Comparing SQL with Cypher
This guide teaches anyone familiar with SQL how to write the equivalent, efficient Cypher statements. We’ll use the well-known Northwind database to explain the concepts and work through the queries from simple to advanced.
You should have a basic understanding of the property graph model. Having downloaded and installed Neo4j helps you code along with the examples. Importing the data is covered in our data import guide.
Beginner
A few words about Cypher
Cypher is like SQL a declarative, textual query language, but for graphs.
It consists of clauses, keywords and expressions like predicates and functions, many of which will be familiar (like WHERE, ORDER BY, SKIP LIMIT, AND, p.unitPrice > 10).
Unlike SQL, Cypher is all about expressing graph patterns.
We added a special clause MATCH for matching those patterns in your data.
These patterns are what you would usually draw on a whiteboard, just converted into text using ASCII-art symbols.
We represent the circles of node entities with round parentheses, like this: (p:Product).
And arrows of relationships are drawn as such -->, you can add relationship-type and other information in square brackets
-[:ORDERED]->.
Bringing both together ()-->()<--() looks almost like our original diagram.
It gives us a first hint at the expressiveness of graph patterns: (cust:Customer)-[:ISSUED]->(o:Order)-[:CONTAINS]->(prod:Product).
Other highlights of Cypher are graph concepts like paths, variable length paths, shortest-path functions; the support of many functions, operations and predicates on lists and the ability to chain query parts.
You can use Cypher to update the graph structure and data and even ingest large amounts of CSV data.
With user defined procedures you can extend the language with functionality that you need but which is currently not yet available.
The full Cypher language documentation is available in the Neo4j Cypher Manual together with a complete Reference Card.
With the openCypher project, Cypher became an open effort for a modern graph query language, that is supported by several database companies. The openCypher project also provides syntax diagrams that you’re used to from SQL:
Data Model Transformation
Relational databases store data in tables with fixed structure (schema), each column having a name, type, length, constraints etc. References between tables are represented by repeating the primary key of one table as column in another as a foreign key. For many-to-many references, JOIN-tables (or link-tables) are needed as artificial construct between the connected tables.
A well normalized relational model can be directly translated into a equivalent graph model. Graph models are mostly driven by use-cases, so there will be opportunity for optimization and model evolution afterwards.
A good, well normalized Entity-Relationship diagram often already represents a decent graph model. So if you still have the original ER diagram of your database available, try to use it as a guide.
For such a sensible relational model, the transformation is not too hard. Rows of entity tables are converted into nodes and foreign-key relationships and JOIN tables into relationships.
It is important to have an good understanding of the graph model before you start to import data, then it just becomes the task of hydrating that model.
Data Import
Most relational databases allow an easy export of tables to CSV files, e.g. in Postgres COPY (SELECT * FROM customers) TO '/tmp/customers.csv' WITH CSV header;.
Those files can come from single tables, but might also represent a set of joined tables with some duplicate data.
They can be imported by using Cypher’s LOAD CSV capability, which we explain in detail in these guides:
If you are a developer you can also just connect to the relational database with your regular driver, load the data from there with SQL. And directly create the graph structure by using a Neo4j driver for your stack to send the equivalent, parametrized Cypher update statements to Neo4j.
Cypher is all about Patterns
As already mentioned, the essence of your Cypher statements are the patterns you are are interested in.
In a node pattern (variable:Label) you can use a variable and one or more labels for the node.
You can also provide attributes as key-value structure, e.g. (item:Product {name:"Chocolade"}).
For relationship-patterns like ()-[someRel:REL_TYPE]→() it is the same, only that you might chose an variable like someRel and one or more alternative relationship-types.
Like with SQL aliases you can use the variables later to refer to the nodes and relationships they represent, e.g. to access their properties or call a function on them.
Patterns are used both for querying as well as updating the graph structures.
They are usually used in the MATCH clause, but can also be treated as expressions or predicates.
That’s especially helpful when making sure that certain patterns shouldn’t exist.
