Controlling Query Processing
Building on the previous Cypher guides, this guide shows how to handle returning results in various ways, aggregating data, and using Cypher functions. Upon finishing this guide, you should be able to write and understand queries using these capabilities.
You should be familiar with graph database concepts and the property graph model. This guide is a continuation of the concepts discussed in the previous Cypher sections. You should be familiar with MATCH, Create/Update/Delete, and Filtering concepts before walking through this guide.
Beginner
Recap: Our Example Graph
All of our examples will continue with the graph example we have been using in the previous guides. Below is an image of the graph to familiarize yourself with the nodes and relationships used throughout this page.

Aggregation in Cypher
Helpful aggregation operations, such as calculating averages, sums, percentiles, minimum/maximum, and counts are available in Cypher. You may find many of these have similar syntax to other query language operations, but Cypher does work slightly differently with aggregation.
In Cypher, you do not need to specify a grouping key. It implicitly groups by a non-aggregate field in the return clause. This might seem much easier than more verbose syntax in other languages, but opinions may vary.
Aggregating by Count
Sometimes you only need to return a count of the results found in the database, rather than returning the objects themselves.
The count() function in Cypher allows you to count the number of occurences of entities, relationships, or results returned.
There are two different ways you can count return results from your query.
The first is by using count(n) to count the number of occurences of n and does not include null values.
You can specify nodes, relationships, or properties within the parentheses for Cypher to count.
The second way to count results is with count(*), which counts the number of result rows returned (including those with null values).
In our data set, some of our Person nodes have a Twitter handle, but others do not.
If we run the first example query below, you will see that we have the twitter property has a value for four people and is null for the other five people.
The second and third queries show how to use the different count options.
//Query1: see the list of Twitter handle values for Person nodes
MATCH (p:Person)
RETURN p.twitter;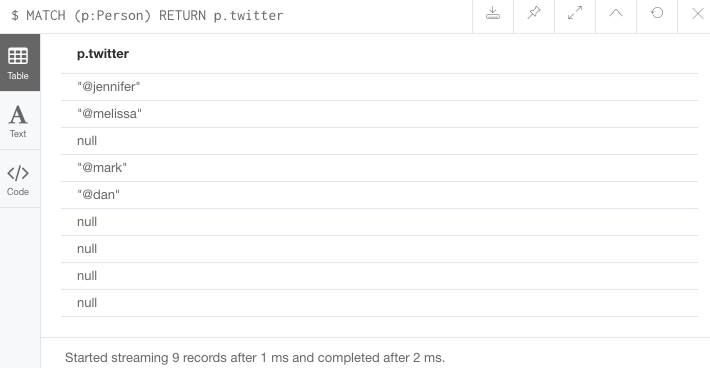
//Query2: count of the non-null `twitter` property of the Person nodes
MATCH (p:Person)
RETURN count(p.twitter);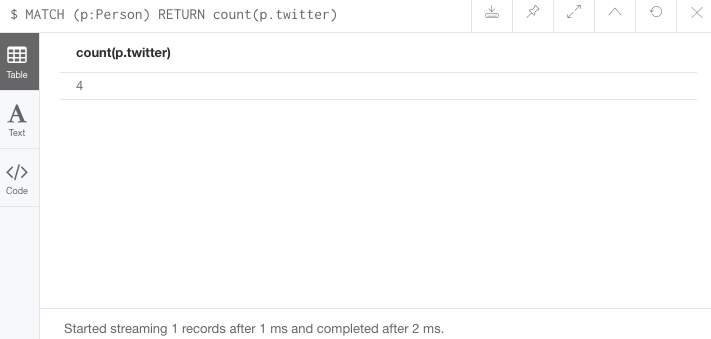
//Query3: count on the Person nodes
MATCH (p:Person)
RETURN count(*);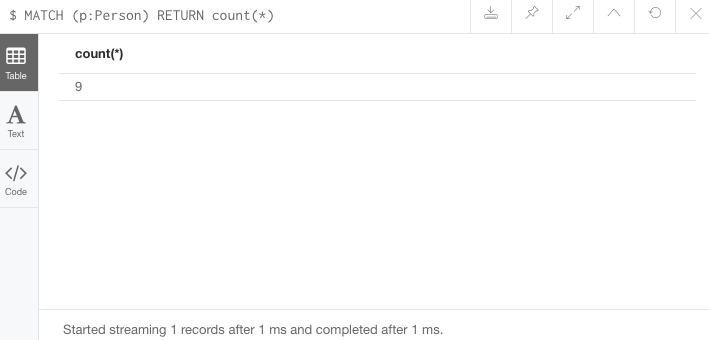
Aggregating Values
The collect() function in Cypher gives you the capability to aggregate values into a list.
