Node Classification with GDSL
In this guide, we will learn how to perform node classification.
Please have Neo4j (version 4.2.3 or later) and Graph Data Science Library (version 1.5 or later) downloaded and installed to use graph embeddings. You should also have APOC (version 4.2.0.1 or later).
Intermediate
What is node classification?
Node classification is a supervised machine learning (ML) approach whereby existing nodes with known classes can be used to train a model that will learn the classes for nodes where they are unknown. In order to achieve this, the data must be split into two parts — a training graph and a testing graph — prior to predicting the classes for the unknown nodes. The training process involves splitting the training graph into two parts — a training and validation set — that will be used to fine tune the model through subsequent steps.
Node classification is based on logistic regression. As in any ML model, care must be taken in choosing both the training and test sets as well as how to ensure that the model is not overfitting the data. In the case of the GDS Node Classification algorithm, an L2 norm is used as a penalty.
|
The code examples used in this guide can be found in this GitHub repository. |
Marvel Universe dataset
In this example we will be using a dataset from the comics and movies associated with the Marvel Universe. This dataset can be found here. It contains 40,616 characters and 65,870 relationships connecting them. Additionally, the characters have numerous properties that can be associated with each node. We will be using this dataset to try and predict, off of a series of characters for training purposes, which characters are X-Men and which are not.
Data preparation
We will begin by loading in the data to the database from a series of CSV files available online. This can be done with the following query:
CALL apoc.schema.assert({Character:['name']},{Comic:['id'], Character:['id'], Event:['id'], Group:['id']});
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/Marvel/heroes.csv" as row
CREATE (c:Character)
SET c += row;
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/Marvel/groups.csv" as row
CREATE (c:Group)
SET c += row;
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/Marvel/events.csv" as row
CREATE (c:Event)
SET c += row;
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/Marvel/comics.csv" as row
