Updating with Cypher
Building on the Cypher Basics I guide, this guide covers more introductory concepts of Cypher, Neo4j’s graph query language. Upon finishing this guide, you should be able to read and write Cypher queries for standard CRUD operations.
You should be familiar with graph database concepts and the property graph model. This guide is a continuation of the Cypher Syntax section. You will need to read that guide before continuing with the current section.
Beginner
Create, Update, and Delete Operations
In the last guide, we learned how to represent nodes, relationships, labels, properties, and patterns in Cypher for read queries. This guide will add another level to your knowledge by introducing how to write create, update, and delete operations in Cypher.
While these are the standard CRUD operations, some things function a bit differently in a graph than in other types of databases. You will probably recognize some of the similarities and differences as we go along.
Inserting Data with Cypher
Adding data in Cypher works very similarly to any other data access language’s insert statement.
Instead of the INSERT keyword like in SQL, though, Cypher uses CREATE.
You can use CREATE to insert nodes, relationships, and patterns into Neo4j.
Let us look at an example that we used in our last guide.
To review, we had a Person node (Jennifer) who liked graphs, was friends with Michael, and worked at Neo4j.
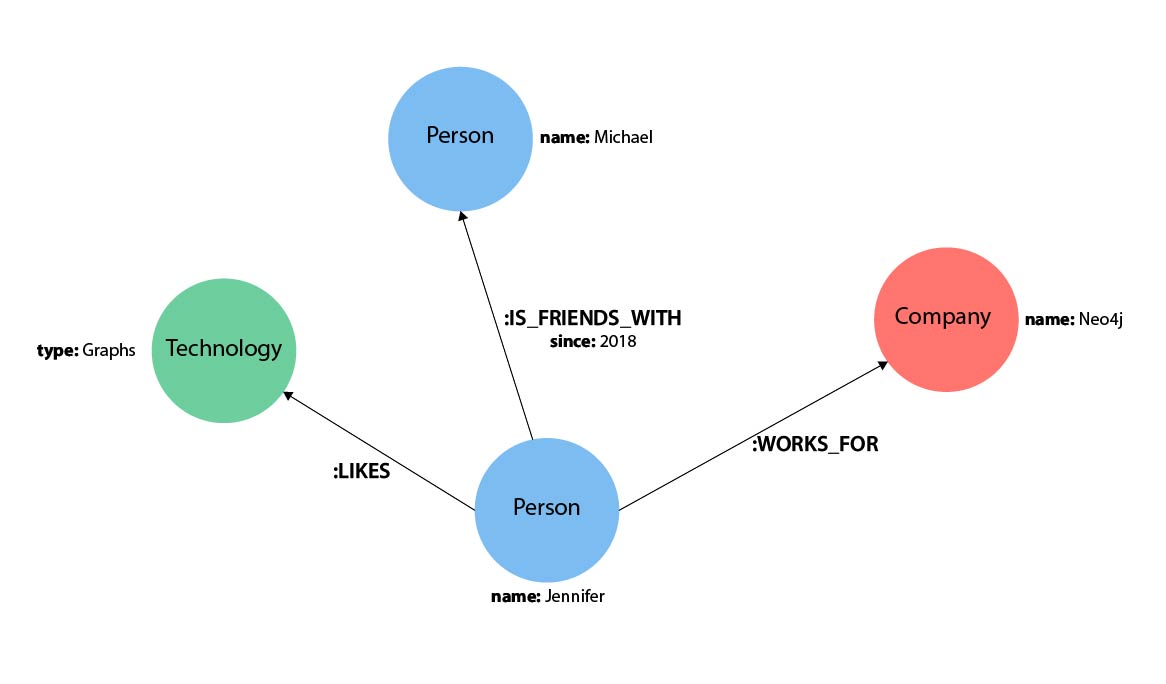
What if we wanted to add another of Jennifer’s friends to the graph? We can add Jennifer’s friend Mark using the Cypher statement below.
