Subqueries
Building on the previous Cypher guides, this guide shows how to write subqueries. Upon finishing this guide, you should be able to write and understand queries using this capability.
Please have Neo4j (version 4.0 or later) downloaded and installed. You should be familiar with graph database concepts and the property graph model. This guide is a continuation of the concepts discussed in the previous Cypher sections. You should be familiar with MATCH, Create/Update/Delete, and Filtering concepts before walking through this guide.
Beginner
Recap: Our Example Graph
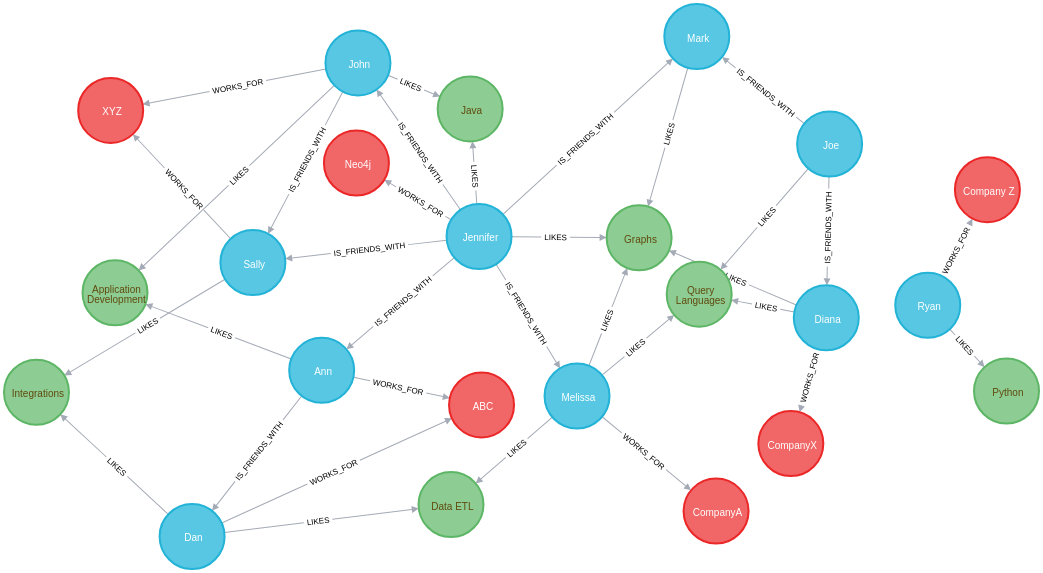
All of our examples will continue with the graph example we have been using in the previous guides, but include some more data for some of our later queries. Below is an image of the new graph.
We have added more Person nodes (blue) who WORK_FOR different Company nodes (red) and LIKE different Technology (green) nodes.
To recap, each person could also have multiple IS_FRIENDS_WITH relationships to other people.
This gives us a network of people, the companies they work for, and the technologies they like.
An introduction to Subqueries
Neo4j 4.0 introduced support for two different types of subqueries:
-
Existential sub queries in a
WHEREclause -
Result returning subqueries using the
CALL {}syntax
In this guide we’re going to learn how to write queries that use both these approaches.
Existential Subqueries
In the filtering on patterns section of the filtering query results guide, we learnt how to filter based on patterns. For example, we wrote the following query to find the friends of someone who works for Neo4j:
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE exists((p)-[:WORKS_FOR]->(:Company {name: 'Neo4j'}))
RETURN p, r, friendIf we run this query in the Neo4j Browser, the following graph is returned:

Existential subqueries enable more powerful pattern filtering.
Instead of using the exists function in our WHERE clause, we use the EXISTS {} clause.
We can reproduce the previous example with the following query:
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE EXISTS {
MATCH (p)-[:WORKS_FOR]->(:Company {name: 'Neo4j'})
}
RETURN p, r, friendWe’ll get the same results, which is nice, but so far all we’ve achieved is the same thing with more code!
Let’s next write a subquery that does more powerful filtering than what we can achieve with the WHERE clause or exists function alone.
Imagine that we want to find the people who:
-
work for a company whose name starts with 'Company' and
-
like at least one technology that’s liked by 3 or more people
We aren’t interested in knowing what those technologies are. We might try to answer this question with the following query:
MATCH (person:Person)-[:WORKS_FOR]->(company)
WHERE company.name STARTS WITH "Company"
AND (person)-[:LIKES]->(t:Technology)
AND size((t)<-[:LIKES]-()) >= 3
RETURN person.name as person, company.name AS company;If we run this query, we’ll see the following output:
Variable `t` not defined (line 4, column 25 (offset: 112))
"AND (person)-[:LIKES]->(t:Technology)"
^We can find people that like a technology, but we can’t check that at least 3 people like that technology as well, because the variable t isn’t in the scope of the WHERE clause.
