Concepts: Relational to Graph
This guide explores the concepts of graph databases from a relational developer’s point of view. It aims to explain the conceptual differences between relational and graph database structures and data models. It also gives a high-level overview of how working with each database type is similar or different - from the relational and graph query languages to interacting with the database from applications.
You should be familiar with the relational database model and understand the basics of the property-graph model. It is also helpful to understand basic data modeling questions and concepts.
Beginner
Relational databases have been the work horse of software applications since the 80’s, and continue as such to this day. They store highly-structured data in tables with predetermined columns of specific types and many rows of those defined types of information. Due to the rigidity of their organization, relational databases require developers and applications to strictly structure the data used in their applications.
In relational databases, references to other rows and tables are indicated by referring to primary key attributes via foreign key columns. Joins are computed at query time by matching primary and foreign keys of all rows in the connected tables. These operations are compute-heavy and memory-intensive and have an exponential cost.
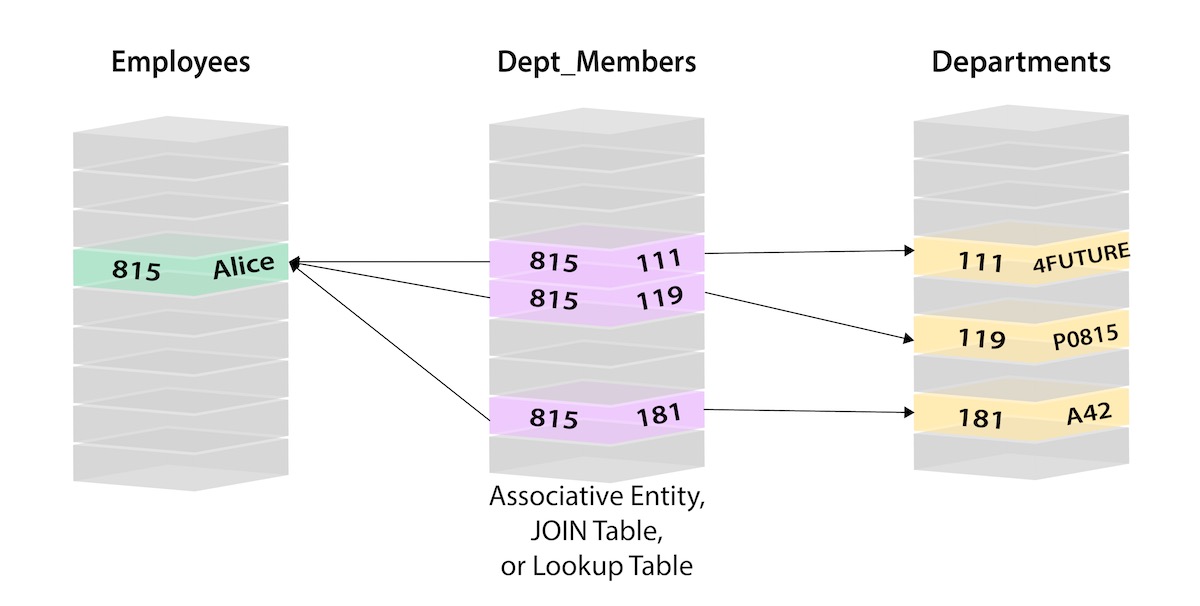
When many-to-many relationships occur in the model, you must introduce a JOIN table (or associative entity table) that holds foreign keys of both the participating tables, further increasing join operation costs. The image below shows this concept of connecting a Person (from Person table) to a Department (in Department table) by creating a Person-Department join table that contains the ID of the person in one column and the ID of the associated department in the next column.
As you can probably see, this makes understanding the connections very cumbersome because you must know the person ID and department ID values (performing additional lookups to find them) in order to know which person connects to which departments. Those types of costly join operations are often addressed by denormalizing the data to reduce the number of joins necessary, therefore breaking the data integrity of a relational database.
Although not every use case is a good fit for this stringent data model, the lack of viable alternatives and the wide support for relational databases made it difficult for alternative models to break into the mainstream. However, the NoSQL era arrived in the market, filling some needs for users and businesses, but still missing the importance of the connections between data. This is how graph databases were born. They were designed to provide the greatest advantage in the connected world we live in today.
Translating Relational Knowledge to Graphs
Unlike other database management systems, relationships are of equal importance in the graph data model to the data itself. This means we are not required to infer connections between entities using special properties such as foreign keys or out-of-band processing like map-reduce.
By assembling nodes and relationships into connected structures, graph databases enable us to build simple and sophisticated models that map closely to our problem domain. The data stays remarkably similiar to its form in the real world - small, normalized, yet richly connected entities. This allows you to query and view your data from any imaginable point of interest, supporting many different use cases.
Each node (entity or attribute) in the graph database model directly and physically contains a list of relationship records that represent the relationships to other nodes. These relationship records are organized by type and direction and may hold additional attributes. Whenever you run the equivalent of a JOIN operation, the graph database uses this list, directly accessing the connected nodes and eliminating the need for expensive search-and-match computations.
This ability to pre-materialize relationships into the database structure allows Neo4j to provide performance of several orders of magnitude above others, especially for join-heavy queries, allowing users to leverage a minutes to milliseconds advantage.
Data Model Differences
As you can probably imagine from the structural differences discussed above, the data models for relational versus graph are very different. The straightforward graph structure results in much simpler and more expressive data models than those produced using traditional relational or other NoSQL databases.
