Getting Started with Cypher
This guide explains the basic concepts of Cypher, Neo4j’s graph query language. You should be able to read and understand Cypher queries after finishing this guide.
You should be familiar with graph database concepts and the property graph model.
Beginner
Why Cypher?
We already know that Neo4j’s property graph model is composed of nodes and relationships, which may also have properties associated with them. However, nodes and relationships are the simple components that build the most valuable and powerful piece of the property graph model - the pattern. Patterns are comprised of node and relationship elements and can express simple or complex traversals and paths.
Pattern recognition is fundamental to the way that the brain works. Because of this, humans are very good at working with patterns (think of visual diagrams or even memory-matching games). Cypher is also heavily based on patterns and is designed to recognize various versions of these patterns in data, making it a simple and logical language for users to learn.
Cypher Syntax
The video below walks through some background on Cypher, basic syntax, and some intermediate examples. The concepts in the video are discussed in the paragraphs below, as well as in upcoming guides.
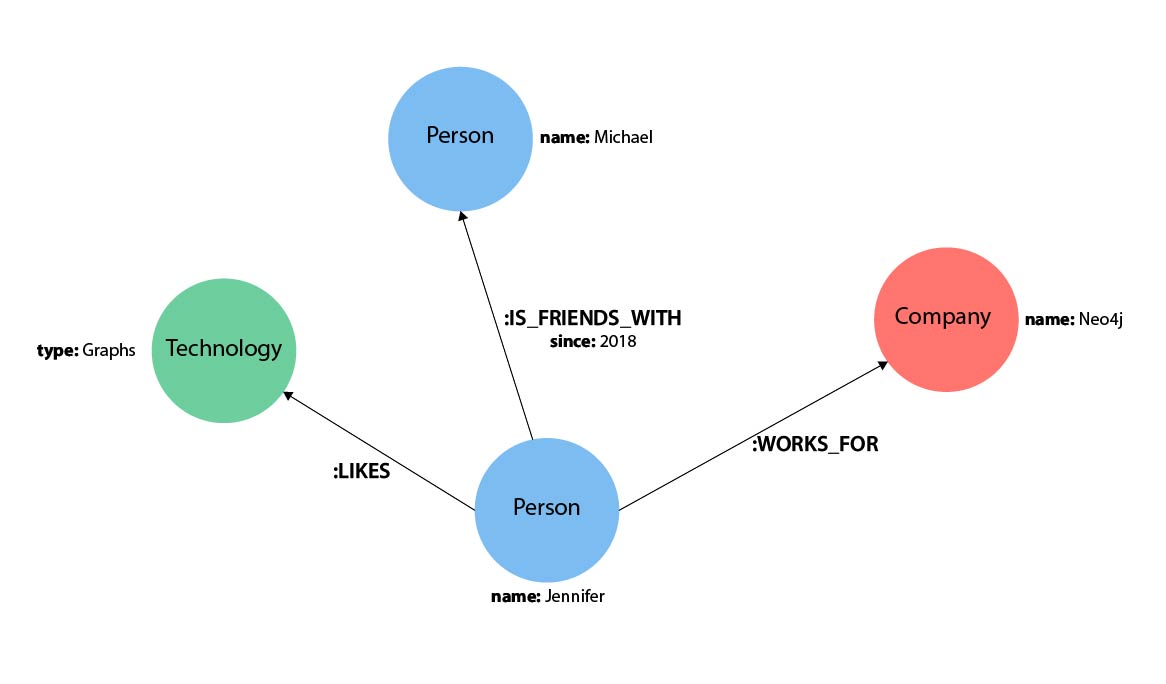
Since Cypher is designed to be human-readable, it’s construct is based on English prose and iconography to make syntax visual and easily understood. For example, take a look at the simple graph data in the image below. How would you represent this data in English? NOTE: the answer is in the paragraph below
|
Jennifer likes Graphs. Jennifer is friends with Michael. Jennifer works for Neo4j. |
Cypher syntax will build upon this English-language structure we just created. In the next section, we will see exactly how to write this example in Cypher.
Cypher Comments
As you work through this guide, you will see comments in the Cypher code to help explain the syntax or what a query is doing.
Comments in Cypher are the same as in many programming languages.
You can add comments by starting a line with // and putting text after the slashes.
