Guide: Example Datasets
This Guide introduces different example datasets for Neo4j and demonstrates how to import and explore them.
You should be comfortable installing Neo4j (Desktop, Docker) or using an instance in the cloud (AuraDB, Sandbox).
Intermediate
Datasets
For getting started with using Neo4j it’s helpful to use example datasets relevant to your domain and use-cases. For each we want to provide a description, the graph model and some use-case queries.
| Have fun, and provide us feedback for this page or create a GitHub issue in the linked repositories. |
Built-In Examples
Neo4j Browser comes with two built-in examples, which you can create and explore using interactive slideshows.
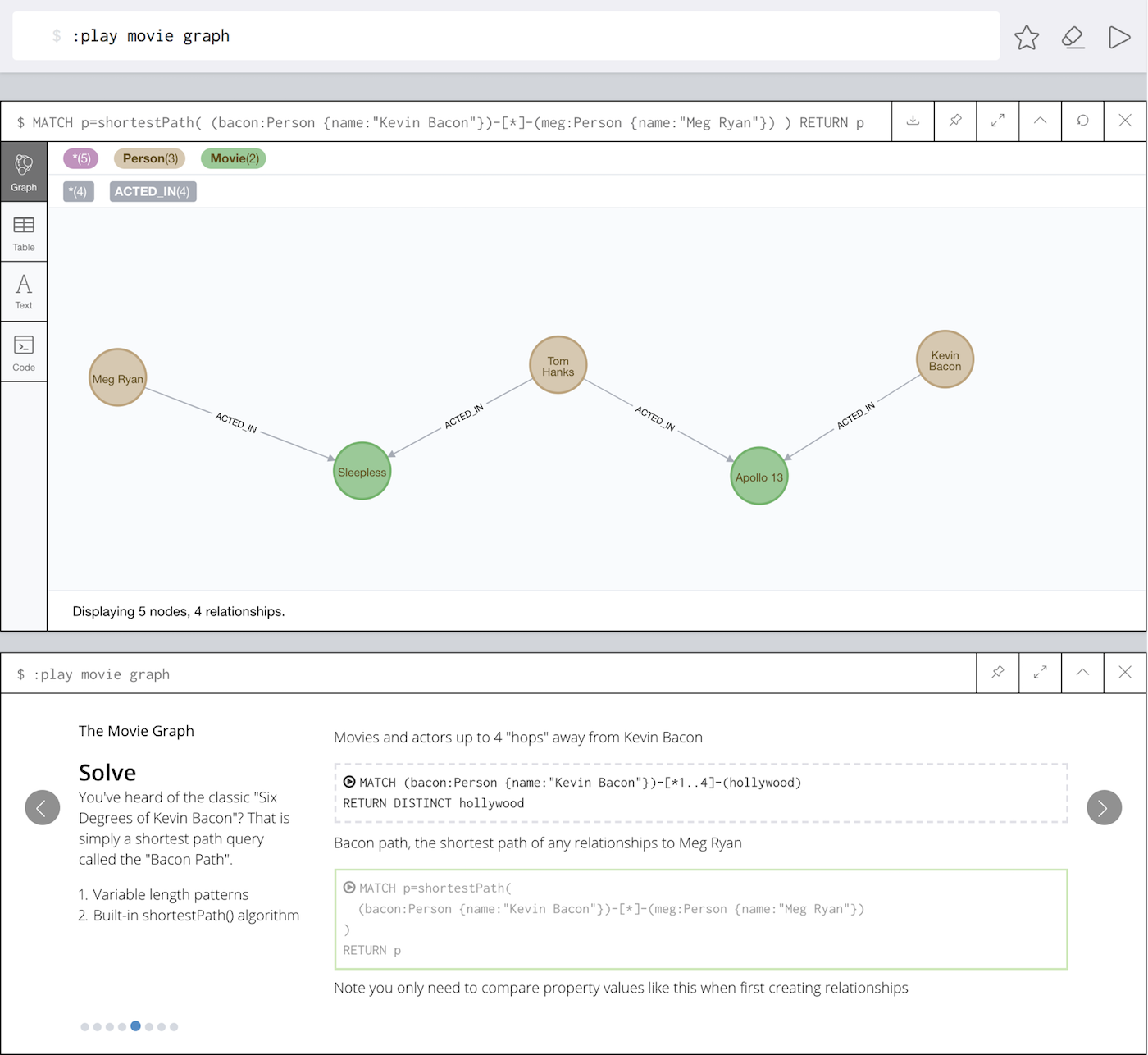
The "Movies" example, is launched via the :play movie-graph command and contains a small graph of movies and people related to those movies as actors, directors, producers etc.
