Loading Data Into Neo4j Using pyneoinstance

Consulting Engineer, Neo4j
8 min read


Are you interested in stepping into the transformative world of graphs? Do you want to begin working with graphs to uncover connections, visualize insights, and even ground your large language models (LLMs)? Do you want to try all of this with a fun dataset full of Scooby-Doo monsters?
In this tutorial, we explore how to use graphs and graph analysis with a childhood favorite: Scooby-Doo. Be sure to read the first tutorial to learn how we developed the Cypher queries we will use here.
In Part 1, we explored how to turn the Scooby Doo CSV into a Neo4j graph using Cypher (the preferred graph query language) in the Neo4j command line. Here, we will take those previous Cypher queries and use them to upload the data straight from Python using a library called pyneoinstance. I will explain how to use pyneoinstance and show you how it makes uploading data to Neo4j in Python extremely easy.
pyneoinstance
While there are multiple ways to ingest data into Neo4j, my personal favorite is the pyneoinstance library. I prefer it because it works well with pandas and makes your calls feel very Pythonic! For an in-depth article about how to use pyneoinstance, see Alex Gilmore’s article.
# Python imports import pandas as pd import pyneoinstance
Separating Python and Cypher With config.yaml
One of the cleanest ways to ingest code to Neo4j using Cypher is by having two separate files: your Python script and a .yaml file. It makes your code cleaner, easier to maintain, and it is easier to work with Cypher code in the .yaml file rather than in a Python script or notebook.
Step 1: Connect to the Neo4j Database
When I create a .yaml file, I first load in my Neo4j URI, username, and password:
# config.yaml: Neo4j Credentials credentials: uri: 'insert uri here' user: neo4j password: 'password'
The pyneoinstance library provides a convenient function to load the file easily. Then you just need to access your credentials in the file and create a Neo4j connection:
# Python file - connection to Neo4j
# Retrieving the Neo4j connection credentials from the config.yaml file
configs=pyneoinstance.load_yaml_file('config.yaml')
creds=configs['credentials']
# Establishing the Neo4j connection
neo4j=pyneoinstance.Neo4jInstance(creds['uri'],creds['user'],creds['password'])
Now that we have established a connection to the database, we can begin loading the data into Neo4j.
Step 2: Add Cypher Queries to YAML file
Before loading your data into any graph database, you should have an idea of how you want the data structured as a graph (what data will be nodes, what will be the relationships between those nodes, and what data will become properties of the nodes and edges). Here is the data model from the first tutorial.

We will work on loading the data one section at a time. Loading your data into the graph in smaller pieces makes development and debugging much easier.
The pyneoinstance library is extremely useful because it has different methods for loading data with write Cypher queries. You can run a string Cypher query, or you can use the execute_write_query_with_data() function to run Cypher queries against a dataframe. We are going to use the latter method to load data from our dataframe.
We’ll begin with writing the necessary Cypher code to load in the Series and Episodes nodes, as well as the IS_SERIES relationship. (As a reminder: If you aren’t familiar with Cypher, check out the free resources on GraphAcademy.)