Just like in other languages, starting the line with two forward slashes will mean that anything on that line will become a comment.
|
This is especially helpful to use in Neo4j Browser when saving queries. If you add a comment before the query, the comment automatically becomes the name of the saved query! |
Representing Nodes in Cypher
Since Cypher uses ASCII-Art for patterns, we need a visual way to represent each component of our pattern above.
We know that the main components of the property graph model are nodes and relationships.
Remember that nodes are the data entities in your graph and that you can often identify nodes by finding the nouns or objects in your data model.
In our example, Jennifer, Michael, Graphs, and Neo4j are our nodes.
To depict nodes in Cypher, we surround the node with parentheses, e.g. (node).
Notice how the parentheses look similar to the circles that the visual representation uses for nodes in our data model.
Node Variables
If we later want to refer to the node, we can give it a variable like (p) for person or (t) for thing.
In real-world queries, we might use longer, more expressive variable names like (person) or (thing).
Just like in programming language variables, you can name your variables what you want and reference them by that same name later in a query.
If the node is not relevant to your return results, you can specify an anonymous node using empty parentheses ().
This means that you will not be able to return this node later in the query.
Node Labels
If you remember from the property graph data model, you can also group similar nodes together by assigning a node label.
Labels are kind of like tags and allow you to specify certain types of entities to look for or create.
In our example, Person, Technology, and Company are the labels.
You can kind of think of this like telling SQL which table to look for the particular row.
Just like to tell SQL to query a person’s information from a Person or Employee or Customer table, you can also tell Cypher to only check those labels for that information.
This helps Cypher distinguish between entities and optimize execution for your queries.
It is always better to use node labels in your queries, where possible.
|
If you do not specify a label for Cypher to filter out non-matching node categories, the query will check all of the nodes in the database! As you can imagine, this would be cumbersome if you had a very large graph. |
Example: Nodes in Cypher
Using our graph example above, let’s see how we could specify our nodes.
() //anonymous node (no label or variable) can refer to any node in the database
(p:Person) //using variable p and label Person
(:Technology) //no variable, label Technology
(work:Company) //using variable work and label CompanyRepresenting Relationships in Cypher
To fully utilize the power of a graph database, we also need to express the relationships between our nodes.
Relationships are represented in Cypher using an arrow --> or <-- between two nodes.
Notice how the syntax looks like the arrows and lines connecting our nodes in the visual representation.
Additional information, such as how nodes are connected (relationship type) and any properties pertaining to the relationship, can be placed in square brackets inside of the arrow.
In our example, the lines with LIKES, IS_FRIENDS_WITH, and WORKS_FOR between nodes are our relationships.

Undirected relationships are represented with no arrow and just two dashes --.
This means that the relationship can be traversed in either direction.
While a direction must be inserted to the database, it can be matched with an undirected relationship where Cypher ignores any particular direction and retrieves the relationship and connected nodes, no matter what the physical direction is.
This allows the queries to be flexible and not force the user to know the physical direction of the relationship stored in the database.
|
If data is stored with one relationship direction, and a query specifies the wrong direction, Cypher will not return any results. In these cases where you may not be sure of direction, it is better to use an undirected relationship and retrieve some results. |
Relationship Types
Relationship types categorize and add meaning to a relationship, similar to how labels group nodes. In our property graph data model, relationships show how nodes are connected and related to each other. You can usually identify relationships in your data model by looking for actions or verbs.
You can specify any type of relationship you want between nodes, but we recommend good naming conventions using verbs and actions. Poor relationship type names make it more difficult to both read and write Cypher (remember, it should sound like English!).
For example, let us look at the relationship types from our example graph.
-
[:LIKES]- makes sense when we put nodes on either side of the relationship (Jennifer LIKES Graphs) -
[:IS_FRIENDS_WITH]- makes sense when we put nodes with it (Jennifer IS_FRIENDS_WITH Michael) -
[:WORKS_FOR]- makes sense with nodes (Jennifer WORKS_FOR Neo4j)
Relationship Variables
Just as we did with nodes, if we want to refer to a relationship later in a query, we can give it a variable like [r] or [rel].
We can also use longer, more expressive variable names like [likes] or [knows].
If you do not need to reference the relationship later, you can specify an anonymous relationship using two dashes --, -->, <--.