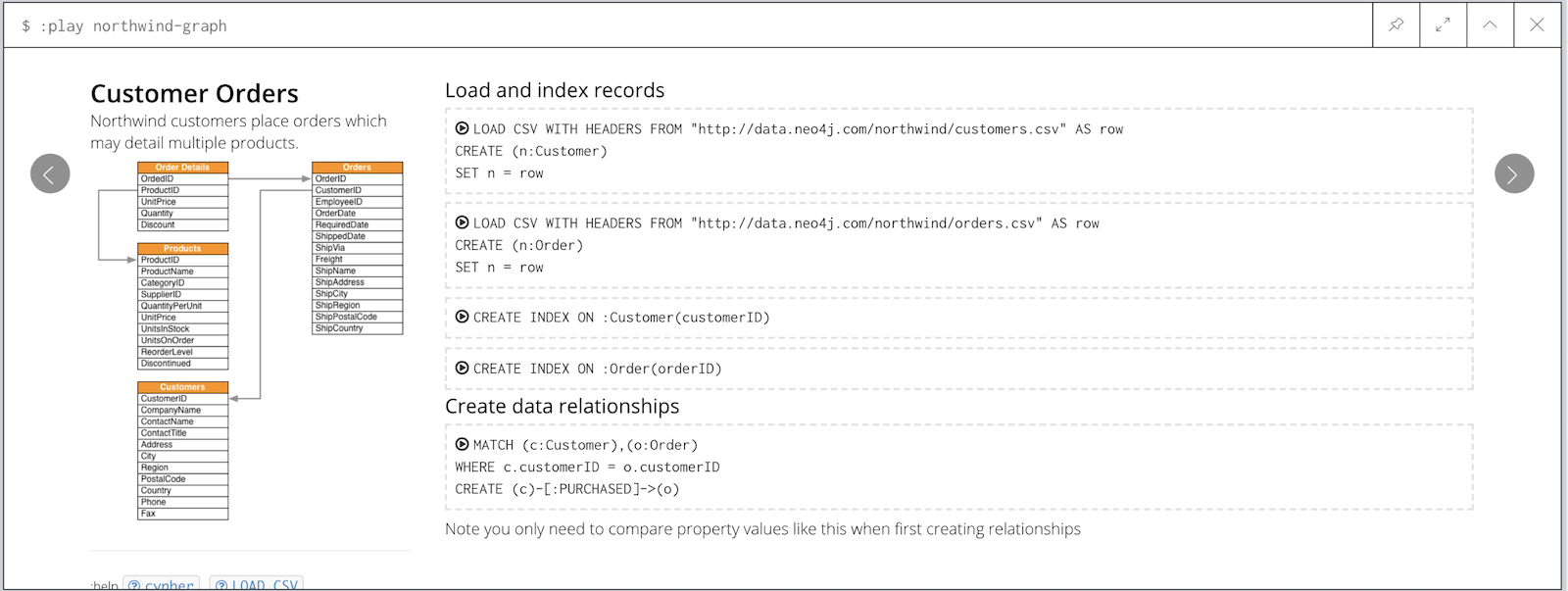
The "Northwind" example, is run via :play northwind-graph and contains an traditional retail-system with products, orders, customers, suppliers and employees.
It walks you through the import of the data and incrementally complex queries using the available data.
Neo4j Sandboxes
To explore a wide variety of datasets in an online setup without a local installation, you can use the Neo4j sandbox.
Each sandbox is available for at least 3 days after creation and can also be remotely accessed from applications using any Neo4j driver.