CREATE (friend:Person {name: 'Mark'})
RETURN friend|
It is not required to include the |
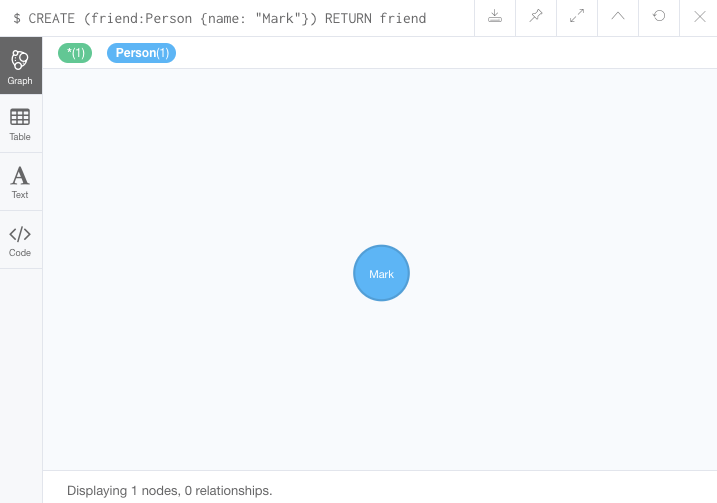
Great! Now we added Mark to the database.
However, Mark is all alone with no relationships because we just created his node and did not specify any connections.
We know he is friends with Jennifer (same as Michael), so we can add a new IS_FRIENDS_WITH relationship between the existing Jennifer and Mark nodes.
The Cypher to do that would look like this.
MATCH (jennifer:Person {name: 'Jennifer'})
MATCH (mark:Person {name: 'Mark'})
CREATE (jennifer)-[rel:IS_FRIENDS_WITH]->(mark)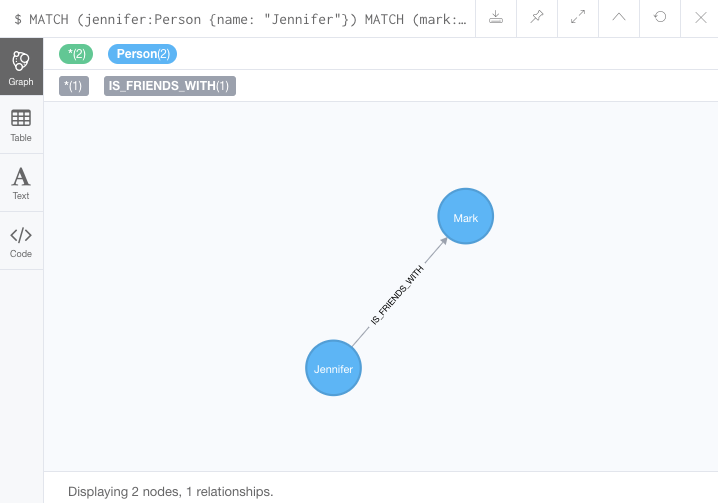
Notice that we run two MATCH queries before we create a relationship between the nodes.
Why is that?
The reason we do a match for Jennifer’s node and a match for Mark’s node first is because the CREATE keyword does a blind insert and will create the entire pattern, regardless if it already exists in the database.
This means that running the Cypher statement below will insert duplicate Jennifer and Mark nodes. To avoid this, our previous query first found the existing nodes, and then created a new relationship between them.
//this query will create duplicate nodes for Mark and Jennifer
CREATE (j:Person {name: 'Jennifer'})-[rel:IS_FRIENDS_WITH]->(m:Person {name: 'Mark'})|
We will learn a few ways to ensure unique inserts and to maintain data integrity, so do not worry about how to do that just yet. |
Updating Data with Cypher
Maybe you already have a node or relationship in the data, but you want to modify its properties.
You can do this by matching the pattern you want to find and using the SET keyword to add, remove, or update properties.
Using our example thus far, we could update Jennifer’s node to add her birthday.
The next Cypher statement shows how to do this.
First, we need to find our existing node for Jennifer.
Next, we use SET to create the new property (with syntax variable.property) and set its value.
Finally, we can return Jennifer’s node to ensure that the information was updated correctly.