As an example, you could use either -[rel]-> or -[rel:LIKES]-> and call the rel variable later in your query to reference the relationship and its details.
|
If you forget the colon in front of a relationship type like this |
Node or Relationship Properties
We have talked about how to write Cypher for nodes, relationships, and labels. The last piece of our property graph data model is for properties. Remember that properties are name-value pairs that provide additional details to our nodes and relationships.
To represent these in Cypher, we can use curly braces within the parentheses of a node or the brackets of a relationship.
The name and value of the property then go inside the curly braces.
Our example graph has both a node property (name) and a relationship property (since).
-
Node property:
(p:Person {name: 'Jennifer'}) -
Relationship property:
-[rel:IS_FRIENDS_WITH {since: 2018}]->
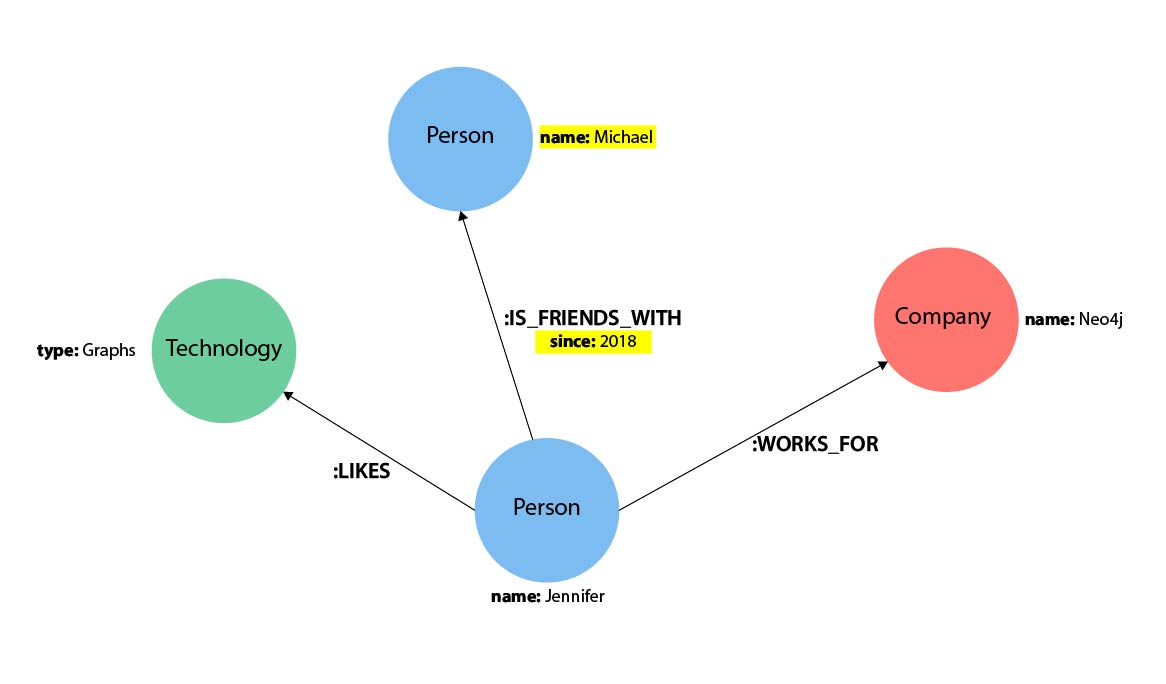
Properties can have values with a variety of data types. To see the full list that Cypher offers, see the manual section on values and types.
Patterns in Cypher
Nodes and relationships make up the building blocks for graph patterns. These building blocks can come together to express simple or complex patterns. Patterns are the most powerful capability of graphs. In Cypher, they can be written as a continuous path or separated into smaller patterns and tied together with commas.
To show a pattern in Cypher, we need to combine the node and relationship syntaxes we have learned so far.
Let us use our example of Jennifer likes Graphs.
In Cypher, this pattern would look like the code below.
(p:Person {name: "Jennifer"})-[rel:LIKES]->(g:Technology {type: "Graphs"})This bit of Cypher tells the pattern we want, but it does not tell whether we want to find that existing pattern or insert it as a new pattern. To tell Cypher what we want it to do with the pattern, we need to add some keywords.
|
Are you struggling?
If you need help with any of the information contained on this page, you can reach out to other members of our community.
You can ask questions in the Cypher category on the Neo4j Community Site.
|
Was this page helpful?