about what happens when one of the machines in a cluster goes down – instead of needing to manually reallocate database instances to surviving DBMS servers, Autonomous Clustering will automatically elect a new leader for any primary leader instances that were being hosted on the failed DBMS server. These new features make it easier to run highly available and scalable clusters by reducing the manual configuration you need to do in both setting up and maintaining the cluster.
We can look at a simple example with three applications, each with its own HA and scalability requirements, with databases hosted across a cluster of 5 DBMS servers. The diagram below shows how Neo4j Autonomous Clustering might automatically allocate databases across the DBMS servers in the cluster:
As the number of applications and number of users grows, Autonomous Clustering’s benefits become more and more valuable by reducing the administrative work associated with managing the databases and DBMS servers.
How It Works: A Sample Cluster
Let’s take a look at how Autonomous Clustering works. We’ll set up a three-node cluster, examine how it’s working, create a new database, and finally see how Server-Side Routing enables us to connect to any DBMS server in the cluster and use the new database. If you’d like to read all of the details, you can follow along in the documentation.
For our demonstration, we’ll run all three DBMS servers of the cluster on the same virtual machine; when we do this, we’ll need to make sure that each DBMS server uses different ports to avoid conflicts. Each server will have a name and a bolt port on which it listens for connections – the ports are configured in the neo4j.conf file for each server. We will use ports 7681, 7682, and 7863 respectively for the first, second, and third servers.
Server-side Routing is enabled by default in Neo4j 5, however, you need to add dbms.routing.default_router=SERVER to the configuration to use SSR as the default. If you wanted to use client-side routing, you would set this to CLIENT. After starting the three DBMS servers, we can connect to any of them. We’ll connect to server1 and issue a show servers command to see the state of the cluster:
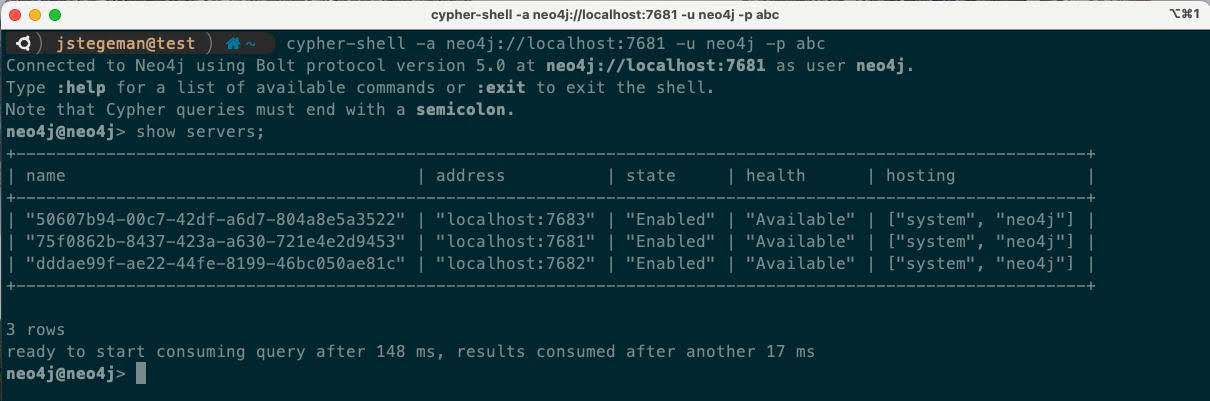
By default, each DBMS server is named with an internally generated ID. We can use rename server to give each of them a more friendly name:

Autonomous Provisioning of Databases to Cluster DBMS Servers
Now, let’s see how easy it is to create a new database with our required constraints and let Neo4j Autonomous Clustering figure out which DBMS servers to run the database. We can simply use create database and specify a topology, and Neo4j will automatically decide which DBMS servers to use. For this example, let’s use a topology of one primary (writable) and one secondary (read-only). This configuration would obviously not support High Availability – that would require three primaries. However we can use this as an example to see how Neo4j 5 Autonomous Clustering works:
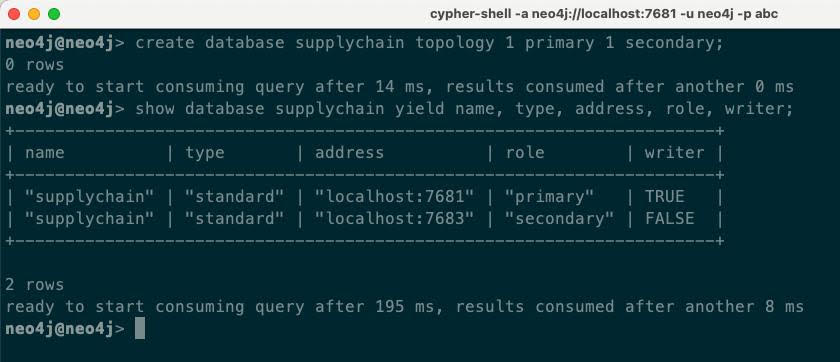
We can see in our example that Autonomous Clustering decided to run the primary on server1 and the secondary on server3. We can further show server-side routing working by connecting to server2 and testing both reading and writing to the new database:
