Link Prediction with the Graph Data Science Library
In this guide, we will solve a link prediction problem with the Graph Data Science Library.
Please have Neo4j (version 4.0 or later), Graph Data Science Library (version 1.5.0 or later), and APOC downloaded and installed.
Intermediate
What is link prediction?
Link Prediction is the problem of predicting the existence of a relationship between nodes in a graph. In this guide, we will predict co-authorships using the link prediction machine learning model that was introduced in version 1.5.0 of the Graph Data Science Library.
|
For background reading about link prediction, see the Link Prediction Concepts Developer Guide. |
Citation Graph

In this guide, we’re going to use data from the DBLP Citation Network, which includes citation data from various academic sources. The full dataset is very large, but we’re going to use a subset that contains data from a few Software Development Conferences.
A screenshot of the available datasets is shown below:
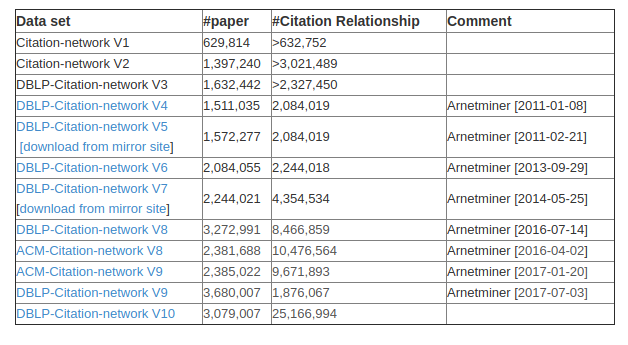
We can import this dataset by running the following queries:
CREATE CONSTRAINT ON (a:Article) ASSERT a.index IS UNIQUE;
CREATE CONSTRAINT ON (a:Author) ASSERT a.name IS UNIQUE;
CREATE CONSTRAINT ON (v:Venue) ASSERT v.name IS UNIQUE;CALL apoc.periodic.iterate(
'UNWIND ["dblp-ref-0.json", "dblp-ref-1.json", "dblp-ref-2.json", "dblp-ref-3.json"] AS file
CALL apoc.load.json("https://github.com/mneedham/link-prediction/raw/master/data/" + file)
YIELD value
RETURN value',
'MERGE (a:Article {index:value.id})
SET a += apoc.map.clean(value,["id","authors","references", "venue"],[0])
WITH a, value.authors as authors, value.references AS citations, value.venue AS venue
MERGE (v:Venue {name: venue})
MERGE (a)-[:VENUE]->(v)
FOREACH(author in authors |
MERGE (b:Author{name:author})
MERGE (a)-[:AUTHOR]->(b))
FOREACH(citation in citations |
MERGE (cited:Article {index:citation})
MERGE (a)-[:CITED]->(cited))',
{batchSize: 1000, iterateList: true}
);MATCH (a:Article)
WHERE not(exists(a.title))
DETACH DELETE a;We can see what the imported citation graph looks like in the Neo4j Browser Visualization shown below:

Building a co-author graph
The dataset doesn’t contain relationships between authors describing their collaborations, but we can infer them based on finding articles authored by multiple people.
The code below creates a CO_AUTHOR relationship between authors that have collaborated on at least one article:
CALL apoc.periodic.iterate(
"MATCH (a1)<-[:AUTHOR]-(paper)-[:AUTHOR]->(a2:Author)
WITH a1, a2, paper
ORDER BY a1, paper.year
RETURN a1, a2, collect(paper)[0].year AS year, count(*) AS collaborations",
"MERGE (a1)-[coauthor:CO_AUTHOR {year: year}]-(a2)
SET coauthor.collaborations = collaborations",
{batchSize: 100}
);We create only one CO_AUTHOR relationship between authors that have collaborated, even if they’ve collaborated on multiple articles.
We create a couple of properties on these relationships:
-
a
yearproperty that indicates the publication year of the first article on which the authors collaborated -
a
collaborationsproperty that indicates how many articles on which the authors have collaborated

Train and test datasets

To avoid data leakage, we need to split our graph into training and test sub graphs. The GDS Library has a Split Relationships algorithm that takes care of this for us.