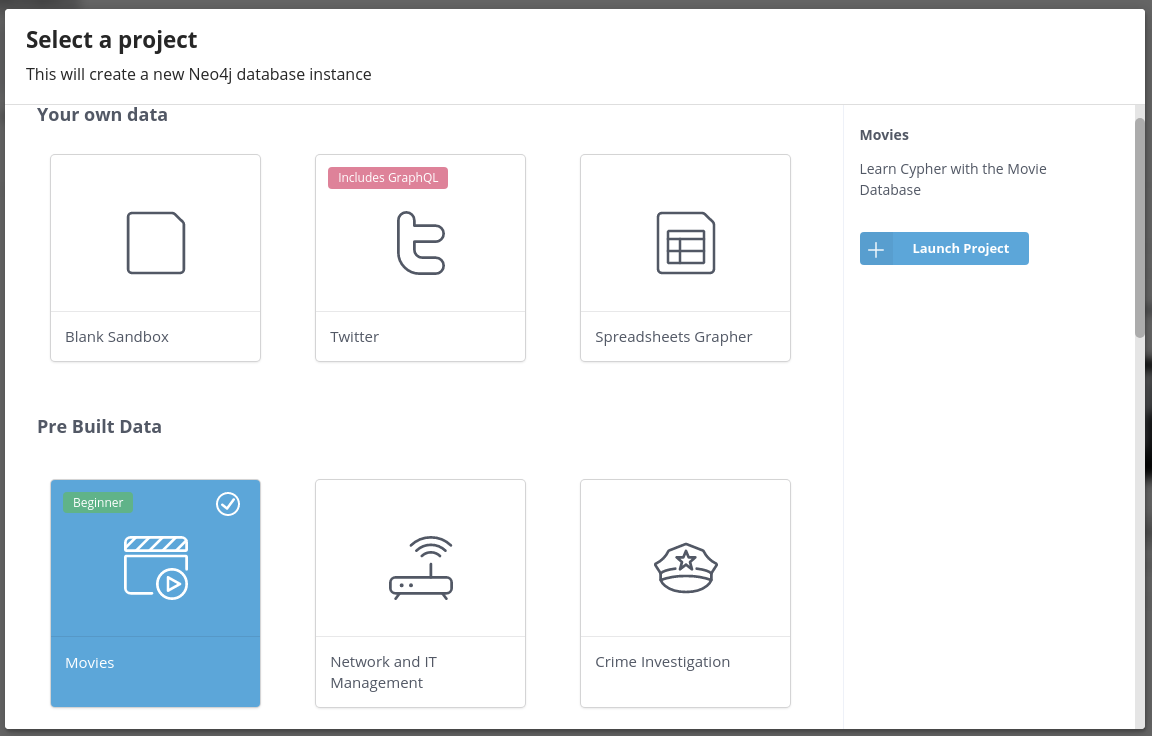
Except for the "blank" sandbox, all other sandboxes come prepopulated with the domain data and focus on use-case specific queries.
All Sandboxes provide access to Neo4j Browser, Neo4j Bloom, APOC, Graph Data Science, neosemantics (n10s) and a GraphQL integration.
Sandbox Dataset GitHub Repositories
The data, browser guide, code examples (JavaScript, Java, Python, Go, C#), Cypher queries, Bloom perspectives for each Sandbox are all available in GitHub repositories
The use-cases range from
-
social networks optionally using your own Twitter account (Repo).
Neo4j Dataset Demo server
Access Information
This server host a number of datasets with read-only access for public use. The username and password for that read-only user is the same as the datbase name.
For instance for recommendations database the username is recommendations and password is recommendations too.
The server URL is: https://demo.neo4jlabs.com:7473
Hosted Databases
You can open any of these databases by just clicking on the link, just need to copy the username as the password too.
Feedback
If you have feedback for the demo server drop us a message on Discord or create a GitHub issue.
If you want to learn more about Neo4j, check out our developer site
Other Guide Examples
Other examples that you can quickly run within your own Neo4j Browser are:
-
:play gotGame of Thrones Interactions -
:play nasaNASA knowledge graph example -
:play ukcompaniesUK company registration, property ownership, political donations -
:play stackoverflowStack Overflow users, tags and Q&A data -
:play recipesBBC Good Foods recipe data -