MATCH (p:Person {name: 'Jennifer'})
SET p.birthdate = date('1980-01-01')
RETURN p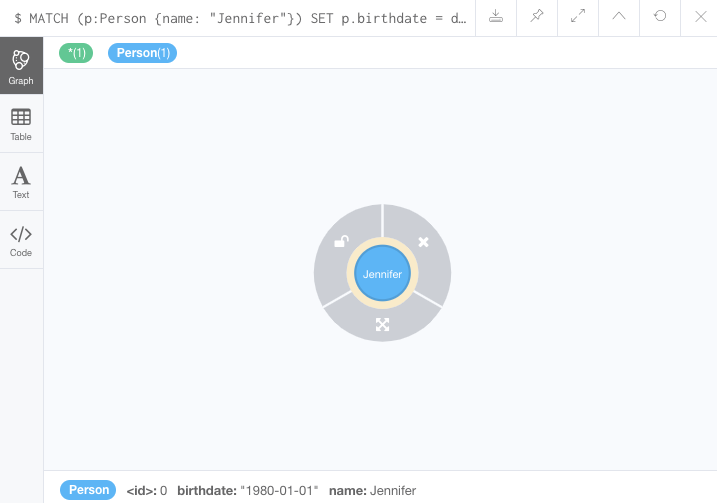
|
For more information on using |
If we now wanted to change her birthday, we could use the same query above to find Jennifer’s node again and put a different date in the SET clause.
We could also update Jennifer’s WORKS_FOR relationship with her company to include the year that she started working there.
To do this, you can use similar syntax as above for updating nodes.
MATCH (:Person {name: 'Jennifer'})-[rel:WORKS_FOR]-(:Company {name: 'Neo4j'})
SET rel.startYear = date({year: 2018})
RETURN rel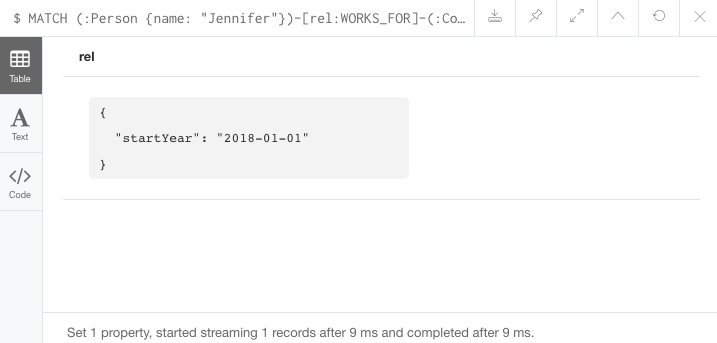
|
If we wanted to return a graph view on the above query, we could add variables to the nodes for |
Deleting Data with Cypher
Another operation for us to cover is how to delete data in Cypher.
For this operation, Cypher uses the DELETE keyword for deleting nodes and relationships.
It is very similar to deleting data in other languages like SQL, with one exception.
Because Neo4j is ACID-compliant, you cannot delete a node if it still has relationships. If you could do that, then you might end up with a relationship pointing to nothing and an incomplete graph. We will walk through how to delete a disconnected node, a relationship, as well as a node that still has relationships.
Delete a Relationship
To delete a relationship, you need to find the start and end nodes for the relationship you want to delete and then use the DELETE keyword, as shown in the statement below.
Let us go ahead and delete the IS_FRIENDS_WITH relationship between Jennifer and Mark for now.
We will add this relationship back in a later exercise.
MATCH (j:Person {name: 'Jennifer'})-[r:IS_FRIENDS_WITH]->(m:Person {name: 'Mark'})
DELETE r
Delete a Node
To delete a node that does not have any relationships, you need to find the node you want to delete and then use the DELETE keyword, just as we did for the relationship above.
We can delete Mark’s node for now and add him back in a later exercise.
