Tutorial: Build a Knowledge Graph using NLP and Ontologies
This guide shows how to build and query a Knowledge Graph of entities extracted using APOC NLP procedures and Ontologies extracted using neosemantics.
You should have a basic understanding of the property graph model. Having Neo4j Desktop downloaded and installed will allow you to code along with the examples.
Beginner
Introduction
In this tutorial we’re going to build a Software Knowledge Graph based on:
-
Articles taken from dev.to, a developer blogging platform, and the entities extracted (using NLP techniques) from those articles.
-
Software ontologies extracted from Wikidata, the free and open knowledge base that acts as central storage for the structured data of Wikipedia.
Once we’ve done that we’ll learn how to query the Knowledge Graph to find interesting insights that are enabled by combining NLP and Ontologies.
|
The queries and data used in this guide can be found in the neo4j-examples/nlp-knowledge-graph GitHub repository. |
Video
Jesús Barrasa and Mark Needham presented a talk based on this tutorial at the Neo4j Connections: Knowledge Graphs event on 25th August 2020. The video from the talk is available below:
Tools
We’re going to use a couple of plugin libraries in this tutorial, so you’ll need to install those if you want to follow along with the examples.
APOC

APOC (Awesome Procedures on Neo4j) is Neo4j’s standard library. It contains more than 450 procedures and functions providing functionality for utilities, conversions, graph updates, and more. We’re going to use this tool to scrape web pages and apply NLP techniques on text data.
We can install APOC from the plugins section of a database in the Neo4j Desktop:

We’ll also need to install the APOC NLP Dependencies jar from GitHub releases.
At the time of writing, the latest version of APOC is 4.0.0.18, so we need to download apoc-nlp-dependencies-4.0.0.18.jar from the 4.0.0.18 release page.
Once we’ve downloaded that file, we need to place it in the plugins directory:
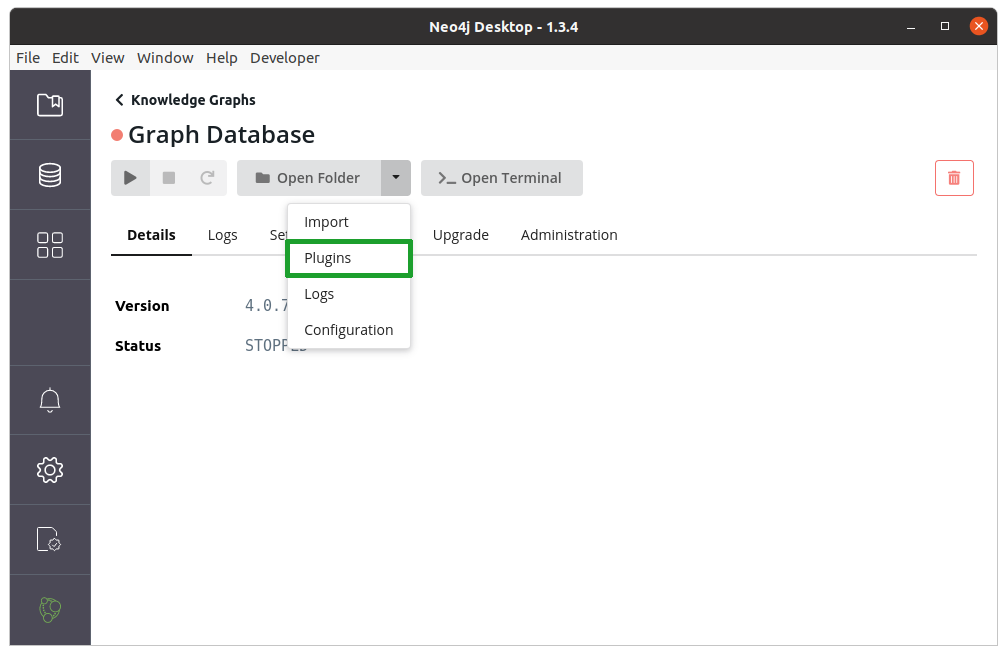
neosemantics (n10s)

neosemantics is a plugin that enables the use of RDF and its associated vocabularies like OWL, RDFS, SKOS, and others in Neo4j. We’re going to use this tool to import ontologies into Neo4j.
|
neosemantics only supports the Neo4j 4.0.x and 3.5.x series. It does not yet support the Neo4j 4.1.x series. |
We can install neosemantics by following the instructions in the project installation guide.
Both of these tools can be installed in Docker environments, and the project repository contains a docker-compose.yml file that shows how to do this.
What is a Knowledge Graph?
There are many different definitions of Knowledge Graphs. In this tutorial, the definition of a Knowledge Graph is a graph that contains the following:
- Facts
-
Instance data. This would include graph data imported from any data source and could be structured (e.g. JSON/XML) or semi structured (e.g. HTML)
- Explicit Knowledge
-
Explicit description of how instance data relates. This comes from ontologies, taxonomies, or any kind of metadata definition.