:play listingsAirbnb listings data -
:play football_transfersFootball (Soccer) transfer data
Graph Gallery
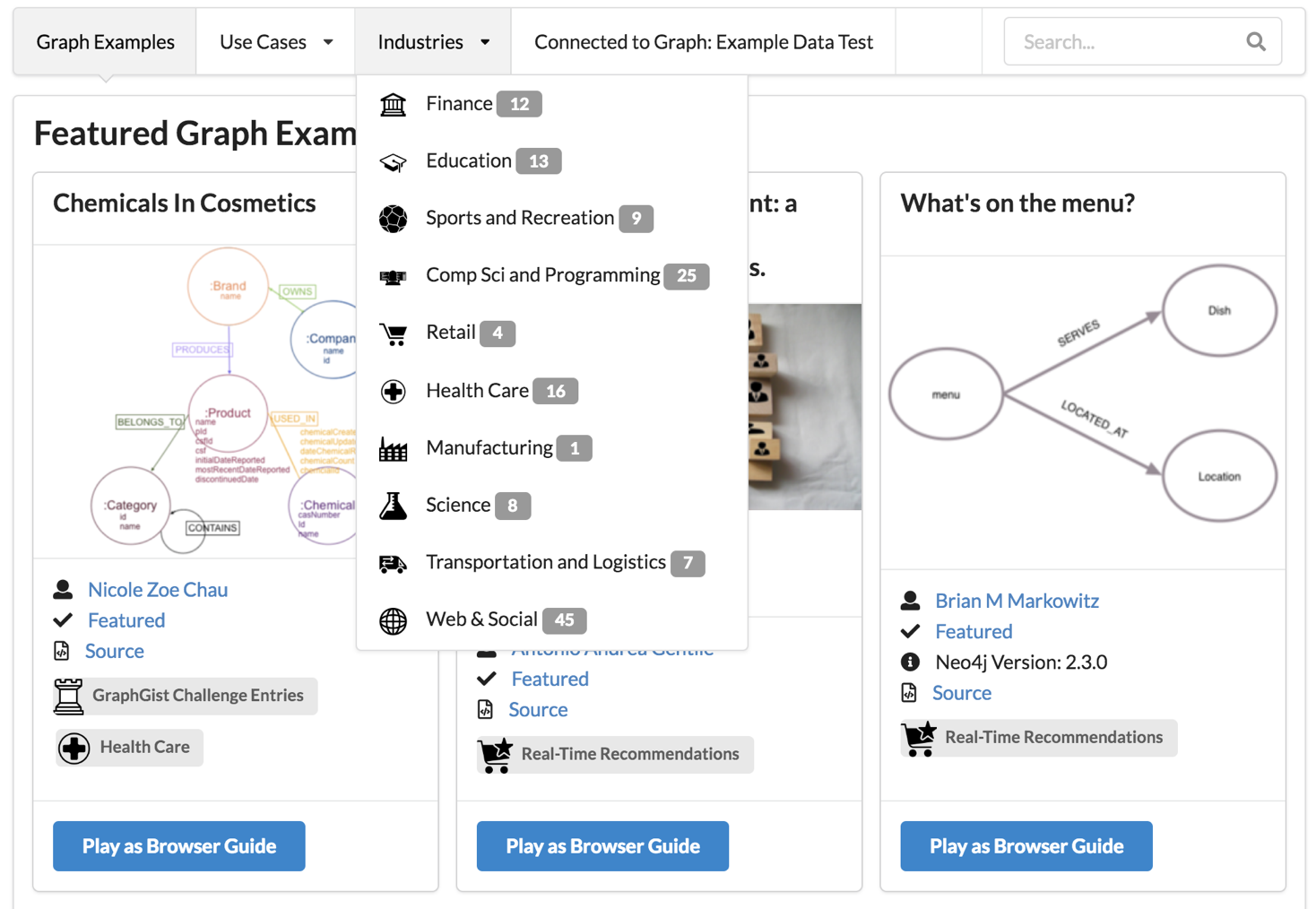
Even broader is the selection of graph examples that have been provided by Neo4j users.
| Disclaimer: These examples are not curated and might not always represent the best graph data model. |
You can find a featured selection grouped by industry and use case at https://neo4j.com/graphgists

Those examples are presented in a more long-form style that also discusses data modeling and use an temporary Neo4j store in the background.
To execute these examples within your Neo4j Desktop, install the "Graph Gallery" app from: https://install.graphapp.io
Then you can search and browse all available examples locally and run them against your local databases.
If you want to submit your own graph data model example, please head to https://portal.graphgist.org to have a look at even more (non-featured) examples and create your own entries.
Means of Data Import
Loading Data from Source Data
The most reliable way to get a dataset into Neo4j is to import it from the raw sources. Then you are independent of database versions, which you otherwise might have to upgrade. That’s why we provided raw data (CSV, JSON, XML) for several of the datasets, accompanied by import scripts in Cypher.
You could run the Cypher script using a command-line client like cypher-shell.
./bin/cypher-shell -u neo4j -p "password" -f import-file.cypherYou can also drag and drop or paste the script into Neo4j Browser (check that "multi-statement editor" is enabled in the settings) and run it from there.