The key to writing Cypher queries to run on dataframes with pyneoinstance is to begin your Cypher query with the following:
WITH $rows AS rows UNWIND rows AS row
Then you can use row.column_name to access the values in your dataframe throughout your Cypher query, just like what we did in before with LOAD CSV. For example, the Cypher statement to load Series nodes would look like this:
WITH $rows AS rows
UNWIND rows AS row
MERGE (s:Series {seriesName:row.series_name})
Now that we have a general understanding of how pyneoinstance works, we can store Cypher queries in the config.yaml file. We will take the queries we developed before, but instead of using LOAD CSV, we will use the WITH $rows as rows UNWIND rows as row. Here is the config file with the Cypher queries for series, episodes, and monster nodes:
cypher:
load_nodes:
# loading in the series nodes
load_series: |
WITH $rows AS rows
UNWIND rows AS row
MERGE (s:Series {seriesName:row.series_name})
# loading in episode nodes and connecting them to existing series nodes
load_episodes: |
WITH $rows AS rows
UNWIND rows AS row
MATCH (s:Series {seriesName:row.series_name})
MERGE (e:Episode {episodeTitle:row.title})
SET e.season = row.season, e.network = row.network,
e.imdb = row.imdb, e.engagement = row.engagement,
e.runtime = row.runtime, e.format = row.format
MERGE (s) <-[:IN_SERIES] - (e)# Loading in monsters, subtypes, types, species, and the relationships between them
# loading in the monster, subtype, type, and species nodes
# as well as the relationships between them
load_monsters: |
WITH $rows AS rows
UNWIND rows AS row
MERGE (m:Monster {name:row.monster_name})
SET m.real = row.monster_real, m.gender = row.monster_gender
WITH m,row
MERGE (st:Subtype {name:row.monster_subtype})
MERGE (t:Type {name:row.monster_type})
MERGE (s:Species {name:row.monster_species})
WITH m,st,t,s,row
MATCH (e:Episode {episodeTitle:row.title})
MERGE (m) -[:APPEARS_IN] -> (e)
MERGE (m) -[:IS_SUBTYPE]->(st)
MERGE (st)-[:IS_TYPE]->(t)
MERGE (t)-[:IS_SPECIES]->(s)
Step 3: Run Queries in Python to Load Data
First, load the data into Python:
# Python - Load in the Scooby Doo data
df = pd.read_csv('https://raw.githubusercontent.com/CayleyCausey/ScoobyGraph/main/scoobydoo_new.csv')
Now that we have the data in Python and the Cypher code to load the series and episodes in our YAML file, we can upload the data using the function pyneoinstance.Neo4jinstance.execute_write_query_with_data(). We set the query parameter to the Cypher query string in the config.yaml file and the data parameter to the dataframe we loaded earlier.
For the monsters query, I changed the data parameter to only load in monster rows that are not null (because a small amount of the Scooby-Doo media does not include any monsters).
# Python - loading nodes # Load series nodes neo4j.execute_write_query_with_data(query =configs['cypher']['load_nodes']['load_series'],data=df) # Load episode nodes and IN_SERIES relationships neo4j.execute_write_query_with_data(query = configs['cypher']['load_nodes']['load_episodes'],data = df) # Load monster, subtype, type, and species nodes/relationships neo4j.execute_write_query_with_data(query = configs['cypher']['load_nodes']['load_monsters'],data = df[~df.monster_name.isna()])
Step 4: Continue Adding to the YAML file and Calling the Cypher in Python to Load All Data
We’ve loaded most of the data, but there are still some missing pieces. For example, the main characters (Fred, Daphne, Velma, Scooby, and Shaggy) need to be added to the database. We can add the Cypher to add main characters to our config.yaml file, which now looks like this:
credentials:
uri: 'insert uri here'
user: neo4j
password: 'password'
cypher:
load_nodes:
load_series: |
WITH $rows AS rows
UNWIND rows AS row
MERGE (s:Series {seriesName:row.series_name})
load_episodes: |
WITH $rows AS rows
UNWIND rows AS row
MATCH (s:Series {seriesName:row.series_name})
MERGE (e:Episode {episodeTitle:row.title})
SET e.season = row.season, e.network = row.network,
e.imdb = row.imdb, e.engagement = row.engagement,
e.runtime = row.runtime, e.format = row.format
MERGE (s) <-[:IN_SERIES] - (e)
load_monsters: |
WITH $rows AS rows
UNWIND rows AS row
MERGE (m:Monster {name:row.monster_name})
SET m.real = row.monster_real, m.gender = row.monster_gender
WITH m,row
MERGE (st:Subtype {name:row.monster_subtype})
MERGE (t:Type {name:row.monster_type})
MERGE (s:Species {name:row.monster_species})
WITH m,st,t,s,row
MATCH (e:Episode {episodeTitle:row.title})
MERGE (m) -[:APPEARS_IN] -> (e)
MERGE (m) -[:IS_SUBTYPE]->(st)
MERGE (st)-[:IS_TYPE]->(t)
MERGE (t)-[:IS_SPECIES]->(s)
load_main_characters: |
MERGE (:MainCharacter {name:"Fred"})
MERGE (:MainCharacter {name:"Daphne"})
MERGE (:MainCharacter {name:"Shaggy"})
MERGE (:MainCharacter {name:"Scooby"})
MERGE (:MainCharacter {name:"Velma"})
Because the main characters are not being loaded by a dataframe, we can just run them with the function execute_write_query().