Let’s instead move the two AND statements into an EXISTS {} block, resulting in the following query:
MATCH (person:Person)-[:WORKS_FOR]->(company)
WHERE company.name STARTS WITH "Company"
AND EXISTS {
MATCH (person)-[:LIKES]->(t:Technology)
WHERE size((t)<-[:LIKES]-()) >= 3
}
RETURN person.name as person, company.name AS company;Now we’re able to successfully execute the query, which returns the following results:
| person | company |
|---|---|
"Melissa" |
"CompanyA" |
"Diana" |
"CompanyX" |
If we recall the graph visualisation from the start of this guide, Ryan is the only other person who works for a company whose name starts with "Company".
He’s been filtered out in this query because the only Technology that he likes is Python, and there aren’t 3 people who like Python.
Result returning subqueries
So far we’ve learnt how to use subqueries to filter out results, but this doesn’t fully show case their power. We can also use subqueries to return results as well.
Let’s say we want to write a query that finds people who like Java or have more than one friend.
And we want to return the results ordered by date of birth in descending order.
We can get some of the way there using the UNION clause:
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC
UNION
MATCH (p:Person)
WHERE size((p)-[:IS_FRIENDS_WITH]->()) > 1
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC;If we run that query, we’ll see the following output:
| person | dob |
|---|---|
"Jennifer" |
1988-01-01 |
"John" |
1985-04-04 |
"Joe" |
1988-08-08 |
We’ve got the correct people, but the UNION approach only lets us sort results per UNION clause, not for all rows.
We can try another approach, where we execute each of our subqueries separately and collect the people from each part using the COLLECT function.
There are some people who like Java and have more than one friend, so we’ll also need to use a function from the APOC Library to remove those duplicates:
// Find people who like Java
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
WITH collect(p) AS peopleWhoLikeJava
// Find people with more than one friend
MATCH (p:Person)
WHERE size((p)-[:IS_FRIENDS_WITH]->()) > 1
WITH collect(p) AS popularPeople, peopleWhoLikeJava
// Filter duplicate people
WITH apoc.coll.toSet(popularPeople + peopleWhoLikeJava) AS people
// Unpack the collection of people and order by birthdate
UNWIND people AS p
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESCIf we run that query, we’ll get the following output:
| person | dob |
|---|---|
"Joe" |
1988-08-08 |
"Jennifer" |
1988-01-01 |
"John" |
1985-04-04 |
This approach works, but it’s more difficult to write, and we have to keep passing through parts of state to the next part of the query.
The CALL {} clause gives us the best of both worlds:
-
We can use the UNION approach to run the individual queries and remove duplicates
-
We can sort the results afterwards
Our query using the CALL {} clause looks like this:
CALL {
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p
UNION
MATCH (p:Person)
WHERE size((p)-[:IS_FRIENDS_WITH]->()) > 1
RETURN p
}
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC;If we run that query, we’ll get the following output:
| person | dob |
|---|---|
"Joe" |
1988-08-08 |
"Jennifer" |
1988-01-01 |
"John" |
1985-04-04 |
We could extend our query further to return the technologies that these people like, and the friends that they have. The following query shows how to do this:
CALL {
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p
UNION
MATCH (p:Person)
WHERE size((p)-[:IS_FRIENDS_WITH]->()) > 1
RETURN p
}
WITH p,
[(p)-[:LIKES]->(t) | t.type] AS technologies,
[(p)-[:IS_FRIENDS_WITH]->(f) | f.name] AS friends
RETURN p.name AS person, p.birthdate AS dob, technologies, friends
ORDER BY dob DESC;| person | dob | technologies | friends |
|---|---|---|---|
"Joe" |
1988-08-08 |
["Query Languages"] |
["Mark", "Diana"] |
"Jennifer" |
1988-01-01 |
["Graphs", "Java"] |
["Sally", "Mark", "John", "Ann", "Melissa"] |
"John" |
1985-04-04 |
["Java", "Application Development"] |
["Sally"] |
We can also apply aggregation functions to the results of our subquery. The following query returns the youngest and oldest of the people who like Java or have more than one friend
CALL {
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p
UNION
MATCH (p:Person)
WHERE size((p)-[:IS_FRIENDS_WITH]->()) > 1
RETURN p
}
RETURN min(p.birthdate) AS oldest, max(p.birthdate) AS youngest| oldest | youngest |
|---|---|
1985-04-04 |
1988-08-08 |
Next Steps
We have seen how to use the EXISTS {} clause to write complex filtering patterns, and the CALL {} clause to execute result returning subqueries.
In the next section, we will learn how to use aggregation in Cypher and how to do more with the return results.
Resources
|
Are you struggling?
If you need help with any of the information contained on this page, you can reach out to other members of our community.
You can ask questions in the Cypher category on the Neo4j Community Site.
|
Was this page helpful?