MATCH (m:Person {name: 'Mark'})
DELETE m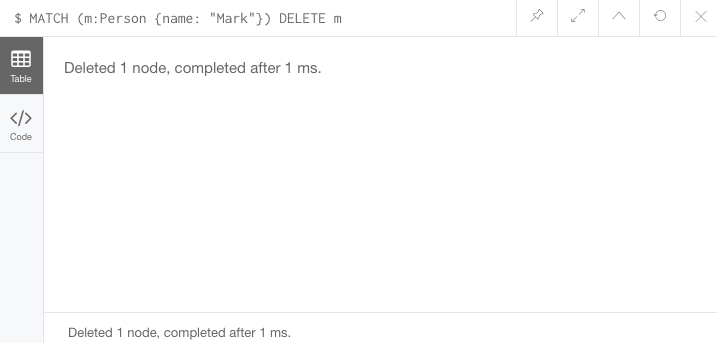
Delete a Node and Relationship
Instead of running the last two queries to delete the IS_FRIENDS_WITH relationship and the Person node for Mark, we can actually run a single statement to delete the node and relationship at the same time.
As we mentioned above, Neo4j is ACID-compliant so it doesn’t allow us to delete a node if it still has relationships.
Using the DETACH DELETE syntax tells Cypher to delete any relationships the node has, as well as remove the node itself.
The statement would look like the code below.
First, we find Mark’s node in the database.
Then, the DETACH DELETE line removes any existing relationships Mark has before also deleting his node.
MATCH (m:Person {name: 'Mark'})
DETACH DELETE mDelete Properties
You can also remove properties, but instead of using the DELETE keyword, we can use a couple of other approaches.
The first option is to use REMOVE on the property.
This tells Neo4j that you want to remove the property from the node entirely and no longer store it.
The second option is to use the SET keyword from earlier to set the property value to null.
Unlike other database models, Neo4j does not store null values.
Instead, it only stores properties and values that are meaningful to your data.
This means that you can have different types and amounts of properties on various nodes and relationships in your graph.
To show you both options, let us look at the code for each.
//delete property using REMOVE keyword
MATCH (n:Person {name: 'Jennifer'})
REMOVE n.birthdate
//delete property with SET to null value
MATCH (n:Person {name: 'Jennifer'})
SET n.birthdate = null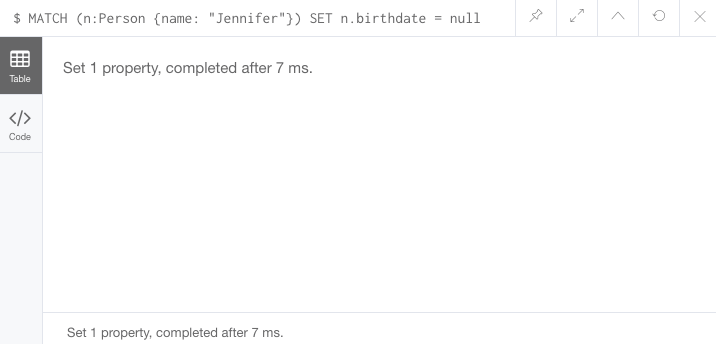
Avoiding Duplicate Data Using MERGE
We briefly mentioned in an earlier section that there are some ways in Cypher to avoid creating duplicate data.
One of those ways is by using the MERGE keyword.
MERGE does a "select-or-insert" operation that first checks if the data exists in the database.
If it exists, then Cypher returns it as is or makes any updates you specify on the existing node or relationship.
If the data does not exist, then Cypher will create it with the information you specify.
Using Merge on a Node
To start, let us look at an example of this by adding Mark back to our database using the query below.
We use MERGE to ensure that Cypher checks the database for an existing node for Mark.
Since we removed Mark’s node in the previous examples, Cypher will not find an existing match and will create the node new with the name property set to 'Mark'.
If we run the same statement again, Cypher will find an existing node this time that has the name Mark, so it will return the matched node without any changes.
MERGE (mark:Person {name: 'Mark'})
RETURN mark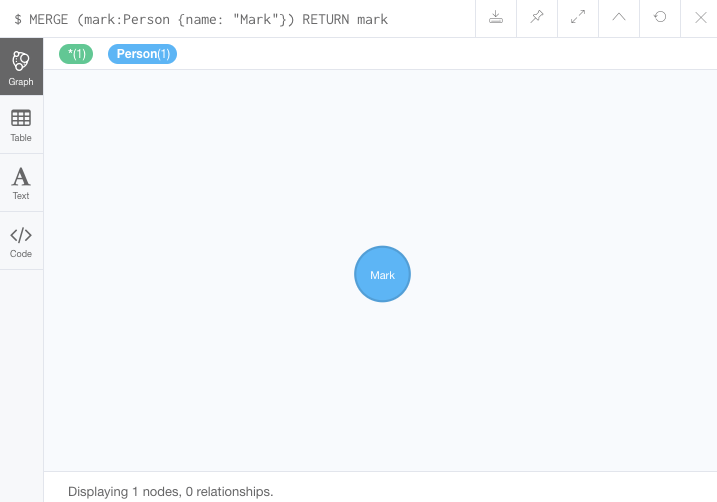
Using Merge on a Relationship
Just like we used MERGE to find or create a node in Cypher, we can do the same thing to find or create a relationship.
