Graph Model Refactoring
Building on the Cypher Basics guides, this guide provides a worked example of changing a graph model. Upon finishing this guide, you should be able to evolve your graph model based on changing requirements.
You should be familiar with graph database concepts and the property graph model. This guide is a continuation of the concepts discussed in the previous Cypher sections. You should be familiar with MATCH, Create/Update/Delete, and Filtering concepts before walking through this guide.
Intermediate
Airports dataset
In this guide we’re going to use an airports dataset that contains connections between US airports in January 2008. We have the data in a CSV file, and this is the graph model that we’re going to import it into:
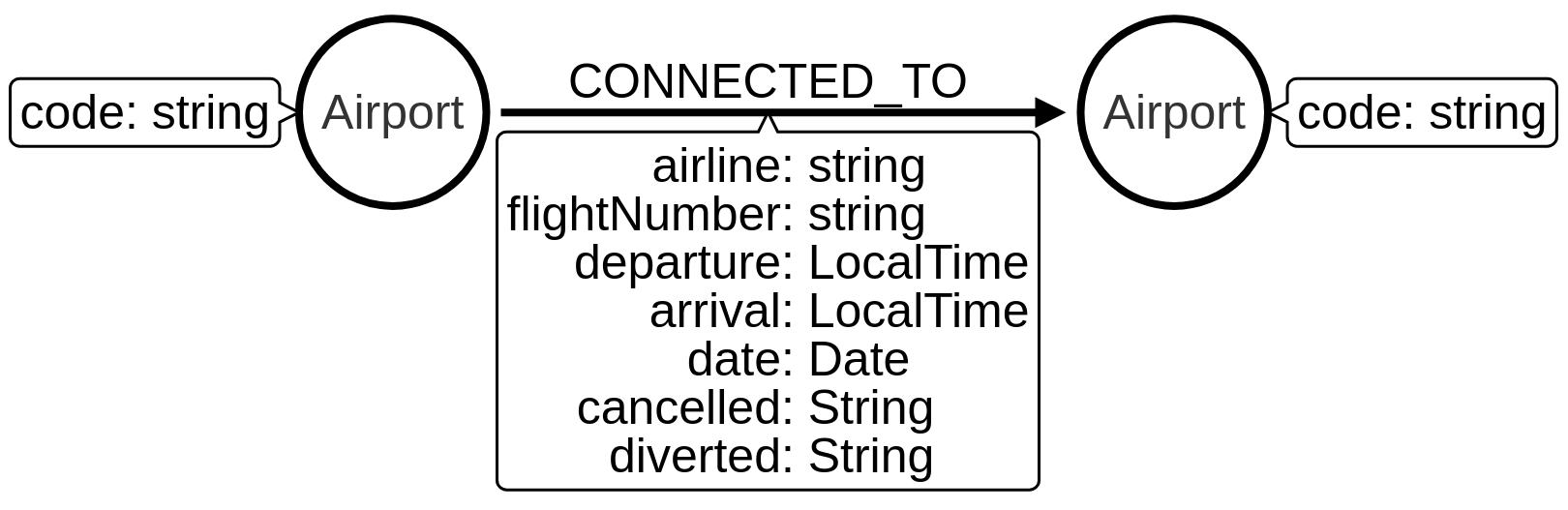
Before we import any data, we’re going to create a unique constraint on the Airport label and code property to ensure that we don’t accidentally import duplicate airports.
The following query creates this constraint:
CREATE CONSTRAINT ON (airport:Airport)
ASSERT airport.code IS UNIQUE0 rows available after 86 ms, consumed after another 0 ms. Added 1 constraints |
And the following query loads the data from a CSV file using the LOAD CSV tool:
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/neo4j-contrib/training/master/modeling/data/flights_1k.csv" AS row
MERGE (origin:Airport {code: row.Origin})
MERGE (destination:Airport {code: row.Dest})
MERGE (origin)-[connection:CONNECTED_TO {
airline: row.UniqueCarrier,
flightNumber: row.FlightNum,
date: date({year: toInteger(row.Year), month: toInteger(row.Month), day: toInteger(row.DayofMonth)}),
cancelled: row.Cancelled,
diverted: row.Diverted}]->(destination)
ON CREATE SET connection.departure = localtime(apoc.text.lpad(row.CRSDepTime, 4, "0")),
connection.arrival = localtime(apoc.text.lpad(row.CRSArrTime, 4, "0"))This query:
-
Creates a node with an
Airportlabel with acodeproperty that has a value from theOrigincolumn in the CSV file -
Creates a node with an
Airportlabel with acodeproperty that has a value from theDestcolumn in the CSV file -
Creates a relationship of type
CONNECTED_TOwith several properties based on columns in the CSV file.