Importing Wikidata Ontologies
![]()
Wikidata is a free and open knowledge base that can be read and edited by both humans and machines. It acts as central storage for the structured data of its Wikimedia sister projects including Wikipedia, Wikivoyage, Wiktionary, Wikisource, and others.
Wikidata SPARQL API
Wikidata provides a SPARQL API that lets users query the data directly. The screenshot below shows an example of a SPARQL query along with the results from running that query:
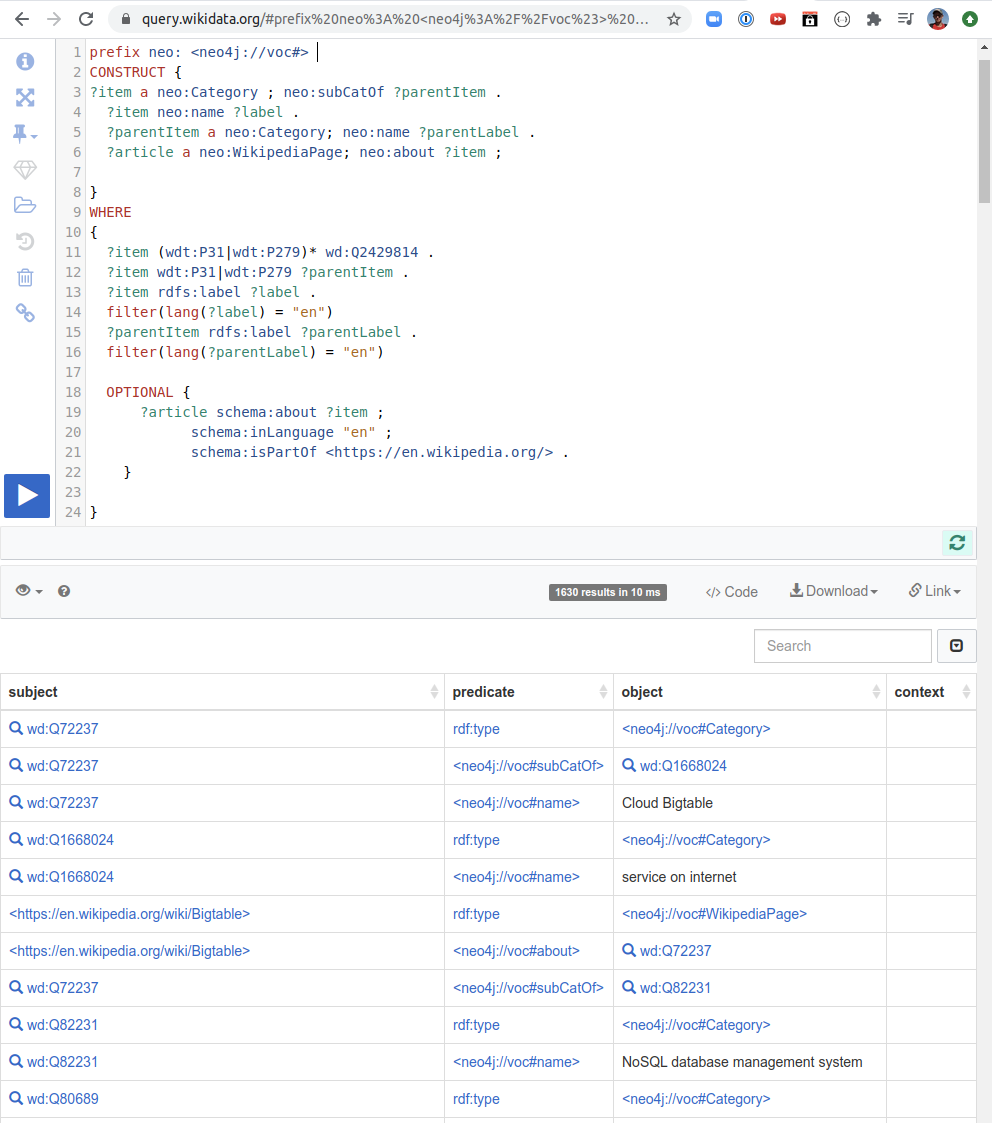
This query starts from the entity Q2429814 (Software System) and then transitively finds children of that entity as far as it can. If we run the query we get a stream of triples (subject, predicate, subject).
We’re now going to learn how to import Wikidata into Neo4j using neosemantics.
CREATE CONSTRAINT n10s_unique_uri ON (r:Resource) ASSERT r.uri IS UNIQUE;CALL n10s.graphconfig.init({handleVocabUris: "MAP"});call n10s.nsprefixes.add('neo','neo4j://voc#');
CALL n10s.mapping.add("neo4j://voc#subCatOf","SUB_CAT_OF");
CALL n10s.mapping.add("neo4j://voc#about","ABOUT");Now we’re going to import the Wikidata taxonomies.
