



Understanding how Neo4j interprets and executes Cypher is key to debugging slow-running statements.
When I’m teaching someone Cypher, I always warn them that it can be very easy to write a bad Cypher statement. Case in point: I have been writing Cypher for years and have just had to debug a horrifically slow Cypher statement. For a couple of weeks now, we have had some reports that some of the quizzes on Neo4j GraphAcademy have been slow. Specifically, the quizzes on the Neo4j Fundamentals course were extremely slow, taking over a minute to return a response and sometimes even timing out completely. Other quizzes seemed to be fine, which meant one thing.
The ‘Britney’ Node
On a recent on-site visit, I was reminded of the term Britney node. Nowadays, this would probably be referred to as the Taylor Swift node, but in the past, it was a tongue-in-cheek way of referring to a node with many relationships coming into or going out of it. Following relationships to one of these nodes isn’t a problem. For example, in a social graph, T̶a̶y̶l̶o̶r̶ ̶S̶w̶i̶f̶t̶ Dave Grohl would be one of only a few hundred people that I follow. But if I were to find information on the people who follow them, following the relationship in the reverse direction would mean expanding through hundreds of millions of relationships and subsequently blowing up the query. This is what happened with the statement in question. The following is the statement used to save lesson progress. It shows the good, the bad, and the ugly of Cypher in one convenient query.MATCH (u:User)-[:HAS_ENROLMENT]->(e)-[:FOR_COURSE]->(c:Course)-[:HAS_MODULE]->(m)-[:HAS_LESSON]->(l)
WHERE u.sub = $sub AND c.slug = $course AND m.slug = $module AND l.slug = $lesson
SET e.lastSeenAt = datetime()
// Log Attempt
MERGE (a:Attempt { id: apoc.text.base64Encode(u.sub + '--'+ l.id + '--' + toString(datetime())) })
SET a.createdAt = datetime(), a.ref = $ref
MERGE (e)-[:HAS_ATTEMPT]->(a)
MERGE (a)-[:ATTEMPTED_LESSON]->(l)
// Log Answers
FOREACH (row IN $answers |
MERGE (q:Question { id: apoc.text.base64Encode(l.id + '--'+ row.id) })
ON CREATE SET q.slug = row.id
MERGE (l)-[:HAS_QUESTION]->(q)
MERGE (an:Answer { id: apoc.text.base64Encode(u.sub + '--'+ l.id + '--' + toString(datetime()) +'--'+ q.id) })
SET an.createdAt = datetime(),
an.reason = row.reason,
an.correct = row.correct,
an.answers = row.answers
FOREACH (_ IN CASE WHEN row.correct = true THEN [1] ELSE [] END | SET an:CorrectAnswer)
FOREACH (_ IN CASE WHEN row.correct = false THEN [1] ELSE [] END | SET an:IncorrectAnswer)
MERGE (a)-[:PROVIDED_ANSWER]->(an)
MERGE (an)-[:TO_QUESTION]->(q)
)
FOREACH (_ IN CASE WHEN size($answers) = size( [ (l)-[:HAS_QUESTION]->(q:Question) WHERE NOT q:DeletedQuestion | q ] ) AND ALL (a IN $answers WHERE a.correct = true ) THEN [1] ELSE [] END |
SET a:SuccessfulAttempt
MERGE (e)-[r:COMPLETED_LESSON]->(l)
SET r.createdAt = datetime()
)
RETURN l {
.*,
optional: l:OptionalLesson,
completed: exists((e)-[:COMPLETED_LESSON]->(l)),
next: [ (l)-[:NEXT]->(next) |
next { .slug, .title, .link }
][0],
previous: [ (l)<-[:NEXT]-(prev) |
prev { .slug, .title, .link }
][0],
questions: [ (l)-[:HAS_QUESTION]->(q) WHERE NOT q:DeletedQuestion | q {
.id,
.slug
}
]
} AS lesson
Admittedly, there’s a lot going on there, but you only need to look at the first line to see what was going wrong.