CREATE (c:Comic)
SET c += apoc.map.clean(row,[],["null"]);
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/Marvel/heroToComics.csv" as row
MATCH (c:Character{id:row.hero})
MATCH (co:Comic{id:row.comic})
MERGE (c)-[:APPEARED_IN]->(co);
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/Marvel/heroToEvent.csv" as row
MATCH (c:Character{id:row.hero})
MATCH (e:Event{id:row.event})
MERGE (c)-[:PART_OF_EVENT]->(e);
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/Marvel/heroToGroup.csv" as row
MATCH (c:Character{id:row.hero})
MATCH (g:Group{id:row.group})
MERGE (c)-[:PART_OF_GROUP]->(g);
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/Marvel/heroToHero.csv" as row
MATCH (s:Character{id:row.source})
MATCH (t:Character{id:row.target})
CALL apoc.create.relationship(s,row.type, {}, t) YIELD rel
RETURN distinct 'done';
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/Marvel/heroStats.csv" as row
MATCH (s:Character{id:row.hero})
CREATE (s)-[:HAS_STATS]->(stats:Stats)
SET stats += apoc.map.clean(row,['hero'],[]);
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/Marvel/heroFlight.csv" as row
MATCH (s:Character{id:row.hero})
SET s.flight = row.flight;
MATCH (s:Stats)
WITH keys(s) as keys LIMIT 1
MATCH (s:Stats)
UNWIND keys as key
CALL apoc.create.setProperty(s, key, toInteger(s[key]))
YIELD node
RETURN distinct 'done';This query creates a series of nodes and their labels and properties: Comic, Character, Stats along with a variety of edges such as which comics the characters appeared in which comics, who is an enemy of whom, etc. You can see a schema of this graph using CALL db.schema.visualization() here:
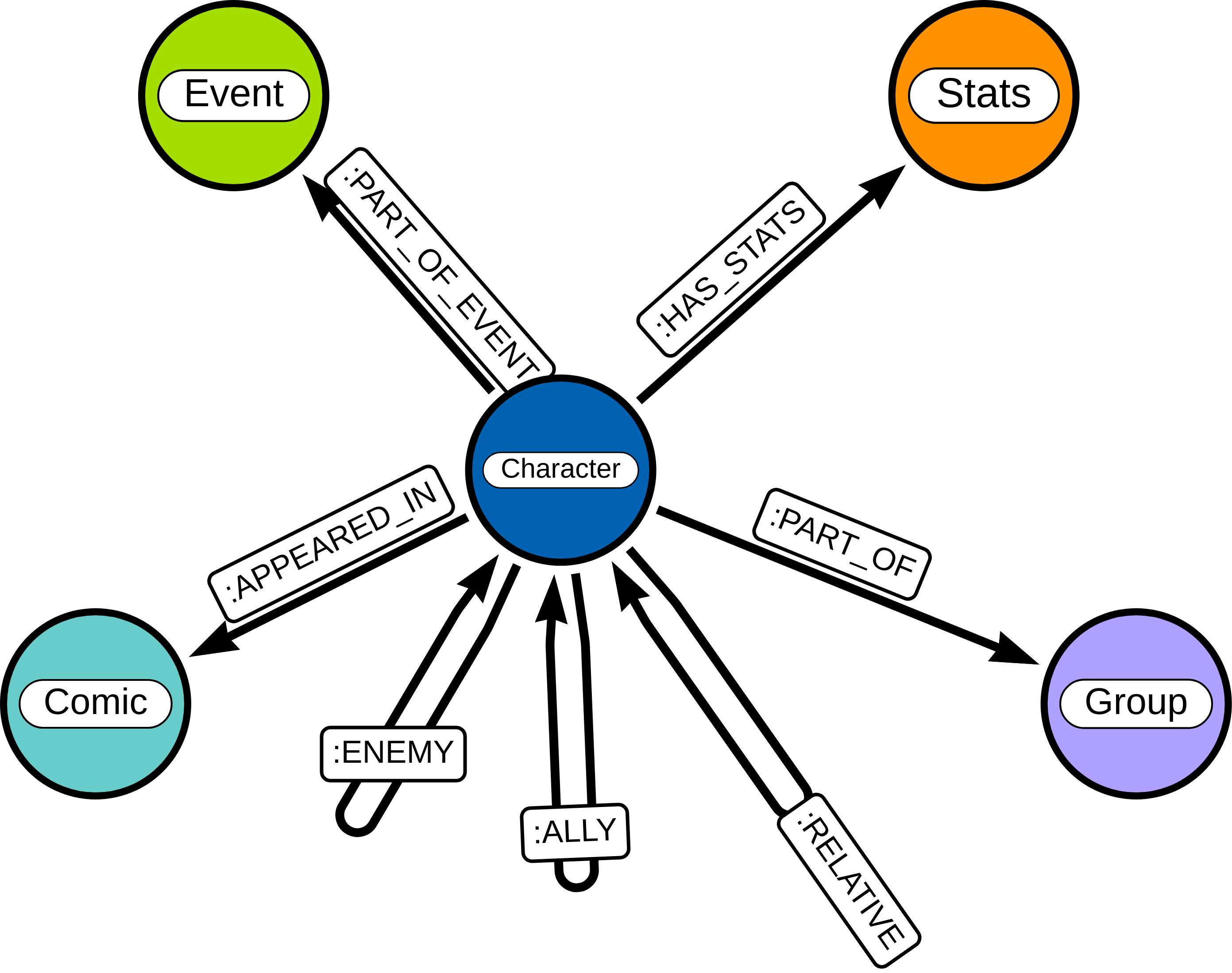
(Note that for the simplicity of the image we are not showing the node properties since there are many.)
We next bring in the character traits from the stats to be node properties:
MATCH (c:Character)-[:HAS_STATS]->(s)
WITH c, s.strength as strength, s.fighting_skills as fighting_skills, s.durability as durability, s.speed as speed, s.intelligence as intelligence, s.energy as energy
SET c.strength=strength,
c.fighting_skills=fighting_skills,
c.durability=durability,
c.speed=speed,
c.intelligence=intelligence,
c.energy=energy
RETURN count(c)These node properties will eventually be used to build the node classification model via both embeddings as well as the tabular approach.