If we run this query we’ll see the following output:
Added 62 labels, created 62 nodes, set 7062 properties, created 1000 relationships, completed after 376 ms. |
This model is a good starter one, but there are some improvements that we can make.
Convert property to boolean
The diverted and cancelled properties on the CONNECTED_TO relationships contain string values of 1 and 0.
Since these values are representing booleans, we can use the apoc.refactor.normalizeAsBoolean procedure to convert the values from strings to booleans.
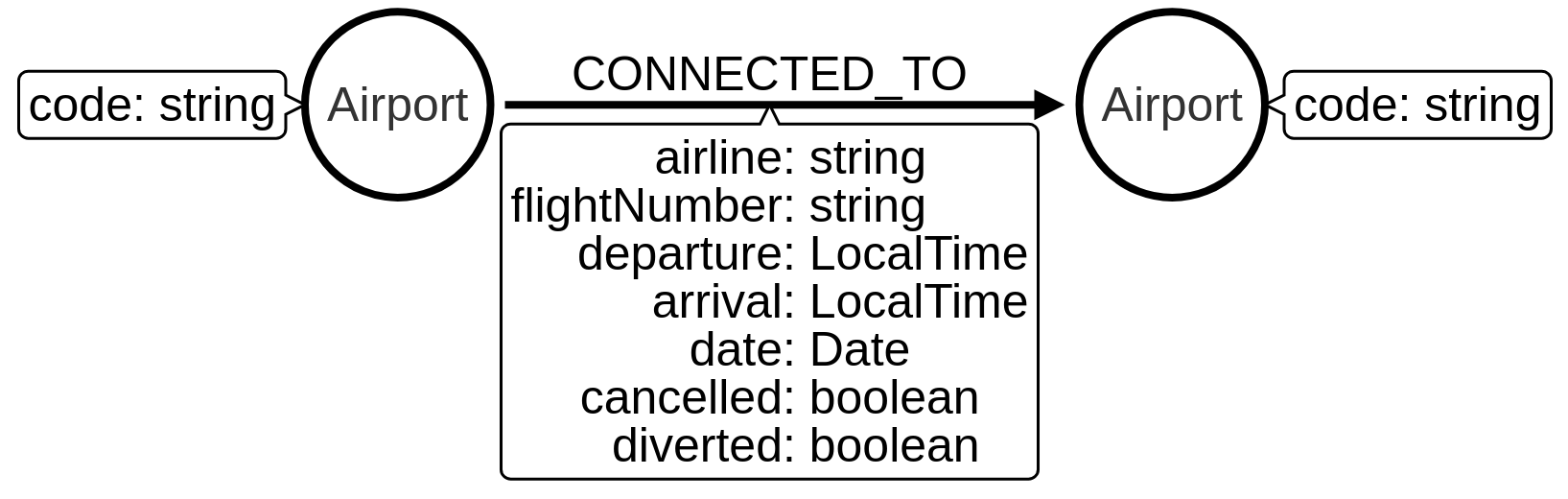
The following query does the conversion for the diverted property:
MATCH (:Airport)-[connectedTo:CONNECTED_TO]->(:Airport)
CALL apoc.refactor.normalizeAsBoolean(connectedTo, "diverted", ["1"], ["0"])
RETURN count(*)| count(*) |
|---|
1000 |
And the following query does the conversion for the cancelled property:
MATCH (origin:Airport)-[connectedTo:CONNECTED_TO]->(departure)
CALL apoc.refactor.normalizeAsBoolean(connectedTo, "cancelled", ["1"], ["0"])
RETURN count(*)| count(*) |
|---|
1000 |
If we have a lot of relationships to update, we may get an OutOfMemory exception if we try to refactor them all in one transaction.