MATCH (u:User)-[:HAS_ENROLMENT]->(e)-[:FOR_COURSE]->(c:Course)-[:HAS_MODULE]->(m)-[:HAS_LESSON]->(l) WHERE u.sub = $sub AND c.slug = $course AND m.slug = $module AND l.slug = $lesson
Checking the PROFILE
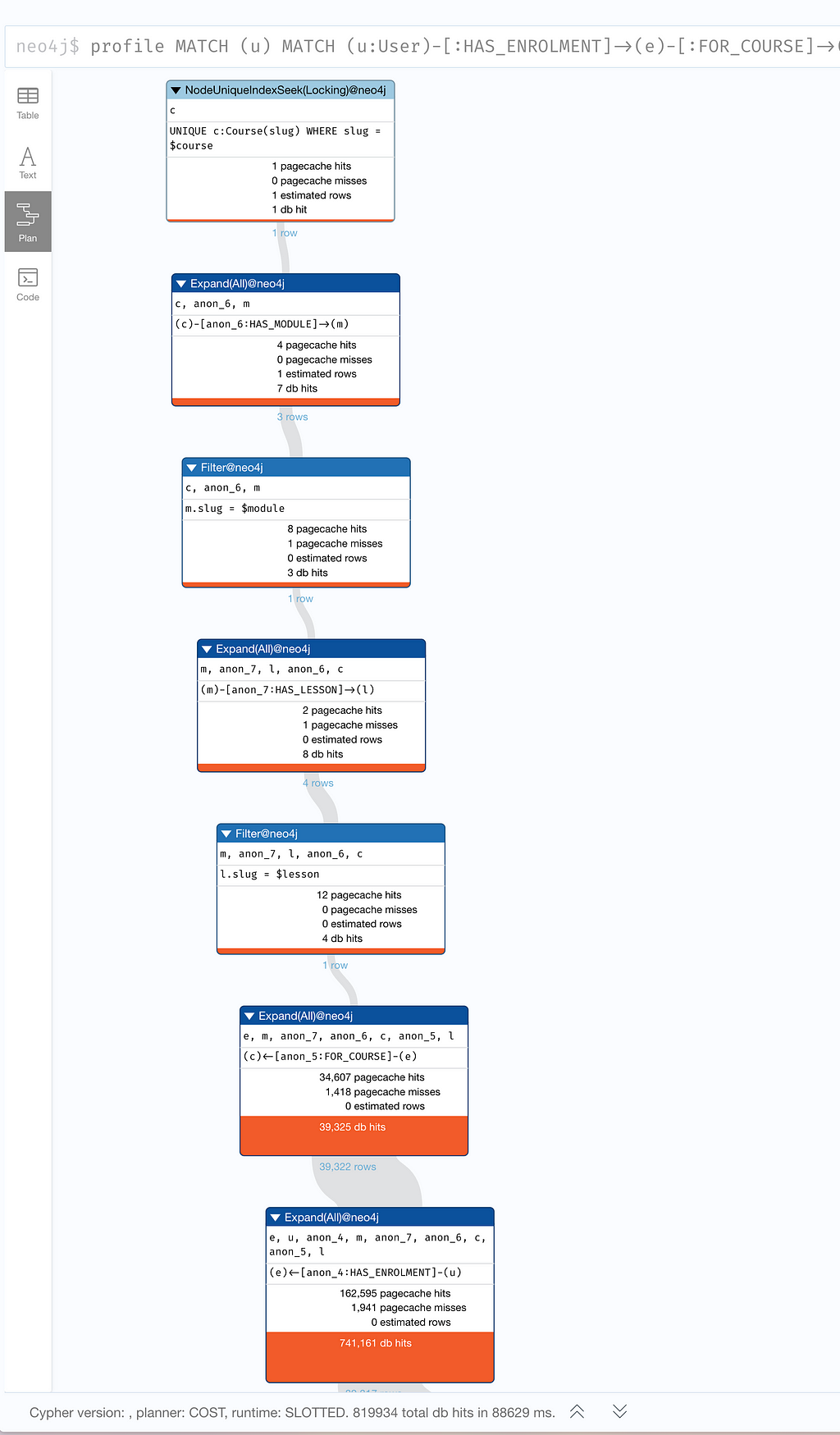
You can examine the query plan by appending EXPLAIN or PROFILE to the statement. Running EXPLAIN will give you estimated numbers without running anything while appendingPROFILE will execute the statement and give you exact results.