Next, we set up the co-occurance of characters such that we can identify which characters appear with which other characters and how often (which will be used to identify the edge weighting). This is done via:
MATCH (c1:Character)-[:APPEARED_IN]->(c:Comic)<-[:APPEARED_IN]-(c2:Character)
WITH c1, c2, count(c) as weight
MERGE (c1)-[:APPEARED_WITH{times:weight}]->(c2)
MERGE (c2)-[:APPEARED_WITH{times:weight}]->(c1)Feature engineering
Once our data is loaded in, it is time to start the process of engineering the features that will be used to populate our mode. For example, we might consider a variety of centrality measures of the character to be a feature that would be useful to train with. To obtain this, we first create an in-memory graph as:
CALL gds.graph.create(
'marvel-character-graph',
{
Person: {
label: 'Character',
properties: {
strength:{property:'strength',defaultValue:0},
fighting_skills:{property:'fighting_skills', defaultValue:0},
durability:{property:'durability', defaultValue:0},
speed:{property:'speed', defaultValue:0},
intelligence:{property:'intelligence', defaultValue:0}
}
}
}, {
APPEARS_WITH_UNDIRECTED: {
type: 'APPEARED_WITH',
orientation: 'UNDIRECTED',
aggregation: 'SINGLE',
properties: ['times']
},
APPEARS_WITH_DIRECTED: {
type: 'APPEARED_WITH',
orientation: 'NATURAL',
properties: ['times'],
aggregation: 'SINGLE'
},
ALLY_UNDIRECTED: {
type: 'ALLY',
orientation: 'UNDIRECTED',
aggregation: 'SINGLE'
},
ALLY_DIRECTED: {
type: 'ALLY',
orientation: 'NATURAL',
aggregation: 'SINGLE'
},
ENEMY_UNDIRECTED: {
type: 'ENEMY',
orientation: 'UNDIRECTED',
aggregation: 'SINGLE'
},
ENEMY_DIRECTED: {
type: 'ENEMY',
orientation: 'NATURAL',
aggregation: 'SINGLE'
}
});and then we use this graph to calculate the PageRank, Betweenness Centrality, and Hyperlink-Induced Topic Search (HITS) of each node and write those values back to the database:
// pageRank
CALL gds.pageRank.write('marvel-character-graph',{
relationshipTypes: ['APPEARS_WITH_DIRECTED'],
writeProperty: 'appeared_with_pageRank'
});
CALL gds.pageRank.write('marvel-character-graph',{
relationshipTypes: ['ALLY_DIRECTED'],
writeProperty: 'ally_pageRank'
});
CALL gds.pageRank.write('marvel-character-graph',{
relationshipTypes: ['ENEMY_DIRECTED'],
writeProperty: 'enemy_pageRank'
});
// betweenness
CALL gds.betweenness.write('marvel-character-graph',{
relationshipTypes: ['APPEARS_WITH_UNDIRECTED'],
writeProperty: 'appeared_with_betweenness'
});
CALL gds.betweenness.write('marvel-character-graph',{
relationshipTypes: ['ALLY_UNDIRECTED'],
writeProperty: 'ally_betweenness'
});
CALL gds.betweenness.write('marvel-character-graph',{
relationshipTypes: ['ENEMY_UNDIRECTED'],
writeProperty: 'enemy_betweenness'
});
//HITS
CALL gds.alpha.hits.write('marvel-character-graph',{
relationshipTypes: ['APPEARS_WITH_DIRECTED'],
hitsIterations: 50,
authProperty: 'appeared_with_auth',
hubProperty: 'appeared_with_hub'
});
CALL gds.alpha.hits.write('marvel-character-graph',{
relationshipTypes: ['ALLY_DIRECTED'],
hitsIterations: 50,
authProperty: 'appeared_with_auth',
hubProperty: 'appeared_with_hub'
});
CALL gds.alpha.hits.write('marvel-character-graph',{
relationshipTypes: ['ENEMY_DIRECTED'],
hitsIterations: 50,
authProperty: 'appeared_with_auth',
hubProperty: 'appeared_with_hub'