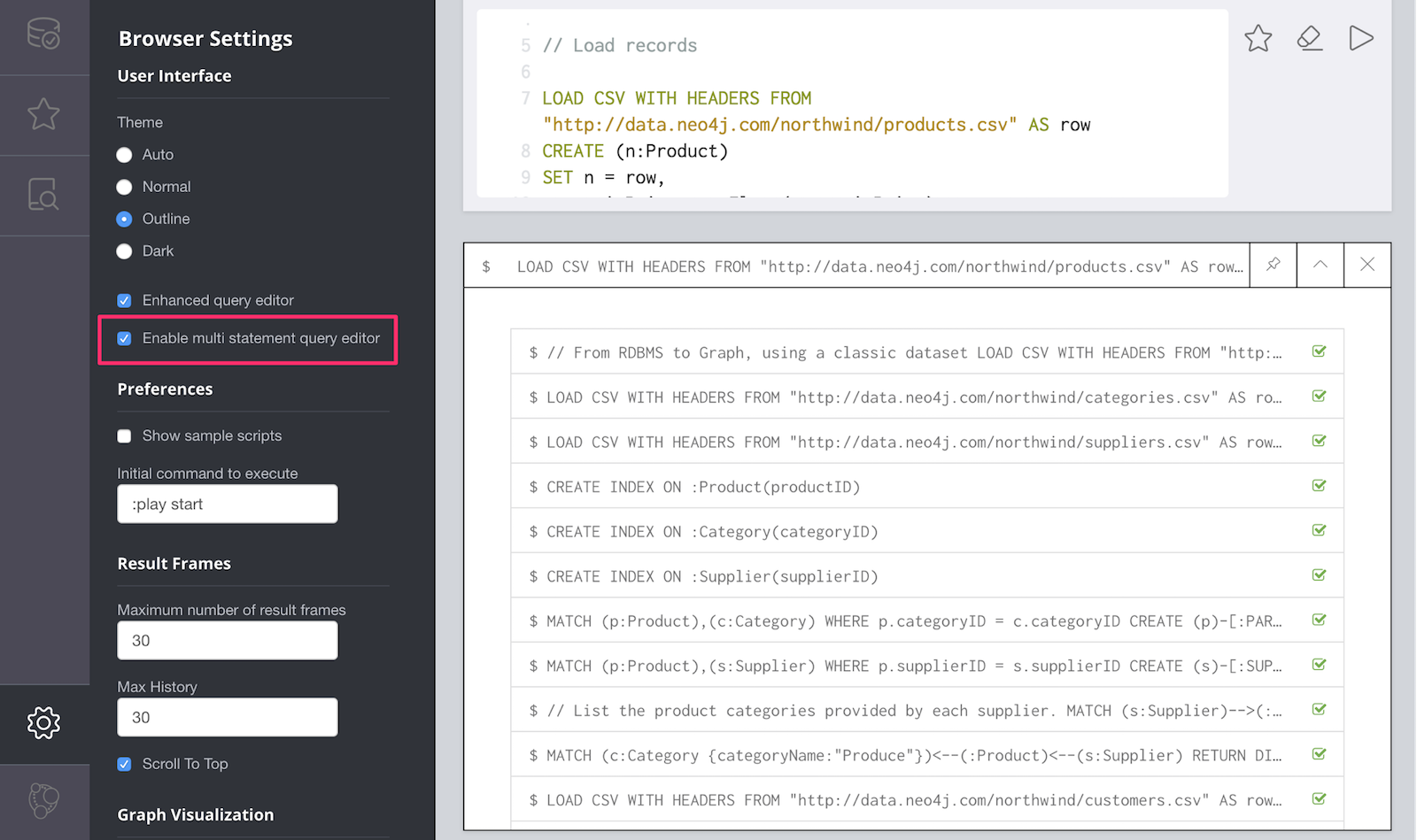
CSV data can be imported using either LOAD CSV clause in Cypher or neo4j-admin import for initial bulk imports of large datasets.
For loading JSON, XML, XLS etc. you need to have the APOC utility library installed, which comes with a number of procedures for importing data also from other databases.
Using a dump of a Neo4j database
Other datasets are provided as dump of a Neo4j datastore.
-
Please stop your Neo4j server
-
Then you can import the file using the
./bin/neo4j-admin load --force true --from file.dumpcommand. -
Start the Neo4j server
-
Import the file using the
./bin/neo4j-admin load --force true --from file.dump --database <dbname>command. -
Make the new database known to the system database with
CREATE DATABASE dbnamewhich will also automatically start it
The Neo4j version of some of the datasets might be older than your Neo4j version.