We can get an importable URL directly from the Wikidata SPARQL API, by clicking on the Code button:

We then pass that URL to the n10s.rdf.import.fetch procedure, which will import the stream of triples into Neo4j.
The examples below contain queries that import taxonomies starting from Software Systems, Programming Languages, and Data Formats.
WITH "https://query.wikidata.org/sparql?query=prefix%20neo%3A%20%3Cneo4j%3A%2F%2Fvoc%23%3E%20%0A%23Cats%0A%23SELECT%20%3Fitem%20%3Flabel%20%0ACONSTRUCT%20%7B%0A%3Fitem%20a%20neo%3ACategory%20%3B%20neo%3AsubCatOf%20%3FparentItem%20.%20%20%0A%20%20%3Fitem%20neo%3Aname%20%3Flabel%20.%0A%20%20%3FparentItem%20a%20neo%3ACategory%3B%20neo%3Aname%20%3FparentLabel%20.%0A%20%20%3Farticle%20a%20neo%3AWikipediaPage%3B%20neo%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%0A%7D%0AWHERE%20%0A%7B%0A%20%20%3Fitem%20(wdt%3AP31%7Cwdt%3AP279)*%20wd%3AQ2429814%20.%0A%20%20%3Fitem%20wdt%3AP31%7Cwdt%3AP279%20%3FparentItem%20.%0A%20%20%3Fitem%20rdfs%3Alabel%20%3Flabel%20.%0A%20%20filter(lang(%3Flabel)%20%3D%20%22en%22)%0A%20%20%3FparentItem%20rdfs%3Alabel%20%3FparentLabel%20.%0A%20%20filter(lang(%3FparentLabel)%20%3D%20%22en%22)%0A%20%20%0A%20%20OPTIONAL%20%7B%0A%20%20%20%20%20%20%3Farticle%20schema%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AinLanguage%20%22en%22%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AisPartOf%20%3Chttps%3A%2F%2Fen.wikipedia.org%2F%3E%20.%0A%20%20%20%20%7D%0A%20%20%0A%7D" AS softwareSystemsUri
CALL n10s.rdf.import.fetch(softwareSystemsUri, 'Turtle' , { headerParams: { Accept: "application/x-turtle" } })
YIELD terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams
RETURN terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams;| terminationStatus | triplesLoaded | triplesParsed | namespaces | callParams |
|---|---|---|---|---|
"OK" |
1630 |
1630 |
NULL |
{headerParams: {Accept: "application/x-turtle"}} |
WITH "https://query.wikidata.org/sparql?query=prefix%20neo%3A%20%3Cneo4j%3A%2F%2Fvoc%23%3E%20%0A%23Cats%0A%23SELECT%20%3Fitem%20%3Flabel%20%0ACONSTRUCT%20%7B%0A%3Fitem%20a%20neo%3ACategory%20%3B%20neo%3AsubCatOf%20%3FparentItem%20.%20%20%0A%20%20%3Fitem%20neo%3Aname%20%3Flabel%20.%0A%20%20%3FparentItem%20a%20neo%3ACategory%3B%20neo%3Aname%20%3FparentLabel%20.%0A%20%20%3Farticle%20a%20neo%3AWikipediaPage%3B%20neo%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%0A%7D%0AWHERE%20%0A%7B%0A%20%20%3Fitem%20(wdt%3AP31%7Cwdt%3AP279)*%20wd%3AQ9143%20.%0A%20%20%3Fitem%20wdt%3AP31%7Cwdt%3AP279%20%3FparentItem%20.%0A%20%20%3Fitem%20rdfs%3Alabel%20%3Flabel%20.%0A%20%20filter(lang(%3Flabel)%20%3D%20%22en%22)%0A%20%20%3FparentItem%20rdfs%3Alabel%20%3FparentLabel%20.%0A%20%20filter(lang(%3FparentLabel)%20%3D%20%22en%22)%0A%20%20%0A%20%20OPTIONAL%20%7B%0A%20%20%20%20%20%20%3Farticle%20schema%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AinLanguage%20%22en%22%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AisPartOf%20%3Chttps%3A%2F%2Fen.wikipedia.org%2F%3E%20.%0A%20%20%20%20%7D%0A%20%20%0A%7D" AS programmingLanguagesUri
CALL n10s.rdf.import.fetch(programmingLanguagesUri, 'Turtle' , { headerParams: { Accept: "application/x-turtle" } })
YIELD terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams
RETURN terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams;| terminationStatus | triplesLoaded | triplesParsed | namespaces | callParams |
|---|---|---|---|---|
"OK" |
9376 |
9376 |
NULL |
{headerParams: {Accept: "application/x-turtle"}} |