Before we use that algorithm, let’s create an in-memory graph of our co-authors, by running the following query:
CALL gds.graph.create(
'linkpred',
'Author',
{
CO_AUTHOR: {
orientation: 'UNDIRECTED'
}
}
);| nodeProjection | relationshipProjection | graphName | nodeCount | relationshipCount | createMillis |
|---|---|---|---|---|---|
{Author: {properties: {}, label: "Author"}} |
{CO_AUTHOR: {orientation: "UNDIRECTED", aggregation: "DEFAULT", type: "CO_AUTHOR", properties: {}}} |
"linkpred" |
80299 |
310448 |
53 |
And now we will use the Split Relationships algorithm to create both train and test in-memory graphs:
CALL gds.alpha.ml.splitRelationships.mutate('linkpred', {
relationshipTypes: ['CO_AUTHOR'],
remainingRelationshipType: 'CO_AUTHOR_REMAINING',
holdoutRelationshipType: 'CO_AUTHOR_TESTGRAPH',
holdoutFraction: 0.2
})
YIELD createMillis, computeMillis, mutateMillis, relationshipsWritten;| createMillis | computeMillis | mutateMillis | relationshipsWritten |
|---|---|---|---|
0 |
97 |
0 |
310448 |
CALL gds.alpha.ml.splitRelationships.mutate('linkpred', {
relationshipTypes: ['CO_AUTHOR_REMAINING'],
remainingRelationshipType: 'CO_AUTHOR_IGNORED_FOR_TRAINING',
holdoutRelationshipType: 'CO_AUTHOR_TRAINGRAPH',
holdoutFraction: 0.2
})
YIELD createMillis, computeMillis, mutateMillis, relationshipsWritten;| createMillis | computeMillis | mutateMillis | relationshipsWritten |
|---|---|---|---|
0 |
81 |
0 |
248360 |
Feature Engineering

Now it’s time to engineer some features which we’ll use to train our model. We are going to train a model that tries to identify missing links in the current graph, which might have happened because of misrecording of the authors who wrote a paper, resulting in missing collaborations. This is also referred to as transductive learning, and means that when we generate features we will generate them using the whole graph.
PageRank
The PageRank algorithm computes a score that indicates the transitive influence of an author. The higher the score, the more influential they are.
We can compute the PageRank for each author and store the result as a node property in the in-memory graph, by running the following query:
CALL gds.pageRank.mutate('linkpred',{
maxIterations: 20,
dampingFactor: 0.05,
relationshipTypes: ["CO_AUTHOR"],
mutateProperty: 'pagerank'
})
YIELD nodePropertiesWritten, mutateMillis, createMillis, computeMillis;| nodePropertiesWritten | mutateMillis | createMillis | computeMillis |
|---|---|---|---|
80299 |
0 |
0 |
62 |
Triangle Count
The Triangle Count algorithm computes the number of triangles that a node forms. Three nodes A,B,C form a triangle if A is a co-author of B, B is a co-author of C, and C is a co-author of A.
We can compute the number of triangles for each author and store the results as a node property in the in-memory graph, by running the following query:
CALL gds.triangleCount.mutate('linkpred',{
relationshipTypes: ["CO_AUTHOR"],
mutateProperty: 'triangles'
})
YIELD nodePropertiesWritten, mutateMillis, nodeCount, createMillis, computeMillis;| nodePropertiesWritten | mutateMillis | nodeCount | createMillis | computeMillis |
|---|---|---|---|---|
80299 |
0 |
80299 |
0 |
19 |
Fast Random Projection
The Fast Random Projection (FastRP) algorithm computes embeddings based on a node’s neighborhood. This means that two nodes that have similar neighborhoods should be assigned similar embedding vectors.