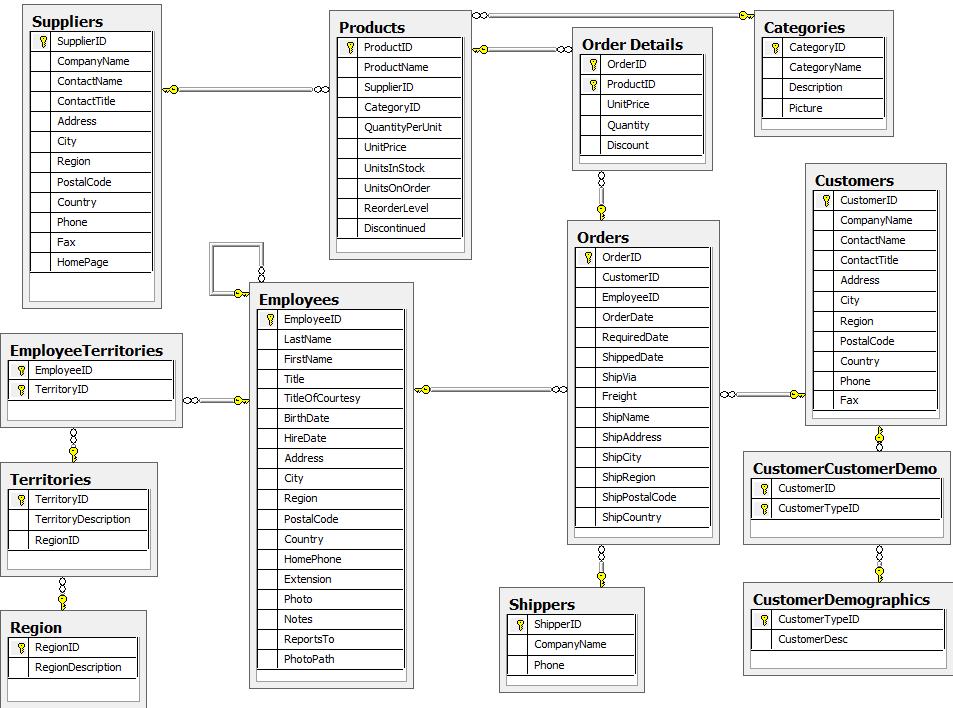
Northwind Example Model
The well known Northwind database represents the data storage of a retail application. You’ll find customers, products, orders, employees, shippers and categories as well as their interactions.
Please refer to the relational and graph model below when considering the data structures in the following queries.

Querying the Data Step by Step
The intent of this guide is to introduce Cypher by comparing it with the equivalent SQL statements, so that your existing SQL knowledge allows your to understand it immediately.
Find all Products
Select and Return Records
Easy in SQL, just select everything from the products table.
SELECT p.*
FROM products as p;Similarly in Cypher, you just match a simple pattern: all nodes with the label :Product and RETURN them.
MATCH (p:Product)
RETURN p;Field Access, Ordering and Paging
More efficient is to return only a subset of attributes, like ProductName and UnitPrice.
And while we’re on it, let’s also order by price and only return the 10 most expensive items.
SELECT p.ProductName, p.UnitPrice
FROM products as p
ORDER BY p.UnitPrice DESC
LIMIT 10;You can copy and paste the changes from SQL to Cypher, it’s thankfully unsurprising. But remember that labels, relationship-types and property-names are case sensitive in Neo4j.
MATCH (p:Product)
RETURN p.productName, p.unitPrice
ORDER BY p.unitPrice DESC
LIMIT 10;Find single Product by Name
Filter by Equality
If we only want to look at a single Product, for instance delicious Chocolade, we filter in SQL with a WHERE clause.
SELECT p.ProductName, p.UnitPrice
FROM products AS p
WHERE p.ProductName = 'Chocolade';Same in Cypher, here the WHERE belongs to the MATCH statement. Boring.
MATCH (p:Product)
WHERE p.productName = "Chocolade"
RETURN p.productName, p.unitPrice;There is a shortcut in Cypher if you match for a labeled node with a certain attribute.
MATCH (p:Product {productName:"Chocolade"})
RETURN p.productName, p.unitPrice;Indexing
If you want to match quickly by this node-label and attribute combination, it makes sense to create an index for that pair, if you haven’t during the import.
CREATE INDEX ON :Product(productName);
CREATE INDEX ON :Product(unitPrice);Filter Products
Filter by List/Range
You can also filter by multiple values.
SELECT p.ProductName, p.UnitPrice
FROM products as p
WHERE p.ProductName IN ('Chocolade','Chai');Similiarly in Cypher which has full collection support, not just the IN operator but collection functions, predicates and transformations.
MATCH (p:Product)
WHERE p.productName IN ['Chocolade','Chai']
RETURN p.productName, p.unitPrice;Filter by Multiple Numeric and Textual Predicates
Filtering can go further, let’s try to find some expensive things starting with "C".
SELECT p.ProductName, p.UnitPrice
FROM products AS p
WHERE p.ProductName LIKE 'C%' AND p.UnitPrice > 100;The LIKE operator is replaced by a STARTS WITH (there are also CONTAINS and ENDS WITH) all three of which are index supported.
MATCH (p:Product)
WHERE p.productName STARTS WITH "C" AND p.unitPrice > 100
RETURN p.productName, p.unitPrice;You can also use a regular expression, like p.productName =~ "^C.*".
Joining Products with Customers
Join Records, Distinct Results
We want to see who bought Chocolade. Let’s join the four tables together, refer to the model (ER-diagram) when you’re unsure.
SELECT DISTINCT c.CompanyName
FROM customers AS c
JOIN orders AS o ON (c.CustomerID = o.CustomerID)
JOIN order_details AS od ON (o.OrderID = od.OrderID)
JOIN products AS p ON (od.ProductID = p.ProductID)
WHERE p.ProductName = 'Chocolade';The graph model (have a look) is much simpler, as we don’t need join tables, and expressing connections as graph patterns, is easier to read too.
MATCH (p:Product {productName:"Chocolade"})<-[:PRODUCT]-(:Order)<-[:PURCHASED]-(c:Customer)
RETURN distinct c.companyName;New Customers without Orders yet
Outer Joins, Aggregation
If we turn the question around and ask "What have I bought and paid in total?", the JOIN stays the same, only the filter expression changes. Except if we have customers without any orders and still want to return them. Then we have to use OUTER joins to make sure that results are returned even if there were no matching rows in other tables.