How Cypher Statements Are Run
Cypher is a declarative query language. You describe the patterns that you are interested in, and the database will figure out the best way to find the data. The underlying query engine will use database statistics and schema information to identify what it believes to be the best point to start the traversal.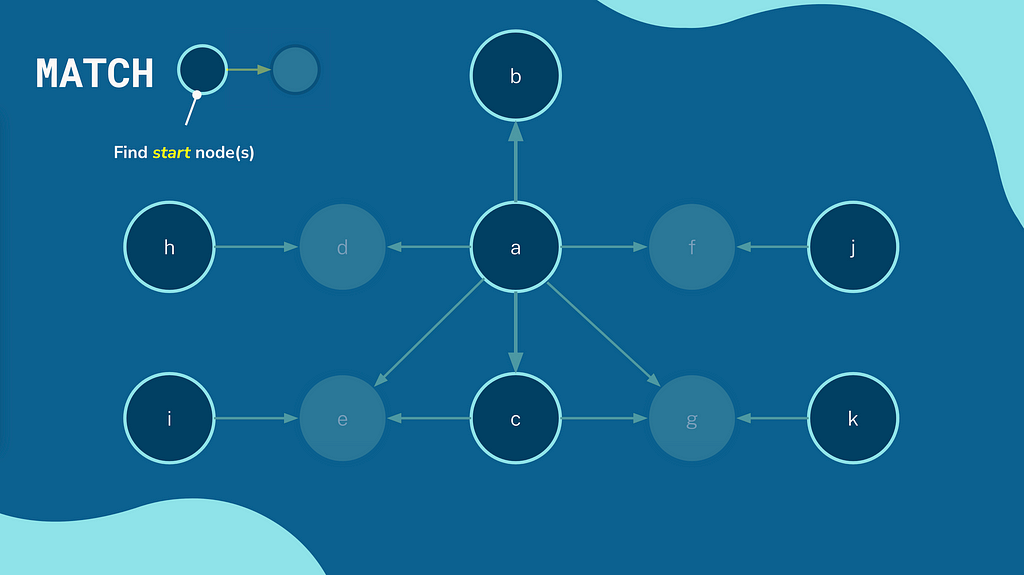
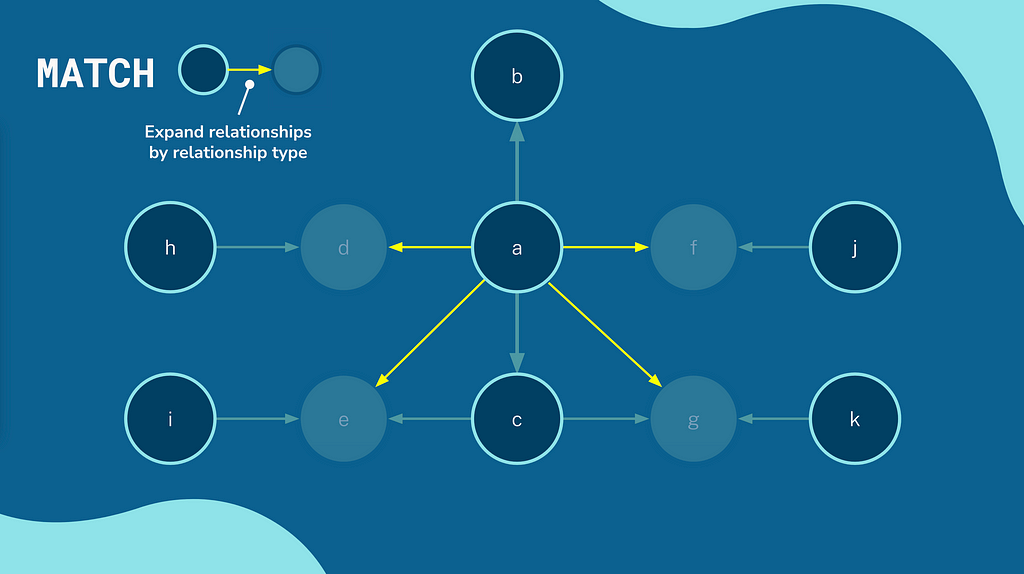
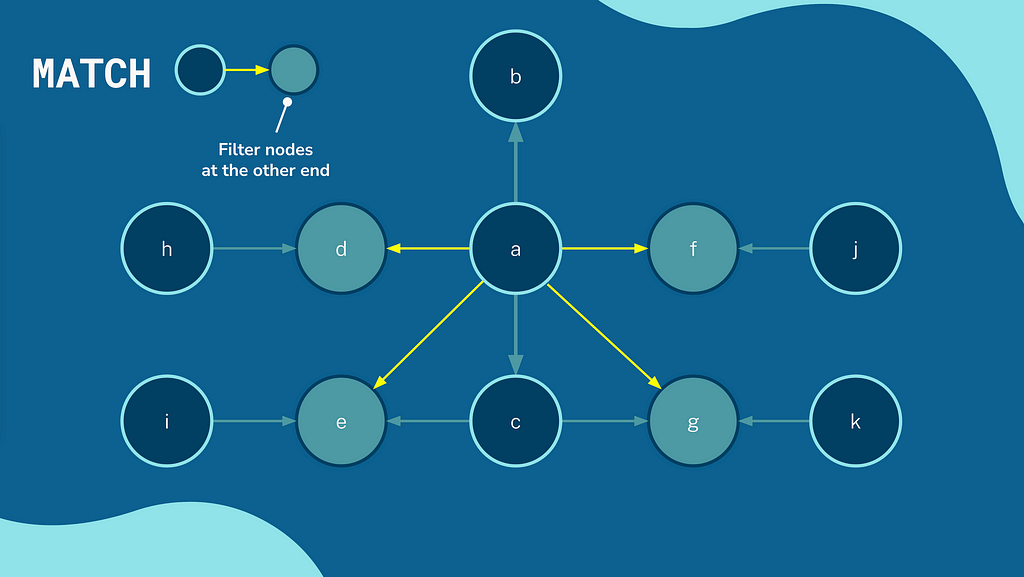
Where Things Went Wrong
99.9% of the time, things work perfectly. Sometimes, you must explore a large amount of data to answer a question. Sometimes, the best-laid plans of mice and men go awry. Based on the planner’s heuristics, it identified that the (:Course) node was the best place to start the traversal. In most cases, this makes sense. There are ~30 courses, each with at least 3 modules, and we have tens of thousands of users in the database, each with an average of more than 3 enrollments. As I mentioned, this also worked without issue for most courses. The Britney node here was the Neo4j Fundamentals course, the first course in our Beginners series and our most popular course with around 40k enrollments, so halfway through that pattern, these 40k :FOR_COURSE will be expanded. The problem is compounded when 40k :HAS_ENROLMENT relationships are expanded, 40k nodes are checked for a :User label, and so on. The final query registers a whopping 820 093 total db hits in 86205 ms.If you are interested in the data model as a whole, you can read my article