You can use this to group a set of values based on a particular starting node, relationship, property.
For instance, if we listed each person in our example data with each of their friends (see the Cypher below), you would see duplicate names in the left column because each Person might have multiple friends, and you need a result for each relationship from the starting person.
To aggregate all of a person’s friends by the starting person, you can use collect().
This will group the friend values by the non-aggregate field (in our case, p.name).
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
RETURN p.name, collect(friend.name) AS friend
Counting Values in a List
If you have a list of values, you can also find the number of items in that list or calculate the size of an expression using the size() function.
The examples below return the number of items or patterns found.
//Query5: find number of items in collected list
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
RETURN p.name, size(collect(friend.name)) AS numberOfFriends;
//Query6: find number of friends who have other friends
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
WHERE size((friend)-[:IS_FRIENDS_WITH]-(:Person)) > 1
RETURN p.name, collect(friend.name) AS friends, size((friend)-[:IS_FRIENDS_WITH]-(:Person)) AS numberOfFoFs;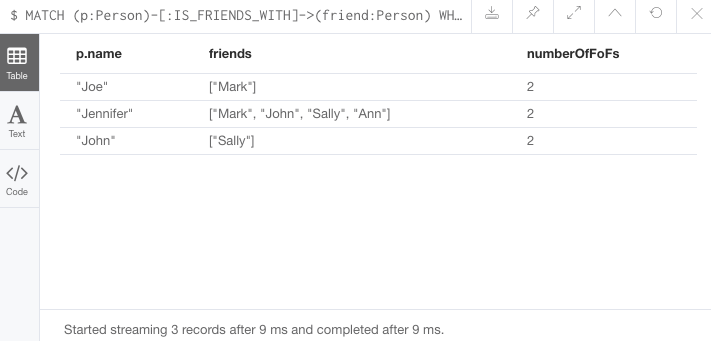
Manipulating Results and Output
Results from a query may only show part of the answer you were looking for in the data or may not be in the best format for easily viewing and understanding. This is where capabilities to link multiple queries together or to sort or limit the output can help you avoid sifting through the results manually to find value.
In the next few paragraphs, we will show how to use certain clauses and keywords to help you write queries to fully answer your data questions and format the results in a way that is simple and quickly valuable.
Chaining Queries Together
The syntax for the queries above might look a bit intimidating, but there are better ways to write it.
One of those ways is to use the WITH clause to pass values from one section of a query to another.
This allows you to execute some intermediate calculations or operations within your query to use later.
You must specify the variables in the WITH clause that you want to use later.
Only those variables will be passed to the next part of the query.
There are a variety of ways to use this functionality (e.g. count, collect, filter, limit results), but we will show a couple, including a cleaner version of our size() query from above.
For more information and ways to use WITH, check out the Cypher Manual section.