WITH "https://query.wikidata.org/sparql?query=prefix%20neo%3A%20%3Cneo4j%3A%2F%2Fvoc%23%3E%20%0A%23Cats%0A%23SELECT%20%3Fitem%20%3Flabel%20%0ACONSTRUCT%20%7B%0A%3Fitem%20a%20neo%3ACategory%20%3B%20neo%3AsubCatOf%20%3FparentItem%20.%20%20%0A%20%20%3Fitem%20neo%3Aname%20%3Flabel%20.%0A%20%20%3FparentItem%20a%20neo%3ACategory%3B%20neo%3Aname%20%3FparentLabel%20.%0A%20%20%3Farticle%20a%20neo%3AWikipediaPage%3B%20neo%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%0A%7D%0AWHERE%20%0A%7B%0A%20%20%3Fitem%20(wdt%3AP31%7Cwdt%3AP279)*%20wd%3AQ24451526%20.%0A%20%20%3Fitem%20wdt%3AP31%7Cwdt%3AP279%20%3FparentItem%20.%0A%20%20%3Fitem%20rdfs%3Alabel%20%3Flabel%20.%0A%20%20filter(lang(%3Flabel)%20%3D%20%22en%22)%0A%20%20%3FparentItem%20rdfs%3Alabel%20%3FparentLabel%20.%0A%20%20filter(lang(%3FparentLabel)%20%3D%20%22en%22)%0A%20%20%0A%20%20OPTIONAL%20%7B%0A%20%20%20%20%20%20%3Farticle%20schema%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AinLanguage%20%22en%22%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AisPartOf%20%3Chttps%3A%2F%2Fen.wikipedia.org%2F%3E%20.%0A%20%20%20%20%7D%0A%20%20%0A%7D" AS dataFormatsUri
CALL n10s.rdf.import.fetch(dataFormatsUri, 'Turtle' , { headerParams: { Accept: "application/x-turtle" } })
YIELD terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams
RETURN terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams;| terminationStatus | triplesLoaded | triplesParsed | namespaces | callParams |
|---|---|---|---|---|
"OK" |
514 |
514 |
NULL |
{headerParams: {Accept: "application/x-turtle"}} |
Viewing the taxonomy
Let’s have a look at what’s been imported. We can get an overview of the contents of our database by running the following query:
CALL apoc.meta.stats()
YIELD labels, relTypes, relTypesCount
RETURN labels, relTypes, relTypesCount;| labels | relTypes | relTypesCount |
|---|---|---|
{Category: 2308, _NsPrefDef: 1, _MapNs: 1, Resource: 3868, _MapDef: 2, WikipediaPage: 1560, _GraphConfig: 1} |
{ |
{SUB_CAT_OF: 7272, _IN: 2, ABOUT: 3120} |
Any labels or relationships types that have a _prefix can be ignores as they represent meta data created by the n10s library.
We can see that we’ve imported over 2,000 Category nodes and 1,700 WikipediaPage nodes.
Every node that we create using n10s will have a Resource label, which is why we have over 4,000 nodes with this label.
We also have more than 7,000 SUB_CAT_OF relationship types connecting the Category nodes and 3,000 ABOUT relationship types connecting the WikipediaPage nodes to the Category nodes.
Let’s now have a look at some of the actual data that we’ve imported. We can look at the sub categories of the version control node by running the following query:
MATCH path = (c:Category {name: "version control system"})<-[:SUB_CAT_OF*]-(child)
RETURN path
LIMIT 25;
So far, so good!
Importing dev.to articles
dev.to is a developer blogging platform and contains articles on a variety of topics, including NoSQL databases, JavaScript frameworks, the latest AWS API, chatbots, and more. A screenshot of the home page is shown below:

We’re going to import some articles from dev.to into Neo4j.
articles.csv contains a list of 30 articles of interest.
We can query this file using Cypher’s LOAD CSV clause:
LOAD CSV WITH HEADERS FROM 'https://github.com/neo4j-examples/nlp-knowledge-graph/raw/master/import/articles.csv' AS row
RETURN row
LIMIT 10;| row |
|---|
{uri: "https://dev.to/lirantal/securing-a-nodejs—rethinkdb—tls-setup-on-docker-containers"} |
{uri: "https://dev.to/setevoy/neo4j-running-in-kubernetes-e4p"} |
{uri: "https://dev.to/divyanshutomar/introduction-to-redis-3m2a"} |
{uri: "https://dev.to/zaiste/15-git-commands-you-may-not-know-4a8j"} |
{uri: "https://dev.to/alexjitbit/removing-files-from-mercurial-history-1b15"} |
{uri: "https://dev.to/michelemauro/atlassian-sunsetting-mercurial-support-in-bitbucket-2ga9"} |
{uri: "https://dev.to/shirou/back-up-prometheus-records-to-s3-via-kinesis-firehose-54l4"} |
{uri: "https://dev.to/ionic/farewell-phonegap-reflections-on-my-hybrid-app-development-journey-10dh"} |
{uri: "https://dev.to/rootsami/rancher-kubernetes-on-openstack-using-terraform-1ild"} |
{uri: "https://dev.to/jignesh_simform/comparing-mongodb—mysql-bfa"} |
We’re going to use APOC’s apoc.load.html procedure to scrape the interesting information from each of these URIs.