on Building an Educational Platform on Neo4j.Building an Educational Platform on Neo4j Knowing the domain, I know that the (:User)-[:HAS_ENROLMENT]->(:Enrolment) , and the lower selectivity of the index will be quicker over time because any one user will only have a negligible proportion of the overall number of enrolments. I can provide a hint as to which index I would like the query engine to use using the USING INDEX clause.
profile MATCH (u:User)-[:HAS_ENROLMENT]->(e)-[:FOR_COURSE]->(c:Course)-[:HAS_MODULE]->(m)-[:HAS_LESSON]->(l) USING INDEX u:User(sub) WHERE u.sub = $sub AND c.slug = $course AND m.slug = $module AND l.slug = $lessonThat one change has a huge impact. The updated statement registers only 592 total db hits in 404 ms. That is a 1385% performance improvement! I could have written my statement with two MATCH clauses, one to find the User by ID and a second to expand their relationships to a course or use the WITH clause to force the planner to choose a particular index, but this is also a trick that every expert Cypher developer should have up their sleeve.
Become a Neo4j Expert!
If you would like to learn more about Neo4j, head over to Neo4j GraphAcademy, where we have courses for Developers and Data Scientists, plus a whole new series of Neo4j & LLM courses where you can learn how to use Neo4j to improve content generated by large language models. Free, Self-Paced, Hands-on Online TrainingSlow Cypher Statements and How to Fix Them was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.





