Graph Embeddings
In this guide, we will learn about graph embeddings.
Please have Neo4j (version 4.0 or later) and Graph Data Science Library (version 2.0 or later) downloaded and installed to use graph embeddings.
Intermediate
What are graph embeddings?
A graph embedding determines a fixed length vector representation for each entity (usually nodes) in our graph. These embeddings are a lower dimensional representation of the graph and preserve the graph’s topology.
Node embedding techniques usually consist of the following functions:
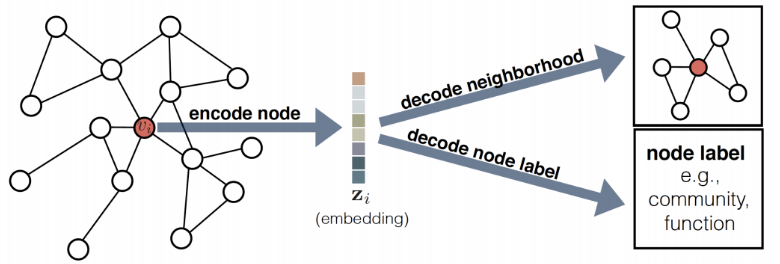
- Similarity function
-
measures the similarity between nodes
- Encoder function
-
generates the node embedding
- Decoder function
-
reconstructs pairwise similarity
- Loss function
-
checks the quality of the reconstruction
Use cases for graph embeddings
There are several use cases that are well suited for graph embeddings:
-
We can visually explore the data by reducing the embeddings to 2 or 3 dimensions with the help of algorithms like t-distributed stochastic neighbor embedding (t-SNE) and Principle Component Analysis (PCA).
-
We could build a kNN similarity graph from the embeddings. The similarity graph could then be used to make recommendations as part of a k-Nearest Neighbors query.
-
We can use the embeddings as the features to feed into a machine learning model, rather than generating those features by hand. In this use case, embeddings can be considered an implementation of Representational Learning.
Neo4j’s graph embeddings
The Neo4j Graph Data Science Library supports several graph embedding algorithms.
| Name | Speed | Supports node properties? | Implementation details |
|---|---|---|---|
Fast |
Yes |
Linear Algebra |
|
Intermediate |
No |
Neural Network |
|
Slow |
Yes |
Neural Network |
All the embedding algorithms work on a monopartite undirected input graph.
- Fast Random Projection
-
The Fast Random Projection embedding uses sparse random projections to generate embeddings. It is an implementation of the FastRP algorithm. It is the fastest of the embedding algorithms and can therefore be useful for obtaining baseline embeddings. The embeddings it generates are often equally performant as more complex algorithms that take longer to run. Additionally, the FastRP algorithm supports the use of node properties as features for generating embeddings, as described here.
- node2Vec
-
node2Vec computes embeddings based on biased random walks of a node’s neighborhood. The algorithm trains a single-layer feedforward neural network, which is used to predict the likelihood that a node will occur in a walk based on the occurrence of another node. node2Vec has parameters that can be tuned to control whether the random walks behave more like breadth first or depth first searches. This tuning allows the embedding to either capture homophily (similar embeddings capture network communities) or structural equivalence (similar embeddings capture similar structural roles of nodes).
- GraphSAGE
-
This algorithm is the only one that supports node properties. Training embeddings that include node properties can be useful for including information beyond the topology of the graph, like meta data, attributes, or the results of other graph algorithms. GraphSAGE differs from the other algorithms in that it learns a function to calculate an embedding rather than training individual embeddings for each node.
Was this page helpful?