Neo4j and GraphQL
GraphQL is a specification for an API query language and a runtime for fulfilling these queries. GraphQL models application data as a graph and allows API clients to query the data as a graph irrespective of how the data is stored in the backend. While not specific to graph databases, using GraphQL with Neo4j offers several advantages including a consistent graph data model, increased developer productivity, and performance benefits.
GraphQL Overview
GraphQL is fundamentally an API query language, as explained on the GraphQL.org landing page:
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
A GraphQL query includes an entry point (a Query or Mutation field in GraphQL terminology), (optionally) arguments, and a selection set. The selection set specifies a nested traversal through the data graph as well as which fields to be returned.
Let’s look at an example GraphQL query:
{
movies(where: { title: "Matrix, The" }) {
title
plot
year
actors {
name
}
}
}The response to this query is a JSON document which matches the shape of the query - only the data requested by the client and included in the selection set is returned.
{
"data": {
"movies": [
{
"title": "Matrix, The",
"plot": "A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers.",
"year": 1999,
"actors": [
{
"name": "Hugo Weaving"
},
{
"name": "Laurence Fishburne"
},
{
"name": "Keanu Reeves"
},
{
"name": "Carrie-Anne Moss"
}
]
}
]
}
}The typical approach to building a GraphQL API involves creating GraphQL type definitions which define the data available in the API and how they are connected, and writing GraphQL resolver functions which contain the logic for "resolving" data from the data layer. These type definitions and resolver functions are then combined into an executable GraphQL schema which can be served over HTTP.
GraphQL type definitions are typically defined using the GraphQL Schema Definition Language (SDL). SDL is a language-agnostic way to define GraphQL types. The GraphQL type definitions for the example queries above would look like this in SDL:
type Movie {
title: String!
year: Int
plot: String
actors: [Person]
}
type Person {
name: String!
movies: [Movie]
}The typical approach of writing GraphQL resolver functions manually can often involve lots of boilerplate code. Fortunately, we can often leverage tools like Neo4j’s OGM and Spring Data integration when building GraphQL APIs as described in this blog post.
For further enhanced developer productivity the Neo4j GraphQL Library can be used to build GraphQL APIs backed by Neo4j with minimal code.
The Neo4j GraphQL Library

The Neo4j GraphQL Library is a JavaScript library that can be used with any JavaScript GraphQL implementation, such as Apollo Server. By mapping GraphQL type definitions to the property graph model used by Neo4j, the Neo4j GraphQL Library can generate a CRUD API backed by Neo4j. This means developers don’t even need to implement GraphQL resolver functions as the Neo4j GraphQL Library handles generating database queries from arbitrary GraphQL requests at query time.
Features of the Neo4j GraphQL Library include:
-
Auto-generated GraphQL queries and mutations based on GraphQL type definitions
-
Complex filtering, sorting, and pagination
-
Support for custom resolvers
-
A powerful GraphQL schema directive driven authorization model
-
Support for custom logic using Cypher
-
An Object Graph Mapper (OGM) based on GraphQL type definitions
Using The Neo4j GraphQL Library With Neo4j AuraDB
Let’s see how we can create a simple GraphQL API using the Neo4j GraphQL Library and Neo4j AuraDB. We’ll be creating a Node.js GraphQL API application that will use the Neo4j GraphQL Library and Apollo Server to create a GraphQL API for movies data matching our example above.
First, in a new directory we’ll create a new Node.js project:
npm init -y
And install the necessary dependencies:
npm install @neo4j/graphql neo4j-driver graphql apollo-server dotenv
Next, we’ll provision a Neo4j AuraDB instance. We’ll use the free-tier of Neo4j AuraDB so we won’t need to put in a credit card or incur any costs. Log in to Neo4j AuraDB and select "Create Free DB".