SELECT p.ProductName, sum(od.UnitPrice * od.Quantity) AS Volume
FROM customers AS c
LEFT OUTER JOIN orders AS o ON (c.CustomerID = o.CustomerID)
LEFT OUTER JOIN order_details AS od ON (o.OrderID = od.OrderID)
LEFT OUTER JOIN products AS p ON (od.ProductID = p.ProductID)
WHERE c.CompanyName = 'Drachenblut Delikatessen'
GROUP BY p.ProductName
ORDER BY Volume DESC;In our Cypher query, the MATCH between customer and order becomes an OPTIONAL MATCH, which is the equivalent of an OUTER JOIN.
MATCH (c:Customer {companyName:"Drachenblut Delikatessen"})
OPTIONAL MATCH (p:Product)<-[pu:PRODUCT]-(:Order)<-[:PURCHASED]-(c)
RETURN p.productName, toInteger(sum(pu.unitPrice * pu.quantity)) AS volume
ORDER BY volume DESC;Top-Selling Employees
Aggregation, Grouping
In the previous query we sneaked in a bit of aggregation. By summing up product prices and ordered quantities, we provided an aggregated view per product for this customer.
You can use aggregation functions like sum, count, avg, max both in SQL and Cypher.
In SQL, aggregation is explicit so you have to provide all grouping keys again in the GROUP BY clause.
If we want to see our top-selling employees.
SELECT e.EmployeeID, count(*) AS Count
FROM Employee AS e
JOIN Order AS o ON (o.EmployeeID = e.EmployeeID)
GROUP BY e.EmployeeID
ORDER BY Count DESC LIMIT 10;In Cypher grouping for aggregation is implicit. As soon as you use the first aggregation function, all non-aggregated columns automatically become grouping keys.
MATCH (:Order)<-[:SOLD]-(e:Employee)
RETURN e.name, count(*) AS cnt
ORDER BY cnt DESC LIMIT 10Employee Territories
Collecting Master-Detail Queries
In SQL there is a particularly dreaded kind of query - master detail information. You have one main entity (master, head, parent) and many dependent ones (detail, position, child). Usually you either query it by joining both and returning the master data multiple times (once for each detail), or by only fetching the primary key of the master and then pulling all detail rows via that foreign key.
For instance if we look at the employees per territory, then the territory information is returned for each employee.
SELECT e.LastName, et.Description
FROM Employee AS e
JOIN EmployeeTerritory AS et ON (et.EmployeeID = e.EmployeeID)
JOIN Territory AS t ON (et.TerritoryID = t.TerritoryID);In Cypher we can either return the structure like in SQL.
Or we can choose to use the collect aggregation function, which aggregates values into a collection (list,array).
So we only return one row per parent, containing an inlined collection of child values.
This also works for nested values.
MATCH (t:Territory)<-[:IN_TERRITORY]-(e:Employee)
RETURN t.description, collect(e.lastName);Product Categories
Hierarchies and Trees, Variable Length Joins
If you have to express category-, territory- or organizational hierarchies in SQL then you model it usually with a self-join via a foreign key from child to parent. Adding data is not problematic, as are single level queries (get all children for this parent). As soon as you get into multi-level queries, the number of joins explodes, especially if your level depth not fixed.
Taking the example of the product categories, we have to decide upfront up to how many levels of categories we want to query. We will tackle only three potential levels here (which means 1+2+3 = 6 self-joins of the ProductCategory table).
SELECT p.ProductName
FROM Product AS p
JOIN ProductCategory pc ON (p.CategoryID = pc.CategoryID AND pc.CategoryName = "Dairy Products")
JOIN ProductCategory pc1 ON (p.CategoryID = pc1.CategoryID
JOIN ProductCategory pc2 ON (pc2.ParentID = pc2.CategoryID AND pc2.CategoryName = "Dairy Products")
JOIN ProductCategory pc3 ON (p.CategoryID = pc3.CategoryID
JOIN ProductCategory pc4 ON (pc3.ParentID = pc4.CategoryID)
JOIN ProductCategory pc5 ON (pc4.ParentID = pc5.CategoryID AND pc5.CategoryName = "Dairy Products")
;Cypher is able to express hierarchies of any depth just with the appropriate relationships.
Variable levels are represented by variable length paths, which are denoted by a star * after the relationship-type and optional limits (min..max).
MATCH (p:Product)-[:CATEGORY]->(l:ProductCategory)-[:PARENT*0..]-(:ProductCategory {name:"Dairy Products"})
RETURN p.nameThere is much more to Cypher than shown in this short section. Hopefully the comparison with SQL helped you to understand the concepts. If you are intrigued by the possibilities and want to try and learn more, just install Neo4j on your machine and use the links to our different Cypher learning resources.
Learn Cypher:
Resources
|
Are you struggling?
If you need help with any of the information contained on this page, you can reach out to other members of our community.
You can ask questions in the Cypher category on the Neo4j Community Site.
|
Was this page helpful?