# Python script: loading main characters # Loading the main characters neo4j.execute_write_query(configs['cypher']['load_nodes']['load_main_characters'])
Now that we’ve loaded all the nodes, we can load in the rest of the relationships. We will add the APPEARS_WITH code as we did before, but for the UNMASKED, CAPTURED, and CAUGHT relationships, we will make a change. Now that we are working in Python, we can simplify the Cypher statements and manipulate the data more in Python. This leads us to the following complete config.yaml:
credentials:
uri: 'insert uri here'
user: neo4j
password: 'password'
cypher:
load_nodes:
load_series: |
WITH $rows AS rows
UNWIND rows AS row
MERGE (s:Series {seriesName:row.series_name})
load_episodes: |
WITH $rows AS rows
UNWIND rows AS row
MATCH (s:Series {seriesName:row.series_name})
MERGE (e:Episode {episodeTitle:row.title})
SET e.season = row.season, e.network = row.network,
e.imdb = row.imdb, e.engagement = row.engagement,
e.runtime = row.runtime, e.format = row.format
MERGE (s) <-[:IN_SERIES] - (e)
load_monsters: |
WITH $rows AS rows
UNWIND rows AS row
MERGE (m:Monster {name:row.monster_name})
SET m.real = row.monster_real, m.gender = row.monster_gender
WITH m,row
MERGE (st:Subtype {name:row.monster_subtype})
MERGE (t:Type {name:row.monster_type})
MERGE (s:Species {name:row.monster_species})
WITH m,st,t,s,row
MATCH (e:Episode {episodeTitle:row.title})
MERGE (m) -[:APPEARS_IN] -> (e)
MERGE (m) -[:IS_SUBTYPE]->(st)
MERGE (st)-[:IS_TYPE]->(t)
MERGE (t)-[:IS_SPECIES]->(s)
load_main_characters: |
MERGE (:MainCharacter {name:"Fred"})
MERGE (:MainCharacter {name:"Daphne"})
MERGE (:MainCharacter {name:"Shaggy"})
MERGE (:MainCharacter {name:"Scooby"})
MERGE (:MainCharacter {name:"Velma"})
load_relationships:
CAUGHT: |
WITH $rows AS rows
UNWIND rows AS row
MATCH (m:Monster {name:row.monster_name})
MATCH (mc:MainCharacter {name:$name})
MERGE (mc) -[:CAUGHT]->(m)
UNMASKED: |
WITH $rows AS rows
UNWIND rows AS row
MATCH (m:Monster {name:row.monster_name})
MATCH (mc:MainCharacter {name:$name})
MERGE (mc) -[:UNMASKED]->(m)
CAPTURED: |
WITH $rows AS rows
UNWIND rows AS row
MATCH (m:Monster {name:row.monster_name})
MATCH (mc:MainCharacter {name:$name})
MERGE (m) -[:CAPTURED]->(mc)
APPEARS_WITH: |
MATCH (m:Monster) - [:APPEARS_IN] -> (e:Episode) <- [:APPEARS_IN] - (m1:Monster)
MERGE (m) - [:APPEARS_WITH] -> (m1)
We create the APPEARS_WITH relationships the same way we created main character nodes:
# Python - Creating APPEARS_WITH relationships neo4j.execute_write_query(configs['cypher']['load_relationships']['APPEARS_WITH'])
To create the UNMASKED, CAPTURED, and CAUGHT relationships, we create a dictionary to map the names in the CSV to the names in the Main Character nodes (e.g. fred -> Fred), find the relevant columns, and load the data into Neo4j.