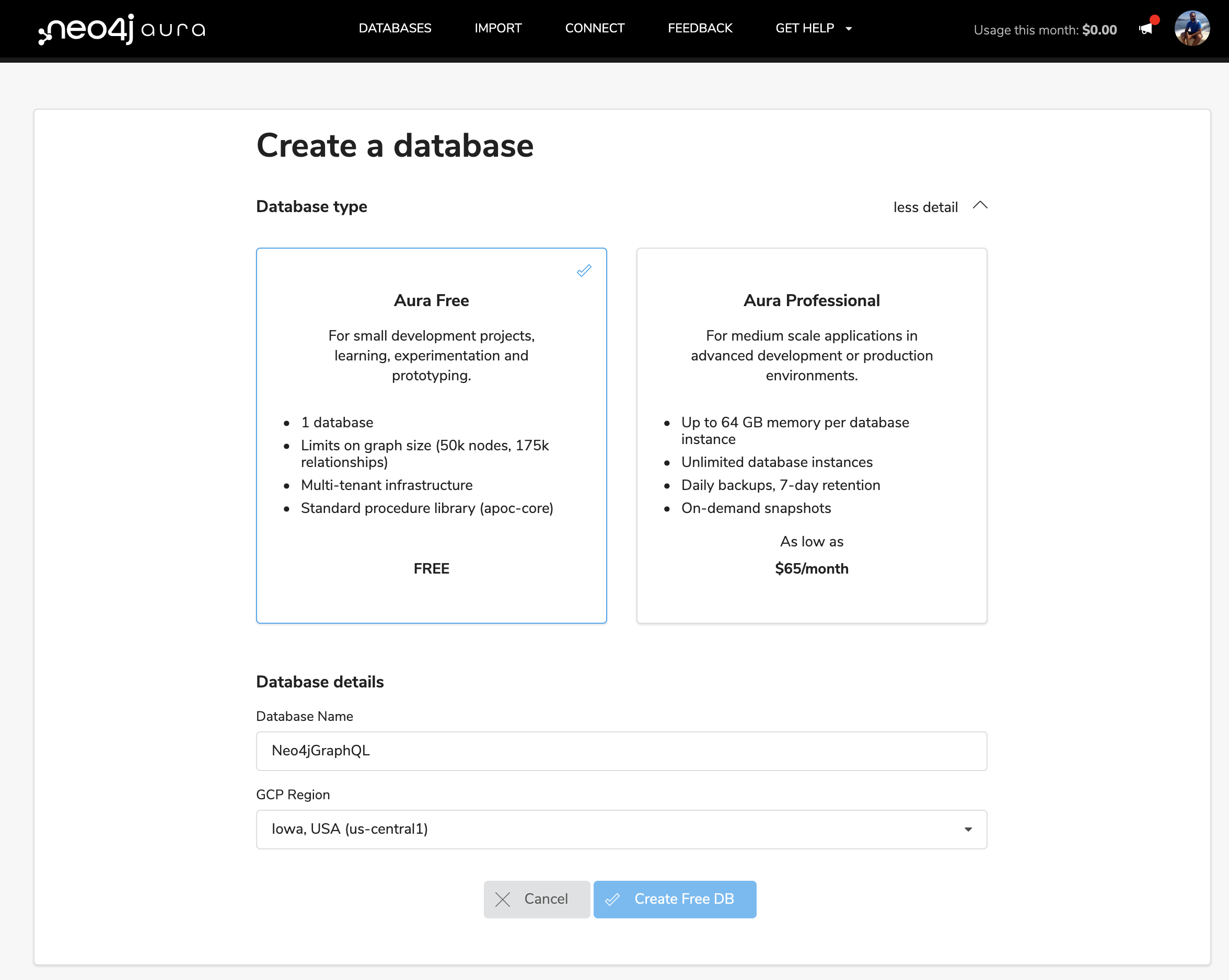
A random password for your Neo4j AuraDB instance will be generated, be sure to save this somewhere as we’ll need to use it to access our Neo4j database.
Provisioning our Neo4j AuraDB instance will take a few moments. Once it is ready in the Neo4j AuraDB dashboard we’ll see the connection URI, which we’ll need to connect our GraphQL API to Neo4j AuraDB.