Let’s first see how to use this procedure on a single article, as shown in the following query:
(1)
MERGE (a:Article {uri: "https://dev.to/lirantal/securing-a-nodejs--rethinkdb--tls-setup-on-docker-containers"})
WITH a
(2)
CALL apoc.load.html(a.uri, {
body: 'body div.spec__body p',
title: 'h1',
time: 'time'
})
YIELD value
UNWIND value.body AS item
(3)
WITH a,
apoc.text.join(collect(item.text), '') AS body,
value.title[0].text AS title,
value.time[0].attributes.datetime AS date
(4)
SET a.body = body , a.title = title, a.datetime = datetime(date)
RETURN a;| 1 | Create node with Article label and uri property if it doesn’t already exist |
| 2 | Scrape data from the URI using the provided CSS selectors |
| 3 | Post processing of the values returned from scrapping the URI |
| 4 | Update node with body, title, and datetime properties |
| a |
|---|
(:Article {processed: TRUE, datetime: 2017-08-21T18:41:06Z, title: "Securing a Node.js + RethinkDB + TLS setup on Docker containers", body: "We use RethinkDB at work across different projects. It isn’t used for any sort of big-data applications, but rather as a NoSQL database, which spices things up with real-time updates, and relational tables support.RethinkDB features an officially supported Node.js driver, as well as a community-maintained driver as well called rethinkdbdash which is promises-based, and provides connection pooling. There is also a database migration tool called rethinkdb-migrate that aids in managing database changes such as schema changes, database seeding, tear up and tear down capabilities.We’re going to use the official RethinkDB docker image from the docker hub and make use of docker-compose.yml to spin it up (later on you can add additional services to this setup).A fair example for docker-compose.yml:The compose file mounts a local tls directory as a mapped volume inside the container. The tls/ directory will contain our cert files, and the compose file is reflecting this.To setup a secure connection we need to facilitate it using certificates so an initial technical step:Important notes:Update the compose file to include a command configuration that starts the RethinkDB process with all the required SSL configurationImportant notes:You’ll notice there isn’t any cluster related configuration but you can add them as well if you need to so they can join the SSL connection: — cluster-tls — cluster-tls-key /tls/key.pem — cluster-tls-cert /tls/cert.pem — cluster-tls-ca /tls/ca.pemThe RethinkDB drivers support an ssl optional object which either sets the certificate using the ca property, or sets the rejectUnauthorized property to accept or reject self-signed certificates when connecting. A snippet for the ssl configuration to pass to the driver:Now that the connection is secured, it only makes sense to connect using a user/password which are not the default.To set it up, update the compose file to also include the — initial-password argument so you can set the default admin user’s password. For example:Of course you need to append this argument to the rest of the command line options in the above compose file.Now, update the Node.js driver settings to use a user and password to connect:Congratulations! You’re now eligible to “Ready for Production stickers.Don’t worry, I already mailed them to your address.", uri: "https://dev.to/lirantal/securing-a-nodejs—rethinkdb—tls-setup-on-docker-containers"}) |
Now we’re going to import the other articles.
We’ll use the apoc.periodic.iterate procedure so that we can parallelise this process.
This procedure takes in a data driven statement and an operation statement:
-
The data driven statement contains a stream of items to process, which will be the stream of URIs.
-
The operation statement defines what to do to each of these items, which will be to call
apoc.load.htmland create nodes with theArticlelabel.
The final parameter is for providing config. We’re going to tell the procedure to process these items in batches of 5 that can be run concurrently.
We can see the call to the procedure in the following example:
CALL apoc.periodic.iterate(
"LOAD CSV WITH HEADERS FROM 'https://github.com/neo4j-examples/nlp-knowledge-graph/raw/master/import/articles.csv' AS row
RETURN row",
"MERGE (a:Article {uri: row.uri})
WITH a
CALL apoc.load.html(a.uri, {
body: 'body div.spec__body p',
title: 'h1',
time: 'time'
})
YIELD value
UNWIND value.body AS item
WITH a,
apoc.text.join(collect(item.text), '') AS body,
value.title[0].text AS title,
value.time[0].attributes.datetime AS date
SET a.body = body , a.title = title, a.datetime = datetime(date)",
{batchSize: 5, parallel: true}
)
YIELD batches, total, timeTaken, committedOperations
RETURN batches, total, timeTaken, committedOperations;| batches | total | timeTaken | committedOperations |
|---|---|---|---|
7 |
32 |
15 |
32 |
We now have two disconnected sub graphs, which we can see in the diagram below:

On the left we have the Wikidata taxonomy graph, which represents the explicit knowledge in our Knowledge Graph. And on the right we have the articles graph, which represents the facts in our Knowledge Graph. We want to join these two graphs together, which we will do using NLP techniques.