We can therefore process them in batches using the apoc.periodic.iterate procedure.
The following query does this for the cancelled and reverted properties in the same query:
UNWIND ["cancelled", "reverted"] AS propertyToDelete
CALL apoc.periodic.iterate(
"MATCH (:Airport)-[connectedTo:CONNECTED_TO]->(:Airport) RETURN connectedTo",
"CALL apoc.refactor.normalizeAsBoolean(connectedTo, $propertyToDelete, ['1'], ['0'])
RETURN count(*)",
{params: {propertyToDelete: propertyToDelete}, batchSize: 100})
YIELD batches
RETURN propertyToDelete, batchesThe apoc.periodic.iterate procedure in this query takes in 3 parameters:
-
An outer Cypher query that finds and returns a stream of
CONNECTED_TOrelationships to be processed. -
An inner Cypher query that processes those
CONNECTED_TOrelationships, converting to boolean any values for the specified property on those relationships. It does this using theapoc.refactor.normalizeAsBooleanprocedure, which itself takes in several parameters:-
the entity on which the property exists
-
the name of the property to normalize
-
a list of values that should be considered
true -
a list of values that should be considered
false
-
-
Configuration values for the procedure, including:
-
params- parameters passed into those Cypher queries -
batchSize- controls the number of inner statements that are run within a single transaction
-
When we run this query we’ll see the following output:
| propertyToDelete | batches |
|---|---|
"cancelled" |
10 |
"reverted" |
10 |
Once we’ve done this, we can write the following query to return all cancelled connections:
MATCH (origin:Airport)-[connectedTo:CONNECTED_TO]->(destination)
WHERE connectedTo.cancelled
RETURN origin.code AS origin,
destination.code AS destination,
connectedTo.date AS date,
connectedTo.departure AS departure,
connectedTo.arrival AS arrival| origin | destination | date | departure | arrival |
|---|---|---|---|---|
"LAS" |
"OAK" |
2008-01-03 |
07:00 |
08:30 |
"LAX" |
"SFO" |
2008-01-03 |
09:05 |
10:25 |
"LAX" |
"OAK" |
2008-01-03 |
11:00 |
12:15 |
"LAX" |
"SJC" |
2008-01-03 |
19:30 |
20:35 |
"LAX" |
"SFO" |
2008-01-03 |
16:20 |
17:40 |
"MDW" |
"STL" |
2008-01-03 |
11:10 |
12:15 |
"MDW" |
"BDL" |
2008-01-03 |
08:45 |
11:40 |
"MDW" |
"DTW" |
2008-01-03 |
06:00 |
08:05 |
"MDW" |
"STL" |
2008-01-03 |
14:45 |
15:50 |
"MDW" |
"BNA" |
2008-01-03 |
19:25 |
20:45 |
"OAK" |
"BUR" |
2008-01-03 |
13:10 |
14:15 |
"OAK" |
"BUR" |
2008-01-03 |
17:05 |
18:10 |
Create node from relationship
Next, imagine that we want to write a query that finds a specific flight.
This is quite difficult with our existing model because flights are represented as relationships.
We can evolve our model to create a Flight node from the properties stored on the CONNECTED_TO relationship.