Next, create a new file .env with the connection credentials for our Neo4j AuraDB instance. This will allow us to set our connection details in environment variables, without mixing these secrets in our code. Here’s what the .env file would look like given the Neo4j AuraDB credentials above, but be sure to replace with your own connection credentials for your Neo4j AuraDB instance.
.envNEO4J_USER=neo4j
NEO4J_PASSWORD=a2y4FVUlfPdDPzU5EUeEq-arDdyokWStO1m7wlkY8u4
NEO4J_URI=neo4j+s://80be87a6.databases.neo4j.ioLet’s reuse our movie and actor GraphQL type definitions from above and use them with the Neo4j GraphQL Library. We’ll also create an instance of the Neo4j JavaScript driver to connect to our Neo4j AuraDB instance, reading the credentials from our .env file as environment variables. Finally, we pass the GraphQL schema object generated by the Neo4j GraphQL Library to Apollo Server and start the GraphQL server.
index.jsconst { gql, ApolloServer } = require("apollo-server");
const { Neo4jGraphQL } = require("@neo4j/graphql");
const neo4j = require("neo4j-driver");
require("dotenv").config();
const typeDefs = gql`
type Movie {
title: String!
year: Int
plot: String
actors: [Person!]! @relationship(type: "ACTED_IN", direction: IN)
}
type Person {
name: String!
movies: [Movie!]! @relationship(type: "ACTED_IN", direction: OUT)
}
`;
const driver = neo4j.driver(
process.env.NEO4J_URI,
neo4j.auth.basic(process.env.NEO4J_USER, process.env.NEO4J_PASSWORD)
);
const neoSchema = new Neo4jGraphQL({ typeDefs, driver });
neoSchema.getSchema().then((schema) => {
const server = new ApolloServer({
schema: schema
});
server.listen().then(({ url }) => {
console.log(`GraphQL server ready on ${url}`);
});
});Notice that we added the @relationship GraphQL schema directive to our type definitions. This directive allows us to encode the relationship type and directive into our GraphQL type definitions.
We can start our Node.js GraphQL server by running node index.js and then navigate to http://localhost:4000 in a web browser to access Apollo Studio.
Create a Movie with a Mutation
Since we started a fresh Neo4j AuraDB database, let’s start by creating some data. The Neo4j GraphQL Library generates the GraphQL Mutation type used for creating data. Here, we’ll use the createMovies mutation to create a movie node and the actors connected to it in a single nested operation.
mutation {
createMovies(
input: {
title: "Matrix, The"
plot: "A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers."
year: 1999
actors: {
create: [
{ node: { name: "Hugo Weaving" } }
{ node: { name: "Laurence Fishburne" } }
{ node: { name: "Keanu Reeves" } }
{ node: { name: "Carrie-Anne Moss" } }
]
}
}
) {
movies {
title
plot
year
actors {
name
}
}
}
}The response to this GraphQL mutation will match the selection set and shows us the data created by the mutation operation.