If you are used to modeling with relational databases, remember the ease and beauty of a well-designed, normalized entity-relationship diagram - a simple, easy-to-understand model you can quickly whiteboard with your colleagues and domain experts. A graph is exactly that - a clear model of the domain, focused on the use cases you want to efficiently support.
Let’s compare the two data models to show how the structure differs between relational and graph.

In the above relational example, we search the Person table on the left (potentially millions of rows) to find the user Alice and her person ID of 815. Then, we search the Person-Department table (orange middle table) to locate all the rows that reference Alice’s person ID (815). Once we retrieve the 3 relevant rows, we go to the Department table on the right to search for the actual values of the department IDs (111, 119, 181). Now we know that Alice is part of the 4Future, P0815, and A42 departments.
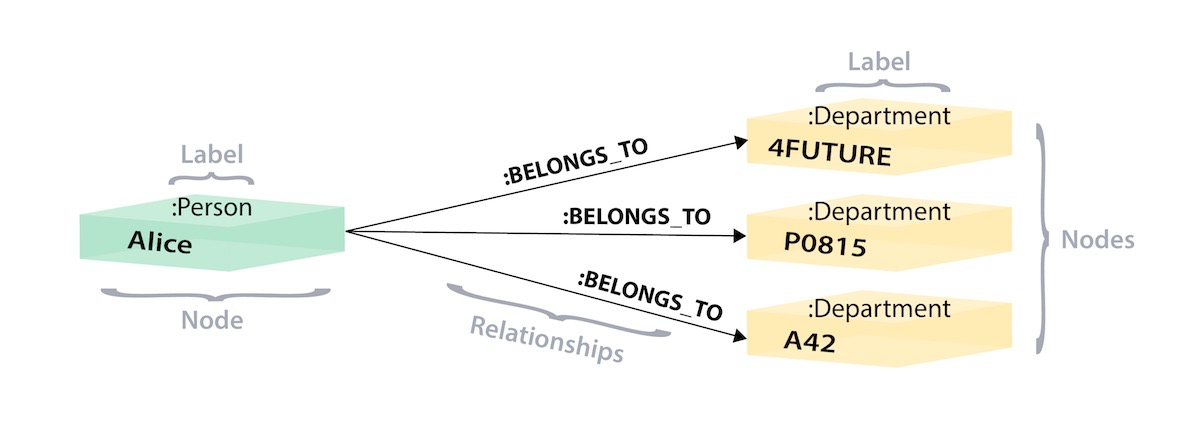
In the above graph version, we have a single node for Alice with a label of Person. Alice belongs to 3 different departments, so we create a node for each one and with a label of Department. To find out which departments Alice belongs to, we would search the graph for Alice’s node, then traverse all of the BELONGS_TO relationships from Alice to find the Department nodes she is connected to. That’s all we need - a single hop with no lookups involved.
|
More information on this topic can be found in the Data Modeling section. |
Data Storage and Retrieval
Querying relational databases is easy with SQL - a declarative query language that allows both easy ad-hoc querying in a database tool, as well as use-case-specific querying from application code. Even object-relational mappers (ORMs) use SQL under the hood to talk to the database.
Do graph databases have something similar? Yes!
Cypher, Neo4j’s declarative graph query language, is built on the basic concepts and clauses of SQL but has a lot of additional graph-specific functionality to make it easy to work with your graph model.
If you have ever tried to write a SQL statement with a large number of joins, you know that you quickly lose sight of what the query actually does because of all the technical noise in SQL syntax. In Cypher, the syntax remains concise and focused on domain components and the connections among them, expressing the pattern to find or create data more visually and clearly. Other clauses outside of the basic pattern matching look very similar to SQL, as Cypher was built on the predecessor language’s foundations.
We will cover Cypher query language syntax in an upcoming guide, but let us look at a brief example of how a SQL query differs from a Cypher query. In the organizational domain from our data modeling example above, what would a SQL statement that lists the employees in the IT Department look like, and how does it compare to the Cypher statement?
SELECT name FROM Person
LEFT JOIN Person_Department
ON Person.Id = Person_Department.PersonId
LEFT JOIN Department
ON Department.Id = Person_Department.DepartmentId
WHERE Department.name = "IT Department"MATCH (p:Person)-[:WORKS_AT]->(d:Dept)
WHERE d.name = "IT Department"
RETURN p.name|
You can find more about Cypher syntax in the upcoming guides for the Cypher Query Language and transitioning from SQL to Cypher. |
Transitioning from Relational to Graph - In Practice
If you do decide to move your data from a relational to a graph database, the steps to transition your applications to use Neo4j are actually quite simple. You can connect to Neo4j with a driver or connector library designed for your stack or programing language, just as you can with other databases. Thanks to Neo4j and its community, there are Neo4j drivers that mimic existing database driver idioms and approaches for nearly any popular programing language.
For instance, the Neo4j JDBC driver would be used like this to query the database for John’s departments:
Connection con = DriverManager.getConnection("jdbc:neo4j://localhost:7474/");
String query =
"MATCH (:Person {name:{1}})-[:EMPLOYEE]-(d:Department) RETURN d.name as dept";
try (PreparedStatement stmt = con.prepareStatement(QUERY)) {
stmt.setString(1,"John");
ResultSet rs = stmt.executeQuery();
while(rs.next()) {
String department = rs.getString("dept");
....
}
}|
For more information, you can visit our pages for Building Applications to see how to connect to Neo4j using different programming languages. |
Was this page helpful?