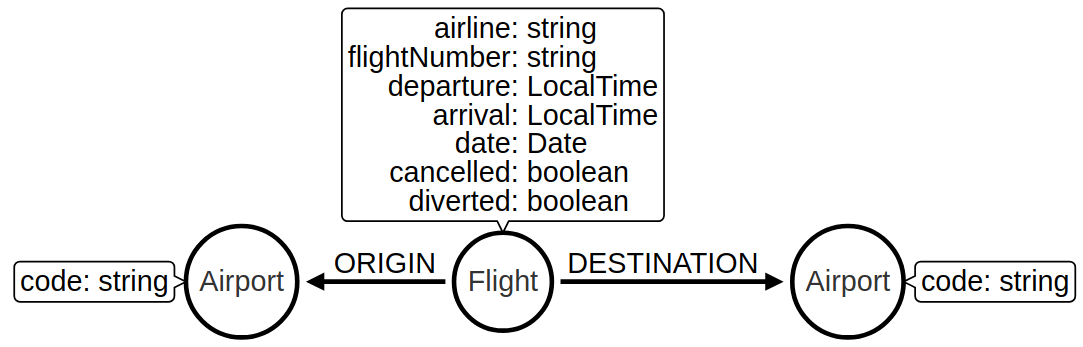
The following query does this refactoring:
CALL apoc.periodic.iterate(
"MATCH (origin:Airport)-[connected:CONNECTED_TO]->(destination:Airport) RETURN origin, connected, destination",
"CREATE (flight:Flight {
date: connected.date,
airline: connected.airline,
number: connected.flightNumber,
departure: connected.departure,
arrival: connected.arrival,
cancelled: connected.cancelled,
diverted: connected.diverted
})
MERGE (origin)<-[:ORIGIN]-(flight)
MERGE (flight)-[:DESTINATION]->(destination)
DELETE connected",
{batchSize: 100})As with our previous query, this query uses the apoc.periodic.iterate procedure so that we can do the refactoring in batches rather than within a single transaction.
The procedure takes in 3 parameters:
-
An outer Cypher query that finds and returns a stream of
CONNECTED_TOrelationships, and origin and destination airports that need to be processed. -
An inner Cypher query that processes those entities, creating a node with the label
Flightand creating relationships from that node to the origin and destination airports. -
batchSizeconfiguration, which sets to100the number of inner statements that are run within a single transaction.
If we execute the query we’ll see the following output:
| batches | total | timeTaken | committedOperations | failedOperations | failedBatches | retries | errorMessages | batch | operations | wasTerminated |
|---|---|---|---|---|---|---|---|---|---|---|
10 |
1000 |
0 |
1000 |
0 |
0 |
0 |
{} |
{total: 10, committed: 10, failed: 0, errors: {}} |
{total: 1000, committed: 1000, failed: 0, errors: {}} |
FALSE |
We can also do this refactoring using the apoc.refactor.extractNode procedure.
CALL apoc.periodic.iterate(
"MATCH (origin:Airport)-[connected:CONNECTED_TO]->(destination:Airport)
RETURN origin, connected, destination",
"CALL apoc.refactor.extractNode([connected], ['Flight'], 'DESTINATION', 'ORIGIN')
YIELD input, output, error
RETURN input, output, error",
{batchSize: 100});This does the same as the previous query, but the outer Cypher query uses the apoc.refactor.extractNode procedure to create the Flight node and create relationships to origin and destination airports.
If we run this query we’ll see the following output:
| batches | total | timeTaken | committedOperations | failedOperations | failedBatches | retries | errorMessages | batch | operations | wasTerminated |
|---|---|---|---|---|---|---|---|---|---|---|
10 |
1000 |
0 |
1000 |
0 |
0 |
0 |
{} |
{total: 10, committed: 10, failed: 0, errors: {}} |
{total: 1000, committed: 1000, failed: 0, errors: {}} |
FALSE |
Create node from property
At the moment the airline for our flights is stored in the airline property on Flight nodes.
This means that if we wanted to return a stream of all airlines we’d need to scan through every flight and check the airline property on each of those flights.