{
"data": {
"createMovies": {
"movies": [
{
"title": "Matrix, The",
"plot": "A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers.",
"year": 1999,
"actors": [
{
"name": "Hugo Weaving"
},
{
"name": "Laurence Fishburne"
},
{
"name": "Keanu Reeves"
},
{
"name": "Carrie-Anne Moss"
}
]
}
]
}
}
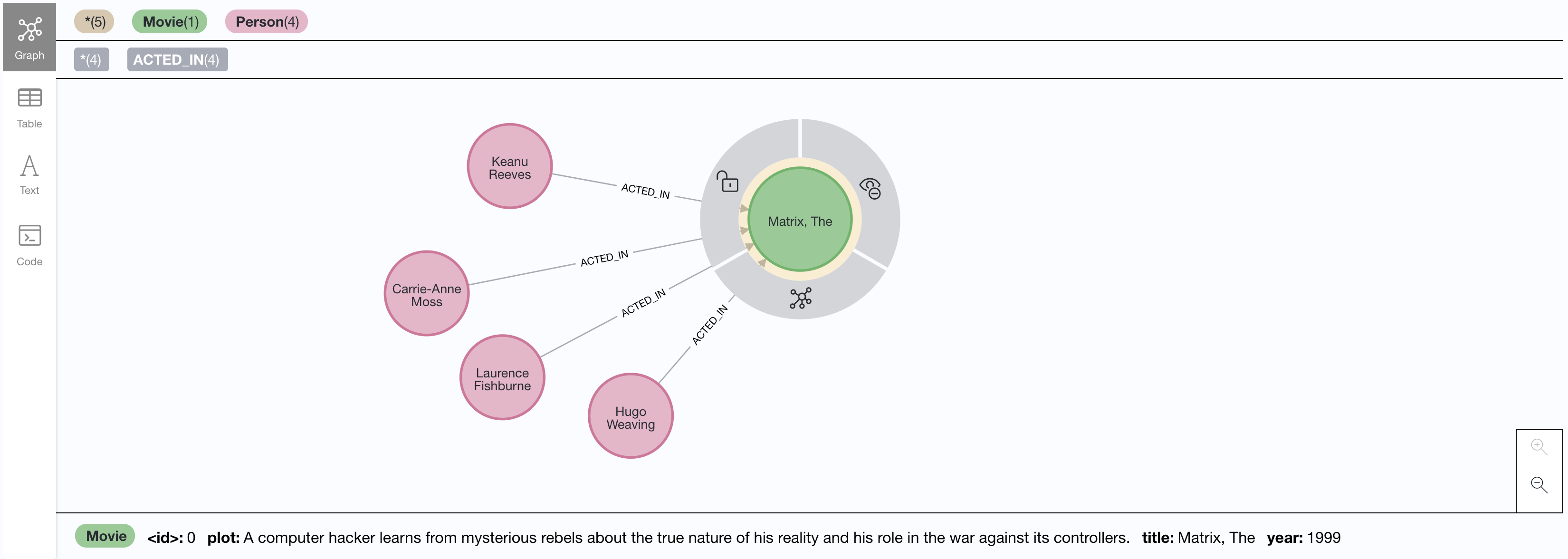
}If we check our database using Neo4j Browser we can see the data we’ve created in Neo4j:
Querying Data
The Neo4j GraphQL Library automatically creates three options for querying a type, one for querying the raw data, one for counting the data and one for aggregating the data. These auto-generated types also support advanced filtering, allowing you to control what child data is returned.
The Library will recognise the @relationship directives and add an aggregator to allow you to quickly access the count of records.
For example, we can use the actorsConnection field to retrieve a count of the number of actors in a given movi.
query {
movies(
where: { imdbRating_GT: 4} (1)
options: {limit: 2, sort:[ {imdbRating: DESC} ]} (2)
) {
title
actors (where: { name_NOT: null }) { (3)
name
born
}
actorsConnection { (4)
totalCount
}
}
}| 1 | Filter for movies with an imdbRating greater than 4 |
| 2 | Limit the number of results to 2 and sort by the imdbRating property in descending order |
| 3 | Only return actors where the name property is not null |
| 4 | Use the actorsConnection property to return a count |
{
"data": {
"movies": [
{
"title": "Band of Brothers",
"actors": [
{
"name": "Scott Grimes",
"born": null
},
{
"name": "Shane Taylor",
"born": null
},
{
"name": "Ron Livingston",
"born": "1967-06-05"
},
{
"name": "Damian Lewis",
"born": "1971-02-11"
}
],
"actorsConnection": {
"totalCount": 4
}
},
{
"title": "Civil War, The",
"actors": [
{
"name": "Sam Waterston",
"born": null
},
{
"name": "Jason Robards",
"born": null
},
{
"name": "Julie Harris",
"born": null
},
{
"name": "Morgan Freeman",
"born": "1937-06-01"
}
],
"actorsConnection": {
"totalCount": 4
}
}
]
}
}You can learn more about the Neo4j GraphQL Library in the documentation.
Was this page helpful?