});We will also want these values added to the in-memory graph for the sake of calculating graph embeddings in the next step, which is achieved through the .mutate() command:
// pageRank
CALL gds.pageRank.mutate('marvel-character-graph',{
relationshipTypes: ['APPEARS_WITH_DIRECTED'],
mutateProperty: 'appeared_with_pageRank'
});
CALL gds.pageRank.mutate('marvel-character-graph',{
relationshipTypes: ['ALLY_DIRECTED'],
mutateProperty: 'ally_pageRank'
});
CALL gds.pageRank.mutate('marvel-character-graph',{
relationshipTypes: ['ENEMY_DIRECTED'],
mutateProperty: 'enemy_pageRank'
});
// betweenness
CALL gds.betweenness.mutate('marvel-character-graph',{
relationshipTypes: ['APPEARS_WITH_UNDIRECTED'],
mutateProperty: 'appeared_with_betweenness'
});
CALL gds.betweenness.mutate('marvel-character-graph',{
relationshipTypes: ['ALLY_UNDIRECTED'],
mutateProperty: 'ally_betweenness'
});
CALL gds.betweenness.mutate('marvel-character-graph',{
relationshipTypes: ['ENEMY_UNDIRECTED'],
mutateProperty: 'enemy_betweenness'
});
//HITS
CALL gds.alpha.hits.mutate('marvel-character-graph',{
relationshipTypes: ['APPEARS_WITH_DIRECTED'],
hitsIterations: 50,
authProperty: 'appeared_with_auth',
hubProperty: 'appeared_with_hub'
});
CALL gds.alpha.hits.mutate('marvel-character-graph',{
relationshipTypes: ['ALLY_DIRECTED'],
hitsIterations: 50,
authProperty: 'appeared_with_auth',
hubProperty: 'appeared_with_hub'
});
CALL gds.alpha.hits.mutate('marvel-character-graph',{
relationshipTypes: ['ENEMY_DIRECTED'],
hitsIterations: 50,
authProperty: 'appeared_with_auth',
hubProperty: 'appeared_with_hub'
});Lastly, we will use the Fast Random Projection (FastRP) embedding algorithm to create embedding vectors for each node, that will be used in one of our node classifications. Despite the fact that we will only be looking at a subset of this graph, namely X-Men and those who might be X-men or relate to them somehow, but we will compute the embeddings for the whole graph.
CALL gds.beta.fastRPExtended.write('marvel-character-graph',{
relationshipTypes:['APPEARS_WITH_UNDIRECTED'],
featureProperties: ['strength','fighting_skills','durability','speed','intelligence','appeared_with_pageRank','ally_pageRank','enemy_pageRank','appeared_with_betweenness','ally_betweenness','enemy_betweenness','appeared_with_hub','appeared_with_auth'], //14 node features
relationshipWeightProperty: 'times',
propertyDimension: 45,
embeddingDimension: 250,
iterationWeights: [0, 0, 1.0, 1.0],
normalizationStrength:0.05,
writeProperty: 'fastRP_Extended_Embedding'
})|
For more information on graph embeddings and how they can be used, see Applied Graph Embeddings. |
Finally, we can drop the marvel-character-graph to free up some memory via CALL gds.graph.drop('marvel-character-graph').
Running the node classification algorithm
Prior to the actual running of the node classification we must set up our training and testing graphs. There are a few things that we need to consider. First, we want to have roughly an equal number of X-Men to non-X-Men in our graph to prevent class imbalance. This means that first we will select all of the X-Men and set the property is_xman to identify these individuals:
MATCH (c:Character)-[:PART_OF_GROUP]-> (g:Group{name:'X-Men'})
SET c.is_xman=1, c:Model_Data;We see here that c.is_xman is set to an integer value of 1, which is required by the node classification algorithm to distinguish between the various classes.