We can make it easier, and more efficient, to write this query by creating a node with an Airline label for each airline:
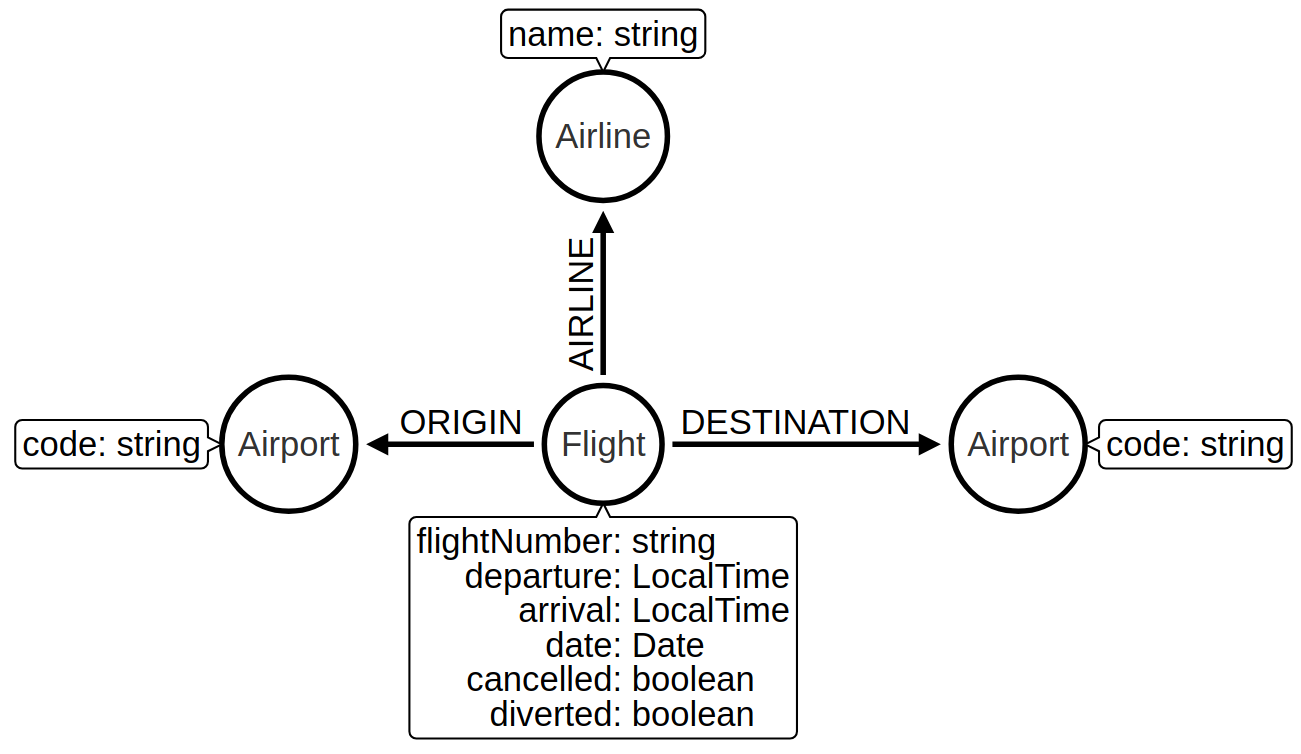
Let’s first create a constraint on the Airline label and name property so that we don’t create duplicate airline nodes:
CREATE CONSTRAINT ON (airline:Airline)
ASSERT airline.name IS UNIQUE0 rows available after 107 ms, consumed after another 0 ms. Added 1 constraints |
And now we can execute the following query to do the refactoring:
CALL apoc.periodic.iterate(
'MATCH (flight:Flight) RETURN flight',
'MERGE (airline:Airline {name:flight.airline})
MERGE (flight)-[:AIRLINE]->(airline)
REMOVE flight.airline',
{batchSize:10000, iterateList:true, parallel:false}
)Again we’re using the apoc.periodic.iterate procedure, with the following parameters:
-
An outer Cypher statement that returns a stream of
Flightnodes to be processed -
An inner Cypher statementthat processes these flight nodes, creating
Airlinenodes based on flights'airlineproperty and created anAIRLINErelationship from theFlightto theAirlinenode. We then remove theairlineproperty from theFlightnode.
If we run this query we’ll see the following output:
| batches | total | timeTaken | committedOperations | failedOperations | failedBatches | retries | errorMessages | batch | operations | wasTerminated |
|---|---|---|---|---|---|---|---|---|---|---|
1 |
1000 |
0 |
1000 |
0 |
0 |
0 |
{} |
{total: 1, committed: 1, failed: 0, errors: {}} |
{total: 1000, committed: 1000, failed: 0, errors: {}} |
FALSE |
We can then write the following query to find the airlines and number of flights involving each:
MATCH (airline:Airline)<-[:AIRLINE]-(:Flight)
RETURN airline.name AS airline, count(*) AS numberOfFlightsThis does the same as the previous query, but the outer Cypher query uses the apoc.refactor.extractNode procedure to create the Flight node and create relationships to origin and destination airports.
If we run this query we’ll see the following output:
| airline | numberOfFlights |
|---|---|
"WN" |
1000 |
Was this page helpful?