We can compute the FastRP embedding for each author and store the results as a node property in the in-memory graph, by running the following query:
CALL gds.fastRP.mutate('linkpred', {
embeddingDimension: 250,
relationshipTypes: ["CO_AUTHOR_REMAINING"],
iterationWeights: [0, 0, 1.0, 1.0],
normalizationStrength:0.05,
mutateProperty: 'fastRP_Embedding'
})
YIELD nodePropertiesWritten, mutateMillis, nodeCount, createMillis, computeMillis;| nodePropertiesWritten | mutateMillis | nodeCount | createMillis | computeMillis |
|---|---|---|---|---|
80299 |
0 |
80299 |
8 |
334 |
There is also a version of the FastRP algorithm that takes node properties into account.
We can compute a FastRP embedding that uses the pagerank and triangles scores for each author and store the results as a node property in the in-memory graph, by running the following query:
CALL gds.beta.fastRPExtended.mutate('linkpred', {
propertyDimension: 45,
embeddingDimension: 250,
featureProperties: ["pagerank", "triangles"],
relationshipTypes: ["CO_AUTHOR_REMAINING"],
iterationWeights: [0, 0, 1.0, 1.0],
normalizationStrength:0.05,
mutateProperty: 'fastRP_Embedding_Extended'
})
YIELD nodePropertiesWritten, mutateMillis, nodeCount, createMillis, computeMillis;| nodePropertiesWritten | mutateMillis | nodeCount | createMillis | computeMillis |
|---|---|---|---|---|
80299 |
0 |
80299 |
8 |
348 |
Model Training and Evaluation
Now let’s build a model based on these features. The link prediction procedure trains a logistic regression model and evaluates it using the AUCPR metric.
We’ll train out first model using only the fastRP_Embedding property.
We can do this by running the query below:
CALL gds.alpha.ml.linkPrediction.train('linkpred', {
trainRelationshipType: 'CO_AUTHOR_TRAINGRAPH',
testRelationshipType: 'CO_AUTHOR_TESTGRAPH',
modelName: 'model-only-embedding',
featureProperties: ['fastRP_Embedding'],
validationFolds: 5,
classRatio: 1.0,
randomSeed: 2,
params: [
{penalty: 0.25, maxIterations: 1000},
{penalty: 0.5, maxIterations: 1000},
{penalty: 1.0, maxIterations: 1000},
{penalty: 0.0, maxIterations: 1000}
]
})
YIELD trainMillis, modelInfo
RETURN trainMillis,
modelInfo.bestParameters AS winningModel,
modelInfo.metrics.AUCPR.outerTrain AS trainGraphScore,
modelInfo.metrics.AUCPR.test AS testGraphScore;| winningModel | trainGraphScore | testGraphScore |
|---|---|---|
{maxIterations: 1000, penalty: 0.5} |
0.9656900400862477 |
0.9409744114683815 |
This looks good - the model is very good at predicting missing relationships in the graph.
One tweak we could make is to specify the linkFeatureCombiner in the params used to train the model.
By default, the L2 feature combiner is used, which means that the (feature(nodeA) - feature(nodeB))^2 formula is used to generate features for each pair of nodes.
If we use HADAMARD instead, the feature(nodeA) * feature(nodeB) formula is used instead.
With the HADAMARD combiner, we are saying that there’s a higher probability of a relationship existing between two nodes that have a score of 100 than between two nodes that have a score of 0.
We can train a model using this combiner by running the following query:
CALL gds.alpha.ml.linkPrediction.train('linkpred', {
trainRelationshipType: 'CO_AUTHOR_TRAINGRAPH',
testRelationshipType: 'CO_AUTHOR_TESTGRAPH',
modelName: 'model-only-embedding-hadamard',
featureProperties: ['fastRP_Embedding'],
validationFolds: 5,
classRatio: 1.0,
randomSeed: 2,
params: [
{penalty: 0.25, maxIterations: 1000, linkFeatureCombiner: 'HADAMARD'},
{penalty: 0.5, maxIterations: 1000, linkFeatureCombiner: 'HADAMARD'},
{penalty: 1.0, maxIterations: 1000, linkFeatureCombiner: 'HADAMARD'},
{penalty: 0.0, maxIterations: 1000, linkFeatureCombiner: 'HADAMARD'}
]
})
YIELD modelInfo
RETURN modelInfo.bestParameters AS winningModel,
modelInfo.metrics.AUCPR.outerTrain AS trainGraphScore,
modelInfo.metrics.AUCPR.test AS testGraphScore;|
Don’t forget that if you are not using the Enterprise Edition of the Graph Data Science library, you can only have a limited number of models in memory at any given time, so you must drop unused models via |
| winningModel | trainGraphScore | testGraphScore |
|---|---|---|
{maxIterations: 1000, linkFeatureCombiner: "HADAMARD", penalty: 0.25} |
0.9999845975769923 |
0.9455924656253945 |
That’s slightly better than our previous model.