Next, we need to identify characters that are not X-Men. There are many more non-X-Men characters that appear with the X-Men, so we will downsample these through the requirement to have a degree greater than zero while also using a random number to determine whether that character will be put into the non-X-Men set and set their class to the integer value of 0:
MATCH (c:Character)
WHERE NOT (c)-[:PART_OF_GROUP]->(:Group) WITH c
WHERE NOT (c)-[:APPEARED_WITH*2..3]-(:Character{is_xman:1})
AND apoc.node.degree(c)>0 WITH c
WHERE rand() < 0.2
SET c:Model_Data, c.is_xman=0;Finally, we will create a set of character that will be used for predictions after the model is trained:
MATCH (c:Character)
WHERE NOT (c:Model_Data)
SET c:Holdout_Data;Once we have done this, we will create an in-memory graph encompassing these characters, their properties, and the class to be predicted.
CALL gds.graph.create(
'marvel_model_data',
{
Character: {
label: 'Model_Data',
properties: {
fastRP_embedding:{property:'fastRP_Extended_Embedding', defaultValue:0},
strength:{property:'strength', defaultValue:0},
durability:{property:'durability', defaultValue:0},
intelligence:{property:'intelligence', defaultValue:0},
energy:{property:'energy', defaultValue:0},
speed:{property:'speed', defaultValue:0},
is_xman:{property:'is_xman', defaultValue:0}
}
},
Holdout_Character: {
label: 'Holdout_Data',
properties: {
fastRP_embedding:{property:'fastRP_Extended_Embedding', defaultValue:0},
strength:{property:'strength', defaultValue:0},
durability:{property:'durability', defaultValue:0},
intelligence:{property:'intelligence', defaultValue:0},
energy:{property:'energy', defaultValue:0},
speed:{property:'speed', defaultValue:0},
is_xman:{property:'is_xman', defaultValue:0}
}
}
}, {
APPEARED_WITH: {
type: 'APPEARED_WITH',
orientation: 'UNDIRECTED',
properties: ['times'],
aggregation: 'SINGLE'
}
});Observe that we have two character labels that are being put into this in-memory graph, namely Character and Holdout_Character. This ensures that we are not mixing up the characters that will be used in the validation after the model is fully trained.
First let’s train a simple model that only uses some character properties for the training process:
CALL gds.alpha.ml.nodeClassification.train('marvel_model_data', {
nodeLabels: ['Character'],
modelName: 'xmen-model-properties',
featureProperties: ['energy','speed','strength','durability','intelligence'],
targetProperty: 'is_xman',
metrics: ['F1_WEIGHTED','ACCURACY'],
holdoutFraction: 0.2,
validationFolds: 5,
randomSeed: 2,
params: [
{penalty: 0.0625, maxIterations: 1000},
{penalty: 0.125, maxIterations: 1000},
{penalty: 0.25, maxIterations: 1000},
{penalty: 0.5, maxIterations: 1000},
{penalty: 1.0, maxIterations: 1000},
{penalty: 2.0, maxIterations: 1000},
{penalty: 4.0, maxIterations: 1000}
]
}) YIELD modelInfo
RETURN
modelInfo.bestParameters AS winningModel,
modelInfo.metrics.F1_WEIGHTED.outerTrain AS trainGraphScore,
modelInfo.metrics.F1_WEIGHTED.test AS testGraphScoreIn this statement, we are training a model based on the node properties of energy, speed, strength, durability, and intelligence. The targetProperty is the thing we are trying to solve for; in this case we are trying to determine the node property is_xman (1 for an X-Man, 0 for everyone else). The model will be able to return the weighted F1 score and the accuracy, but it is important to note that only the first metric is used for the actual training. We see that the validation set represents 20% of the test graph with 5-fold cross-validation. Finally, we set a series of parameters that are used to evaluate the model. In this case, we have provided a series of penalties using the L2 norm with a given number of training iterations. The training algorithm will identify the optimal model given these parameters, which is returned in the final portion of the query along with the training and test F1 weighted scores.
When this is run on our dataset, we obtain the following results:
| "winningModel" | "trainingGraphScore" | "testGraphScore" |
|---|---|---|
{"maxIterations":1000,"penalty":0.0625} |
0.4696285981767071 |
0.44504748658690024 |
These scores are low, but this is not surprising. We provided a very minimal number of properties on which to train the model, a problem that is compounded by the fact the the graph itself is quite small. So instead, let’s train a new model using the FastRP embeddings.