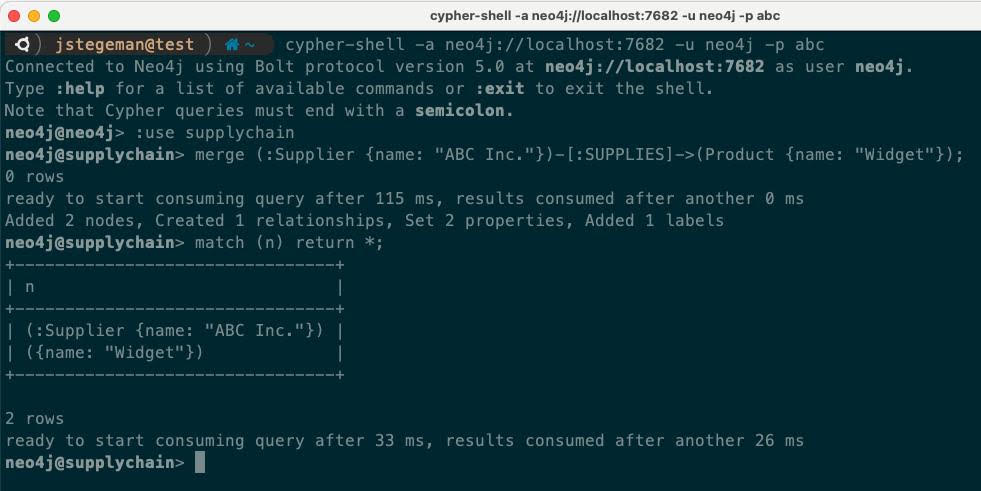
As the use of the database changes, for example to scale up or scale down, we can use CYPHER commands to alter the topology of our new database:
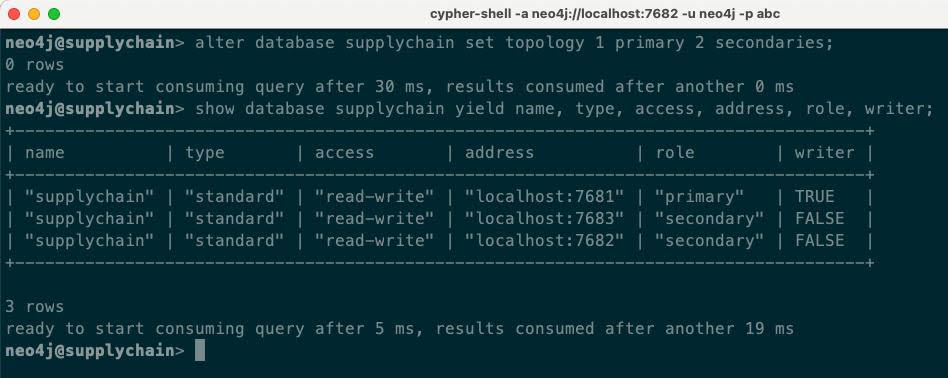
When we start to scale up the cluster and add more databases, the benefit of Autonomous Clustering really starts to show. I added six more DBMS servers to the cluster (giving a total of nine servers), and also created six more databases with various topologies. Autonomous clustering handled all of the provisioning work for us:
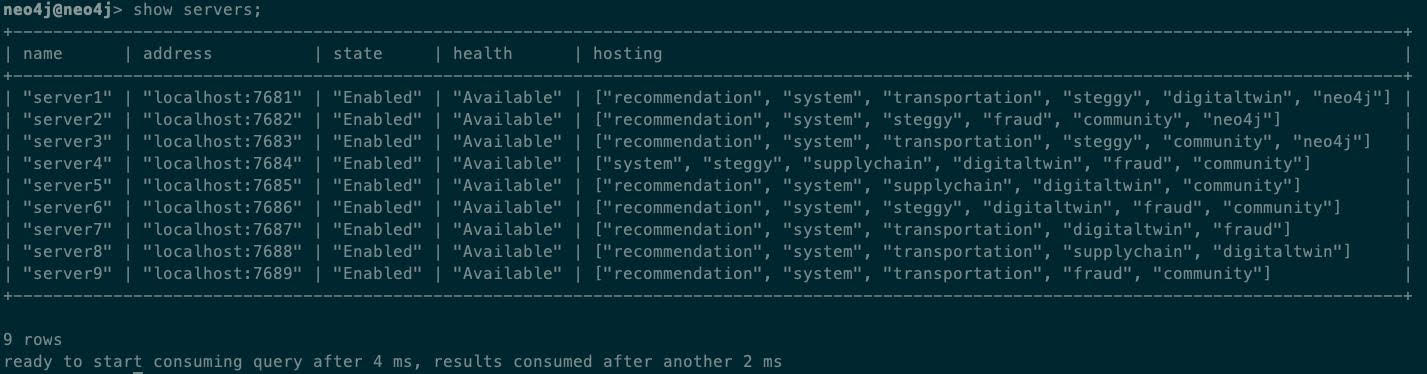
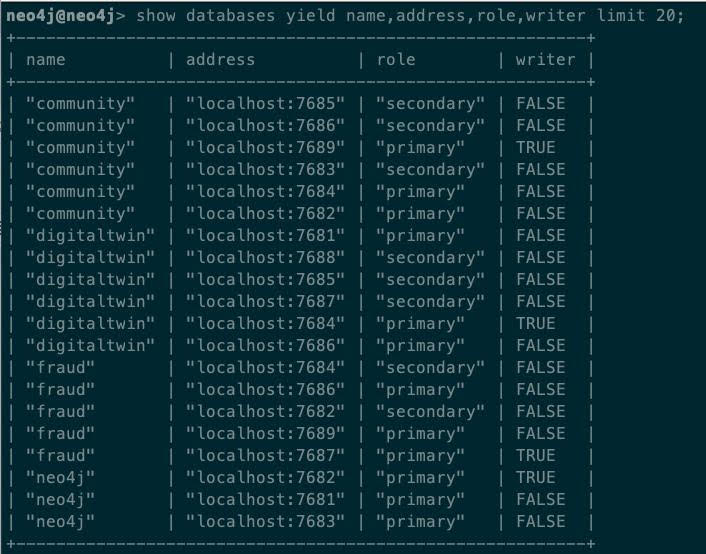
When we look at the databases, we see how the primary and secondary instances have been automatically distributed across the available servers:
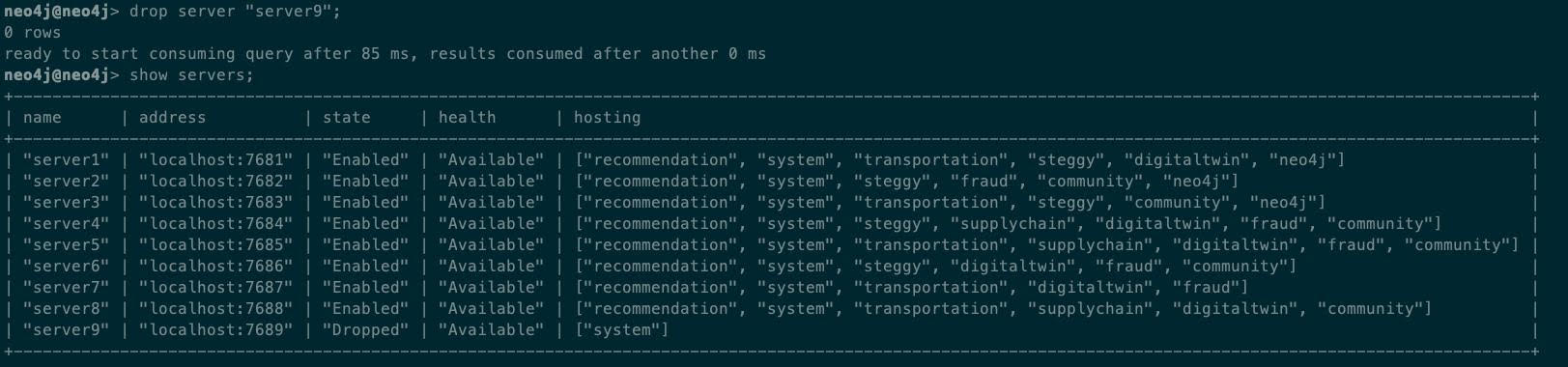
Even decommissioning servers is straightforward. At the start, our nine node cluster looks like this:

Let’s decommission server9:

The result:

And then:
Finally, we can ask Autonomous Clustering to make sure the databases from the dropped server are reallocated:
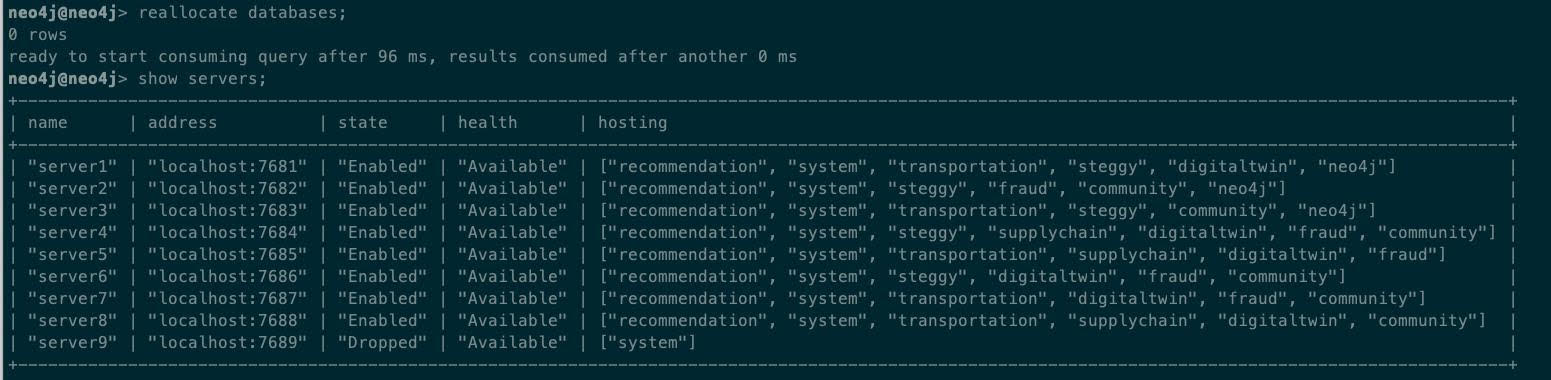
These examples show how easy it is to manage even complex environments with simple CYPHER commands.
Server Properties and Tags
Today, we can also use server properties to provide further information to Autonomous Clustering – modeConstraint can be set to PRIMARY or SECONDARY to ensure that the DBMS server only hosts primary or secondary instances of the database or NONE (the default) to allow hosting of any instance type. We can also set the allowedDatabases and deniedDatabases property to further shape the cluster.
In a future release of Neo4j 5, we will be introducing tags, which can be used to label DBMS servers with important descriptors such as geography, size, etc. Then, when creating a database, you will be able to specify the characteristics that are important for your database (e.g. “create two primaries in Europe on large servers and three secondaries in APAC”).
Summary
In summary, Autonomous Clustering in Neo4j 5 makes it easy to build highly reliable clusters that can handle large concurrent workloads, scaling horizontally to the needs of enterprise class applications. You can get started by downloading Neo4j 5 from the download center and checking out the Autonomous Clustering documentation in the Operations Manual.
Share Article



Explore
Related Articles

Optimize Weakly Connected Component Projections


Use Weakly Connected Components to Avoid Cypher Query Crashing