Then you might need to configure Neo4j to upgrade your database automatically, by setting dbms.allow_upgrade=true in your Neo4j settings, or directly in $NEO4J_HOME/conf/neo4j.conf
|
Large Data Dumps
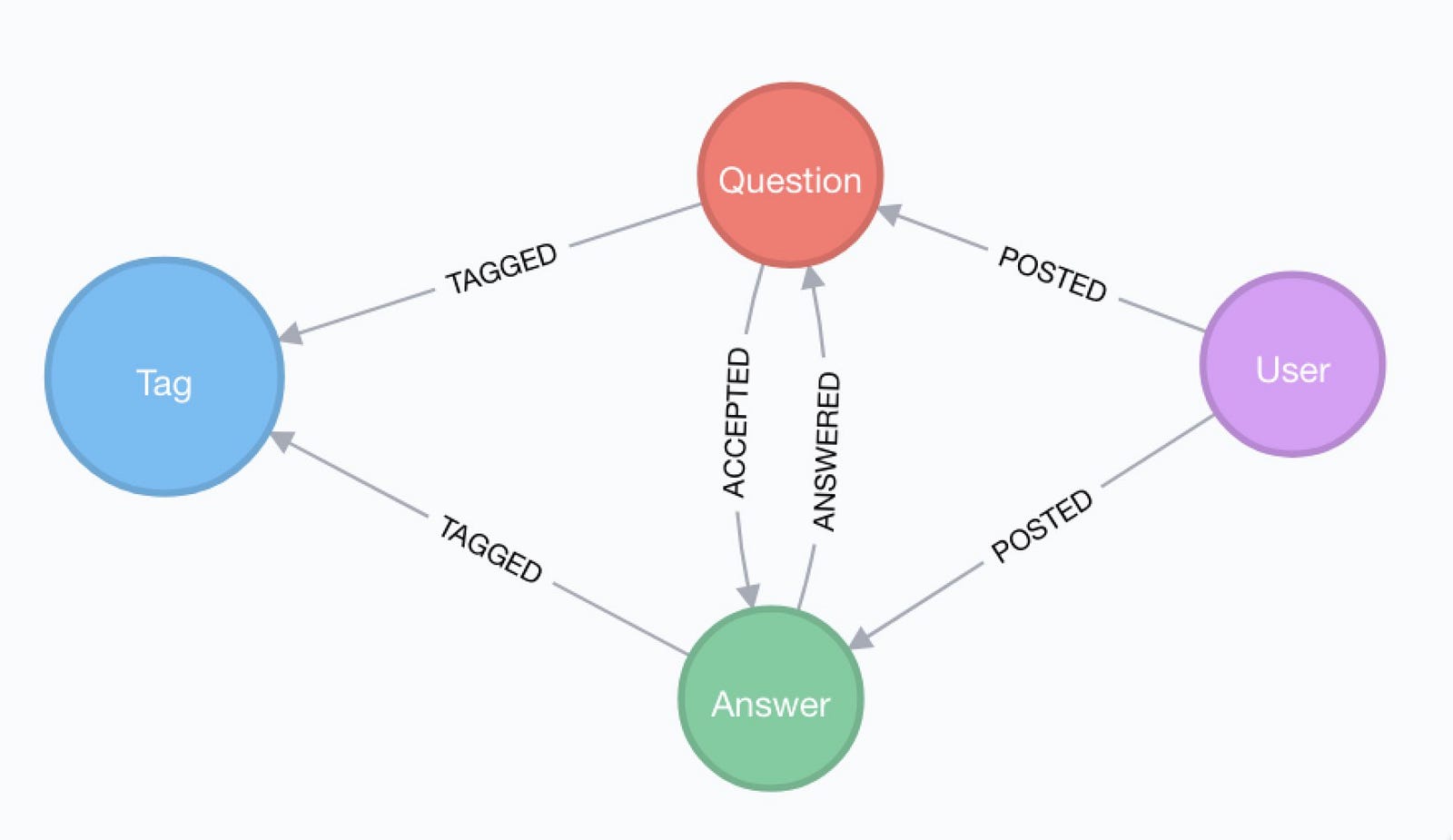
Stack Overflow
This is a graph-import of the Stack Overflow archive with 16.4M questions, 52k tags and 8.9M users (Stack Overflow Dump (6.2GB)). This graph is pretty big, for global graph queries you’d need a page-cache of 6G and heap of 16G to work with it.
Here is an article explaining the data model and some exploratory analysis we ran on the data.
The database is also available as in the Demo Server as outlined above
Articles on Neo4j Example Datasets
These are not prebuilt data-stores but existing datasets (mostly CSV) to be imported.
The linked articles and repositories also provide instructions for the import.
Was this page helpful?