Let’s re-create the IS_FRIENDS_WITH relationship between Mark and Jennifer that we had in a previous example.
MATCH (j:Person {name: 'Jennifer'})
MATCH (m:Person {name: 'Mark'})
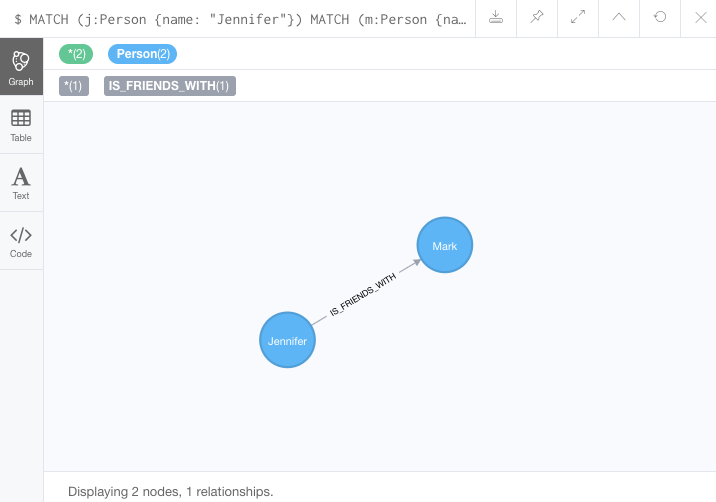
MERGE (j)-[r:IS_FRIENDS_WITH]->(m)
RETURN j, r, mNotice that we used MATCH here to find both Mark’s node and Jennifer’s node before we used MERGE to find or create the relationship.
Why did we not use a single statement?
MERGE looks for an entire pattern that you specify to see whether to return an existing one or create it new.
If the entire pattern (nodes, relationships, and any specified properties) does not exist, Cypher will create it.
Cypher never produces a partial mix of matching and creating within a pattern. To avoid a mix of match and create, you need to match any existing elements of your pattern first before doing a merge on any elements you might want to create, just as we did in the statement above.
Just for reference, the Cypher statement that will cause duplicates is below. Because this pattern (Jennifer IS_FRIENDS_WITH Mark) does not exist in the database, Cypher creates the entire pattern new - both nodes, as well as the relationship between them.
//this statement will create duplicate nodes for Mark and Jennifer
MERGE (j:Person {name: 'Jennifer'})-[r:IS_FRIENDS_WITH]->(m:Person {name: 'Mark'})
RETURN j, r, mHandling MERGE Criteria
Perhaps you want to use MERGE to ensure you do not create duplicates, but you want to initialize certain properties if the pattern is created and update other properties if it is only matched.
In this case, you can use ON CREATE or ON MATCH with the SET keyword to handle these situations.
Let us look at an example.
MERGE (m:Person {name: 'Mark'})-[r:IS_FRIENDS_WITH]-(j:Person {name:'Jennifer'})
ON CREATE SET r.since = date('2018-03-01')
ON MATCH SET r.updated = date()
RETURN m, r, jNext Steps
Now that you have learned how to write create, read, update, and delete statement in Cypher, you can interact with data to get it into and out of Neo4j in a variety of ways. The next guide will show you how to handle filtering in Neo4j to return results with various criteria and to run fuzzy searches using ranges and partial values.
Resources
|
Are you struggling?
If you need help with any of the information contained on this page, you can reach out to other members of our community.
You can ask questions in the Cypher category on the Neo4j Community Site.
|
Was this page helpful?