We are using a variable in our Cypher statement called $name, which we set with parameters in execute_write_query_with_data. We also partition the data into two groups for each of these calls to reduce load on the database:
# Python script: monster-main character connections
# Adding in CAUGHT, UNMASKED, and CAPTURED relationships
adjusted_names = {'fred':'Fred',
'daphnie':'Daphne',
'velma': 'Velma',
'shaggy': 'Shaggy',
'scooby': 'Scooby'}
for col in df.columns:
# Finding the caught columns
if 'caught' in col:
if col.split('_')[1] in adjusted_names:
name = adjusted_names[col.split('_')[1]]
result = neo4j.execute_write_query_with_data(query = configs['cypher']['load_relationships']['CAUGHT'],data = df[df[col]==True],partitions=2,parameters={"name":name})
print(result)
# Finding the unmask columns
elif 'unmask' in col:
if col.split('_')[1] in adjusted_names:
name = adjusted_names[col.split('_')[1]]
result = neo4j.execute_write_query_with_data(query = configs['cypher']['load_relationships']['UNMASKED'],data = df[df[col]==True],partitions=2,parameters={"name":name})
print(result)
# Finding the capture columns
elif 'capture' in col:
if col.split('_')[1] in adjusted_names:
name = adjusted_names[col.split('_')[1]]
result = neo4j.execute_write_query_with_data(query = configs['cypher']['load_relationships']['CAPTURED'],data = df[df[col]==True],partitions=2,parameters={"name":name})
print(result)
Once you’ve run all of that, you’re done! You have successfully created your ScoobyGraph using pandas dataframes and pyneoinstance. Now you have an understanding of how to create more graphs from dataframes in the future.
Loading Data Into Neo4j Using pyneoinstance was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles
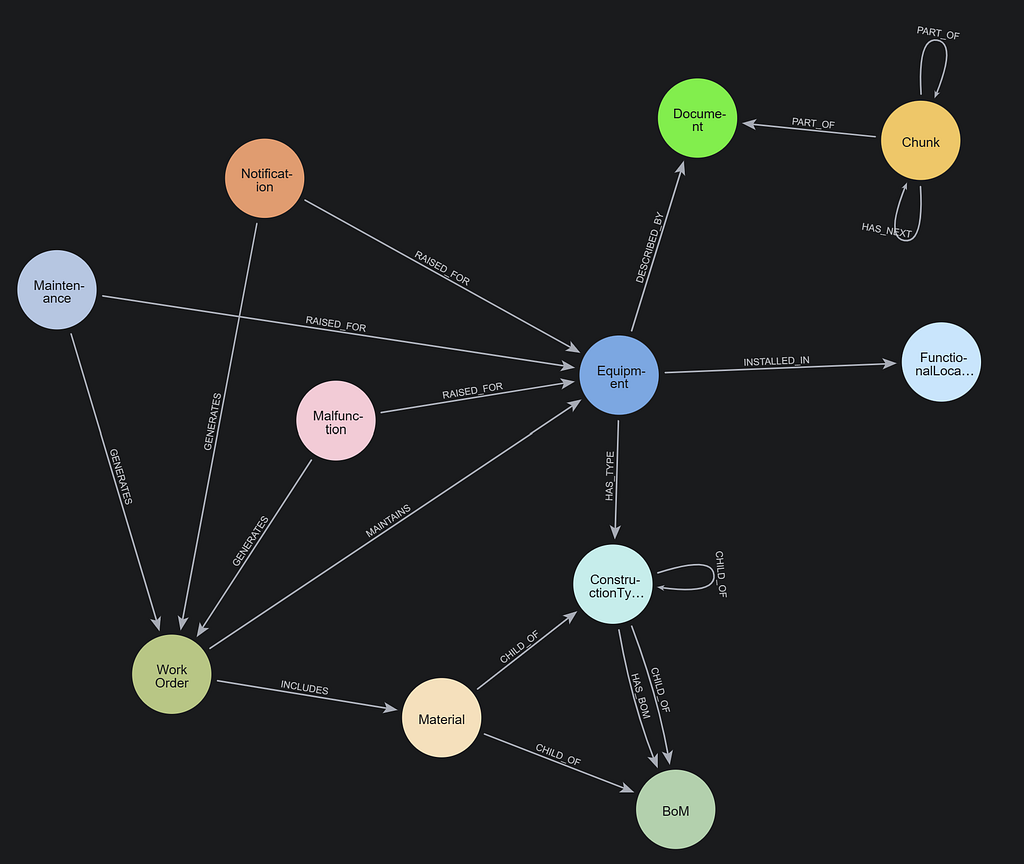
How a $28 Part Can Bring Down a $5M Machine — and How GenAI Stops It