Article Entity Extraction

In April 2020, the APOC standard library added procedures that wrap the NLP APIs of each of the big cloud providers - AWS, GCP, and Azure. These procedures extract text from a node property and then send that text to APIs that extract entities, key phrases, categories, or sentiment.
We’re going to use the GCP Entity Extraction procedures on our articles. The GCP NLP API returns Wikipedia pages for entities where those pages exist.
Before we do that we’ll need to create an API key that has access to the Natural Language API. Assuming that we’re already created a GCP account, we can generate a key by following the instructions at console.cloud.google.com/apis/credentials. Once we’ve created a key, we’ll create a parameter that contains it:
:params key => ("<insert-key-here>")We’re going to use the apoc.nlp.gcp.entities.stream procedure, which will return a stream of entities found for the text content contained in a node property.
Before running this procedure against all of the articles, let’s run it against one of them to see what data is returned:
MATCH (a:Article {uri: "https://dev.to/lirantal/securing-a-nodejs--rethinkdb--tls-setup-on-docker-containers"})
CALL apoc.nlp.gcp.entities.stream(a, {
nodeProperty: 'body',
key: $key
})
YIELD node, value
SET node.processed = true
WITH node, value
UNWIND value.entities AS entity
RETURN entity
LIMIT 5;| entity |
|---|
{name: "RethinkDB", salience: 0.47283632, metadata: {mid: "/m/0134hdhv", wikipedia_url: "https://en.wikipedia.org/wiki/RethinkDB"}, type: "ORGANIZATION", mentions: [{type: "PROPER", text: {content: "RethinkDB", beginOffset: -1}}, {type: "PROPER", text: {content: "RethinkDB", beginOffset: -1}}, {type: "PROPER", text: {content: "RethinkDB", beginOffset: -1}}, {type: "PROPER", text: {content: "RethinkDB", beginOffset: -1}}, {type: "PROPER", text: {content: "pemThe RethinkDB", beginOffset: -1}}]} |
{name: "connection", salience: 0.04166339, metadata: {}, type: "OTHER", mentions: [{type: "COMMON", text: {content: "connection", beginOffset: -1}}, {type: "COMMON", text: {content: "connection", beginOffset: -1}}]} |
{name: "work", salience: 0.028608896, metadata: {}, type: "OTHER", mentions: [{type: "COMMON", text: {content: "work", beginOffset: -1}}]} |
{name: "projects", salience: 0.028608896, metadata: {}, type: "OTHER", mentions: [{type: "COMMON", text: {content: "projects", beginOffset: -1}}]} |
{name: "database", salience: 0.01957906, metadata: {}, type: "OTHER", mentions: [{type: "COMMON", text: {content: "database", beginOffset: -1}}]} |
Each row contains a name property that describes the entity.
salience is an indicator of the importance or centrality of that entity to the entire document text.
Some entities also contain a Wikipedia URL, which is found via the metadata.wikipedia_url key.
The first entity, RethinkDB, is the only entity in this list that has such a URL.
We’re going to filter the rows returned to only include ones that have a Wikipedia URL and we’ll then connect the Article nodes to the WikipediaPage nodes that have that URL.