//Query7: find and list the technologies people like
MATCH (a:Person)-[r:LIKES]-(t:Technology)
WITH a.name AS name, collect(t.type) AS technologies
RETURN name, technologies;
//Query8: find number of friends who have other friends - cleaner Query6
MATCH (p:Person)-[:IS_FRIENDS_WITH]->(friend:Person)
WITH p, collect(friend.name) AS friendsList, size((friend)-[:IS_FRIENDS_WITH]-(:Person)) AS numberOfFoFs
WHERE numberOfFoFs > 1
RETURN p.name, friendsList, numberOfFoFs;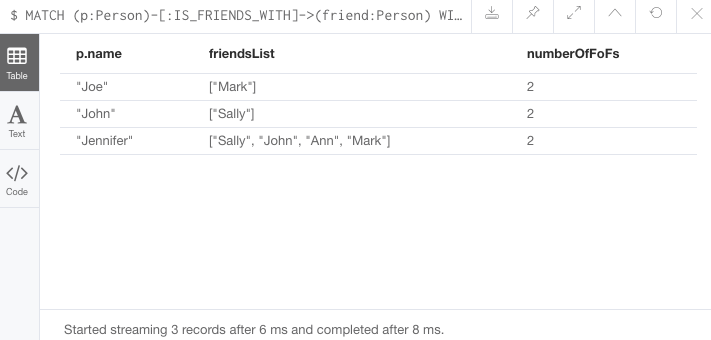
In the first query, we pass the Person name, and a collected list of the Technology types.
Only these items can be referenced in the RETURN clause.
We cannot use the relationship (r) or even the Person birthdate because we did not pass those values along.
In the second query, we can only reference p and any of its properties (name, birthdate, yrsExperience, twitter), the collection of friends (as a whole, not each value), and the number of friend-of-friends.
Since we passed those values in the WITH clause, we can use those in our WHERE or RETURN clauses.
WITH requires all values passed to have a variable (if they do not already have one).
Our Person nodes were given a variable (p) in the MATCH clause, so we do not need to assign a variable there.
|
|
Looping through List Values
If you have a list that you want to inspect or separate the values, Cypher offers the UNWIND clause.
This does the opposite of collect() and separates a list into individual values on separate rows.
Using UNWIND is frequently used for looping through JSON and XML objects when importing data, as well as everyday arrays and other types of lists.
Let us look at a couple of examples where we assume that the technologies someone likes also mean they have some experience with each one.
We are interested in hiring people who are familiar with Graphs or Query Languages, so we can write a query to find people to interview.
//Query9: for a list of techRequirements, look for people who have each skill
WITH ['Graphs','Query Languages'] AS techRequirements
UNWIND techRequirements AS technology
MATCH (p:Person)-[r:LIKES]-(t:Technology {type: technology})
RETURN t.type, collect(p.name) AS potentialCandidates;
//Query10: for numbers in a list, find candidates who have that many years of experience
WITH [4, 5, 6, 7] AS experienceRange
UNWIND experienceRange AS number
MATCH (p:Person)
WHERE p.yearsExp = number
RETURN p.name, p.yearsExp;
Ordering Results
Our list of potential hiring candidates from our last example might be more useful if we could order the candidates by most or least experience. Or perhaps we want to rank all of our people by age.
The ORDER BY keyword will sort the results based on the value you specify and in ascending or descending order (ascending is default).
Let’s use the same queries from our example with UNWIND and see how we can order our candidates.
//Query11: for a list of techRequirements, look for people who have each skill - ordered Query9
WITH ['Graphs','Query Languages'] AS techRequirements
UNWIND techRequirements AS technology
MATCH (p:Person)-[r:LIKES]-(t:Technology {type: technology})
WITH t.type AS technology, p.name AS personName
ORDER BY technology, personName
RETURN technology, collect(personName) AS potentialCandidates;
//Query12: for numbers in a list, find candidates who have that many years of experience - ordered Query10
WITH [4, 5, 6, 7] AS experienceRange
UNWIND experienceRange AS number
MATCH (p:Person)
WHERE p.yearsExp = number
RETURN p.name, p.yearsExp ORDER BY p.yearsExp DESC;
Notice that our first query has to order by Person name before collecting the values into a list.