Next we’re going to train models based on the other features that we generated. But first, let’s drop all the existing models:
CALL gds.beta.model.list()
YIELD modelInfo
CALL gds.beta.model.drop(modelInfo.modelName)
YIELD modelInfo AS info
RETURN info;We can now train models based on combinations of features, by running the following query:
UNWIND [
["fastRP_Embedding_Extended"],
["fastRP_Embedding", "pagerank", "triangles"],
["fastRP_Embedding", "pagerank"],
["fastRP_Embedding", "triangles"],
["fastRP_Embedding"]
] AS featureProperties
CALL gds.alpha.ml.linkPrediction.train('linkpred', {
trainRelationshipType: 'CO_AUTHOR_TRAINGRAPH',
testRelationshipType: 'CO_AUTHOR_TESTGRAPH',
modelName: 'model-' + apoc.text.join(featureProperties, "-"),
featureProperties: featureProperties,
validationFolds: 5,
classRatio: 1.0,
randomSeed: 2,
params: [
{penalty: 0.25, maxIterations: 1000, linkFeatureCombiner: 'HADAMARD'},
{penalty: 0.5, maxIterations: 1000, linkFeatureCombiner: 'HADAMARD'},
{penalty: 1.0, maxIterations: 1000, linkFeatureCombiner: 'HADAMARD'},
{penalty: 0.0, maxIterations: 1000, linkFeatureCombiner: 'HADAMARD'}
]
})
YIELD modelInfo
RETURN modelInfo;We can return a stream of all the models and their accuracies by running the following query:
CALL gds.beta.model.list()
YIELD modelInfo
RETURN modelInfo.modelName AS modelName,
modelInfo.bestParameters AS winningModel,
modelInfo.metrics.AUCPR.outerTrain AS trainGraphScore,
modelInfo.metrics.AUCPR.test AS testGraphScore
ORDER BY testGraphScore DESC;| modelName | winningModel | trainGraphScore | testGraphScore |
|---|---|---|---|
"model-fastRP_Embedding-pagerank" |
{maxIterations: 1000, linkFeatureCombiner: "HADAMARD", penalty: 1.0} |
0.9999889998620444 |
0.9577993987170548 |
"model-fastRP_Embedding-triangles" |
{maxIterations: 1000, linkFeatureCombiner: "HADAMARD", penalty: 0.0} |
0.9990012589999202 |
0.9457656238136779 |
"model-fastRP_Embedding" |
{maxIterations: 1000, linkFeatureCombiner: "HADAMARD", penalty: 0.25} |
0.9999845975769923 |
0.9455926563716637 |
"model-fastRP_Embedding-pagerank-triangles" |
{maxIterations: 1000, linkFeatureCombiner: "HADAMARD", penalty: 0.0} |
0.9987023730262333 |
0.9376955436526965 |
"model-fastRP_Embedding_Extended" |
{maxIterations: 1000, linkFeatureCombiner: "HADAMARD", penalty: 0.0} |
0.9467628798627221 |
0.8689537717717958 |
Interestingly the best model combines the fastRP_Embedding and pagerank features, but the model based on the fastRP_Embedding_Extended embedding that also includes the pagerank features does much worse.
Next Steps
We’ve trained a reasonably good model that can predict potential mislabelling in citations. A good next step would be to train a model that predicts future collaborations (inductive learning). For an example of how to do this using scikit-learn, see Link Prediction with GDSL and scikit-learn.
Was this page helpful?