CALL gds.alpha.ml.nodeClassification.train('marvel_model_data', {
nodeLabels: ['Character'],
modelName: 'xmen-model-fastRP',
featureProperties: ['fastRP_embedding'],
targetProperty: 'is_xman',
metrics: ['F1_WEIGHTED','ACCURACY'],
holdoutFraction: 0.2,
validationFolds: 5,
randomSeed: 2,
params: [
{penalty: 0.0625, maxIterations: 1000},
{penalty: 0.125, maxIterations: 1000},
{penalty: 0.25, maxIterations: 1000},
{penalty: 0.5, maxIterations: 1000},
{penalty: 1.0, maxIterations: 1000},
{penalty: 2.0, maxIterations: 1000},
{penalty: 4.0, maxIterations: 1000}
]
}) YIELD modelInfo
RETURN
modelInfo.bestParameters AS winningModel,
modelInfo.metrics.F1_WEIGHTED.outerTrain AS trainGraphScore,
modelInfo.metrics.F1_WEIGHTED.test AS testGraphScore|
Don’t forget that if you are not using the Enterprise Edition of the Graph Data Science library, you can only have a limited number of models in memory at any given time, so you must drop unused models via |
This is identical to our procedure before, however, we can see that we have replaced the featureProperties to be the FastRP embeddings. We would expect this model to perform better since the embedding process returns a vector embedding for each node that, in our case, is 250 elements long. In fact, we obtain the following results with the embeddings:
| "winningModel" | "trainingGraphScore" | "testGraphScore" |
|---|---|---|
{"maxIterations":1000,"penalty":0.0625} |
0.9623978269133772 |
0.857142851020408 |
Predictions with the model
Using the FastRP model, let’s inspect some predicted nodes. To do this, we first have to run the prediction algorithm, which we will then write to the nodes themselves:
CALL gds.alpha.ml.nodeClassification.predict.mutate('marvel_model_data', {
nodeLabels: ['Holdout_Character'], //filter out the character nodes
modelName: 'xmen-model-fastRP',
mutateProperty: 'predicted_xman',
predictedProbabilityProperty: 'predicted_xman_probability'
});
CALL gds.graph.writeNodeProperties(
'marvel_model_data',
['predicted_xman', 'predicted_xman_probability'],
['Holdout_Character']
);We now look at some of the predictions for characters that are labeled as X-Men. To do this, we run the following query:
MATCH (c:Character)
WHERE c.predicted_xman = 1 AND NOT c:Model_Data
RETURN c.name, c.aliases, c.predicted_xman, c.predicted_xman_probabilityc.predicted_xman returns the predicted class (in this case we are looking for characters that were labeled as X-Men by the model). The returned c.predicted_xman-probability gives the probability of each class, presented as a list where the first element is the probability of class 0 (not an X-Man) and the second element is the probability of class 1 (an X-Man). Our results will be as follows for the first returned character (with long alias list truncated for space):
| "c.name" | "c.aliases" | "c.predicted_xman" | "c.predicted_xman_probability" |
|---|---|---|---|
"Steve Rogers" |
"Steven Rogers, Brett Hendrick, Buck Jones, etc." |
1 |
[0.12884971201784812,0.8711502879821517] |
Examining Steve Rogers further, he is not actually an X-Man. However, in the graph we can see that he has many :APPEARED_WITH relationships with actual X-Men, which can be seen via:
MATCH (c:Character {name: 'Steve Rogers'})-[e]->(x:Character)-[:PART_OF_GROUP]->(g:Group {name: 'X-Men'})
RETURN c.name, e, x.nameIf we were to explore other characters returned in this list, we would see that they also have several relationships with true X-Men. We also will note that there are actual X-Men who were not linked in the original data with the X-Men group that are really X-Men (for example: Beast, Cyclops, and Charles Xavier).
Was this page helpful?