Let’s have a look at how we’re going to do this for one article:
MATCH (a:Article {uri: "https://dev.to/lirantal/securing-a-nodejs--rethinkdb--tls-setup-on-docker-containers"})
CALL apoc.nlp.gcp.entities.stream(a, {
nodeProperty: 'body',
key: $key
})
(1)
YIELD node, value
SET node.processed = true
WITH node, value
UNWIND value.entities AS entity
(2)
WITH entity, node
WHERE not(entity.metadata.wikipedia_url is null)
(3)
MERGE (page:Resource {uri: entity.metadata.wikipedia_url})
SET page:WikipediaPage
(4)
MERGE (node)-[:HAS_ENTITY]->(page)| 1 | node is the article and value contains the extracted entities |
| 2 | Only include entities that have a Wikipedia URL |
| 3 | Find a node that matches the Wikipedia URL. Create one if it doesn’t already exist. |
| 4 | Create a HAS_ENTITY relationship between the Article node and WikipediaPage |
We can see how running this query connects the article and taxonomy sub graphs by looking at the following Neo4j Browser visualization:

Now we can run the entity extraction technique over the rest of the articles with help from the apoc.periodic.iterate procedure again:
CALL apoc.periodic.iterate(
"MATCH (a:Article)
WHERE not(exists(a.processed))
RETURN a",
"CALL apoc.nlp.gcp.entities.stream([item in $_batch | item.a], {
nodeProperty: 'body',
key: $key
})
YIELD node, value
SET node.processed = true
WITH node, value
UNWIND value.entities AS entity
WITH entity, node
WHERE not(entity.metadata.wikipedia_url is null)
MERGE (page:Resource {uri: entity.metadata.wikipedia_url})
SET page:WikipediaPage
MERGE (node)-[:HAS_ENTITY]->(page)",
{batchMode: "BATCH_SINGLE", batchSize: 10, params: {key: $key}})
YIELD batches, total, timeTaken, committedOperations
RETURN batches, total, timeTaken, committedOperations;| batches | total | timeTaken | committedOperations |
|---|---|---|---|
4 |
31 |
29 |
31 |
Querying the Knowledge Graph
It’s now time to query the Knowledge Graph.
Semantic Search
The first query that we’re going to do is semantic search.
The n10s.inference.nodesInCategory procedure lets us search from a top level category, finding all its transitive sub categories, and then returns nodes attached to any of those categories.
In our graph the nodes connected to category nodes are WikipediaPage nodes.
We’ll therefore need to add an extra MATCH clause to our query to find the connected articles via the HAS_ENTITY relationship type.
We can see how to do this in the following query:
MATCH (c:Category {name: "NoSQL database management system"})
CALL n10s.inference.nodesInCategory(c, {
inCatRel: "ABOUT",
subCatRel: "SUB_CAT_OF"
})
YIELD node
MATCH (node)<-[:HAS_ENTITY]-(article)
RETURN article.uri AS uri, article.title AS title, article.datetime AS date,
collect(n10s.rdf.getIRILocalName(node.uri)) as explicitTopics
ORDER BY date DESC
LIMIT 5;| uri | title | date | explicitTopics |
|---|---|---|---|
"https://dev.to/arthurolga/newsql-an-implementation-with-google-spanner-2a86" |
"NewSQL: An Implementation with Google Spanner" |
2020-08-10T16:01:25Z |
["NoSQL"] |
"https://dev.to/goaty92/designing-tinyurl-it-s-more-complicated-than-you-think-2a48" |
"Designing TinyURL: it’s more complicated than you think" |
2020-08-10T10:21:05Z |
["Apache_ZooKeeper"] |
"https://dev.to/nipeshkc7/dynamodb-the-basics-360g" |
"DynamoDB: the basics" |
2020-06-02T04:09:36Z |
["NoSQL", "Amazon_DynamoDB"] |
"https://dev.to/subhransu/realtime-chat-app-using-kafka-springboot-reactjs-and-websockets-lc" |
"Realtime Chat app using Kafka, SpringBoot, ReactJS, and WebSockets" |
2020-04-25T23:17:22Z |
["Apache_ZooKeeper"] |
"https://dev.to/codaelux/running-dynamodb-offline-4k1b" |
"How to run DynamoDB Offline" |
2020-03-23T21:48:31Z |
["NoSQL", "Amazon_DynamoDB"] |
Although we’ve searched for NoSQL, we can see from the results that a couple of articles don’t link directly to that category. For example, we have a couple of articles about Apache Zookeeper. We can see how this category is connected to NoSQL by writing the following query:
match path = (c:WikipediaPage)-[:ABOUT]->(category)-[:SUB_CAT_OF*]->(:Category {name: "NoSQL database management system"})
where c.uri contains "Apache_ZooKeeper"
RETURN path;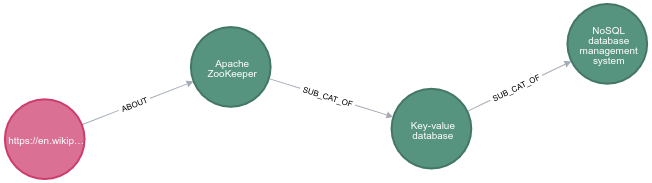
So Apache Zookeeper is actually a couple of levels away from the NoSQL category.