If you do not sort first (put the ORDER BY after the RETURN), you will sort based on the size of the list and not by the first letter of the values in the list.
We also sort on two values - technology, then person.
This allows us to sort our technology so that all the persons that like a technology are listed together.
You can try out the difference in sorting by both values or one value by running these queries:
//only sorted by person's name in alphabetical order
WITH ['Graphs','Query Languages'] AS techRequirements
UNWIND techRequirements AS technology
MATCH (p:Person)-[r:LIKES]-(t:Technology {type: technology})
WITH t.type AS technology, p.name AS personName
ORDER BY personName
RETURN technology, personName;//only sorted by technology (person names are out of order)
WITH ['Graphs','Query Languages'] AS techRequirements
UNWIND techRequirements AS technology
MATCH (p:Person)-[r:LIKES]-(t:Technology {type: technology})
WITH t.type AS technology, p.name AS personName
ORDER BY technology
RETURN technology, personName;//sorted by technology, then by person's name
WITH ['Graphs','Query Languages'] AS techRequirements
UNWIND techRequirements AS technology
MATCH (p:Person)-[r:LIKES]-(t:Technology {type: technology})
WITH t.type AS technology, p.name AS personName
ORDER BY technology, personName
RETURN technology, personName;Returning Unique Results
Over the last couple of guides, there have been a few queries that have returned duplicate results due to multiple paths to the node or a node met multiple criteria. This redundancy can clutter results and make sifting through a long list difficult to find what you need.
To trim out duplicate entities, we can use the DISTINCT keyword.
We will use past examples from queries, as well as a query from a previous page to show how to use this to remove repetitive results.
//Query13: find people who have a twitter or like graphs or query languages
MATCH (user:Person)
WHERE user.twitter IS NOT null
WITH user
MATCH (user)-[:LIKES]-(t:Technology)
WHERE t.type IN ['Graphs','Query Languages']
RETURN DISTINCT user.name
For Query13, our use case is that we are launching a new Twitter account for tips and tricks on Cypher, and we want to notify users who have a Twitter account and who like graphs or query languages.
The first two lines of the query look for Person nodes who have a Twitter handle.
Then, we use WITH to pass those users over to the next MATCH, where we find out if the person likes graphs or query languages.
Notice that running this statement without the DISTINCT keyword will result in "Melissa" shown twice.
This is because she likes graphs, and she also likes query languages.
When we use DISTINCT, we only retrieve unique users.
Limiting Number of Results
There are times where you want a sampling set or you only want to pull so many results to update or process at a time.
The LIMIT keyword takes the output of the query and limits the volume returned based on the number you specify.
For instance, we can find each person’s number of friends in our graph. If our graph were thousands or millions of nodes and relationships, the number of results returned would be massive. What if we only cared about the top 3 people who had the most friends? Let’s write a query for that!
//Query14: find the top 3 people who have the most friends
MATCH (p:Person)-[r:IS_FRIENDS_WITH]-(other:Person)
RETURN p.name, count(other.name) AS numberOfFriends
ORDER BY numberOfFriends DESC
LIMIT 3
Our query pulls persons and the friends they are connected to and returns the person name and count of their friends.
We could run just that much of the query and return a messy list of names and friend counts, but we probably want to order the list based on the number of friends each person has starting with the biggest number at the top (DESC).
You could also run that much of the query to see the friends and counts all in order, but we only want to pull the top 3 people with the most friends.
The LIMIT pulls the top results from our ordered list.
|
Try mixing up the query by removing the |
Next Steps
This guide has shown how to do more with Cypher by combining clauses and keywords for aggregating and returning data. We have seen how to use functions in Cypher and some of the operations offered. In the next section, we will learn how to maintain data integrity by using constraints and increase query performance with indexes.
Resources
|
Are you struggling?
If you need help with any of the information contained on this page, you can reach out to other members of our community.
You can ask questions in the Cypher category on the Neo4j Community Site.
|
Was this page helpful?