Similar Articles
Another thing that we can do with our Knowledge Graph is find similar articles based on the entities that articles have in common. The simplest version of this query would be to find other articles that share common entities, as shown in the following query:
MATCH (a:Article {uri: "https://dev.to/qainsights/performance-testing-neo4j-database-using-bolt-protocol-in-apache-jmeter-1oa9"}),
path = (a)-[:HAS_ENTITY]->(wiki)-[:ABOUT]->(cat),
otherPath = (wiki)<-[:HAS_ENTITY]-(other)
return path, otherPath;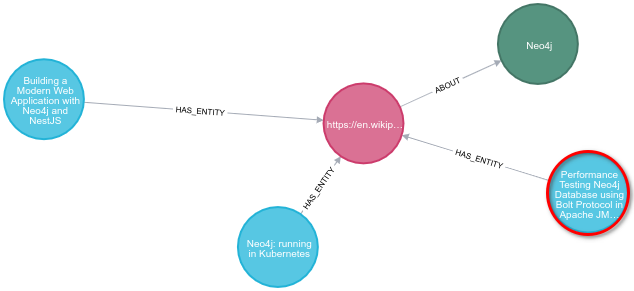
The Neo4j performance testing article is about Neo4j, and there are two other Neo4j articles that we could recommend to a reader that liked this article.
We can also use the category taxonomy in our query. We can find articles that share a common parent category by writing the following query:
MATCH (a:Article {uri: "https://dev.to/qainsights/performance-testing-neo4j-database-using-bolt-protocol-in-apache-jmeter-1oa9"}),
entityPath = (a)-[:HAS_ENTITY]->(wiki)-[:ABOUT]->(cat),
path = (cat)-[:SUB_CAT_OF]->(parent)<-[:SUB_CAT_OF]-(otherCat),
otherEntityPath = (otherCat)<-[:ABOUT]-(otherWiki)<-[:HAS_ENTITY]-(other)
RETURN other.title, other.uri,
[(other)-[:HAS_ENTITY]->()-[:ABOUT]->(entity) | entity.name] AS otherCategories,
collect([node in nodes(path) | node.name]) AS pathToOther;| other.title | other.uri | otherCategories | pathToOther |
|---|---|---|---|
"Couchbase GeoSearch with ASP.NET Core" |
"https://dev.to/ahmetkucukoglu/couchbase-geosearch-with-asp-net-core-i04" |
["ASP.NET", "Couchbase Server"] |
[["Neo4j", "proprietary software", "Couchbase Server"], ["Neo4j", "free software", "ASP.NET"], ["Neo4j", "free software", "Couchbase Server"]] |
"The Ultimate Postgres vs MySQL Blog Post" |
"https://dev.to/dmfay/the-ultimate-postgres-vs-mysql-blog-post-1l5f" |
["YAML", "Python", "JavaScript", "NoSQL database management system", "Structured Query Language", "JSON", "Extensible Markup Language", "comma-separated values", "PostgreSQL", "MySQL", "Microsoft SQL Server", "MongoDB", "MariaDB"] |
[["Neo4j", "proprietary software", "Microsoft SQL Server"], ["Neo4j", "free software", "PostgreSQL"]] |
"5 Best courses to learn Apache Kafka in 2020" |
"https://dev.to/javinpaul/5-best-courses-to-learn-apache-kafka-in-2020-584h" |
["Java", "Scratch", "Scala", "Apache ZooKeeper"] |
[["Neo4j", "free software", "Scratch"], ["Neo4j", "free software", "Apache ZooKeeper"]] |
"Building a Modern Web Application with Neo4j and NestJS" |
"https://dev.to/adamcowley/building-a-modern-web-application-with-neo4j-and-nestjs-38ih" |
["TypeScript", "JavaScript", "Neo4j"] |
[["Neo4j", "free software", "TypeScript"]] |
"Securing a Node.js + RethinkDB + TLS setup on Docker containers" |
"https://dev.to/lirantal/securing-a-nodejs—rethinkdb—tls-setup-on-docker-containers" |
["NoSQL database management system", "RethinkDB"] |
[["Neo4j", "free software", "RethinkDB"]] |
Note that in this query we’ll also returning the path from the initial article to the other article. So for "Couchbase GeoSearch with ASP.NET Core", there is a path that goes from the initial article to the Neo4j category, from there to the proprietary software category, which is also a parent of the Couchbase Server Category, which the "Couchbase GeoSearch with ASP.NET Core" article is connected to.
This shows off another nice feature of Knowledge Graphs - as well as making a recommendation, it’s easy to explain why it was made as well.
Adding a custom ontology
We might not consider proprietary software to be a very good measure of similarity between two technology products. It would be unlikely that we’re looking for similar articles based on this type of similarity.
But a common way that software products are connected is via technology stacks. We could therefore create our own ontology containing some of these stacks.
nsmntx.org/2020/08/swStacks contains an ontology for the GRANDstack, MEAN Stack, and LAMP Stack. Before we import this ontology, let’s setup some mappings in n10s:
CALL n10s.nsprefixes.add('owl','http://www.w3.org/2002/07/owl#');
CALL n10s.nsprefixes.add('rdfs','http://www.w3.org/2000/01/rdf-schema#');
CALL n10s.mapping.add("http://www.w3.org/2000/01/rdf-schema#subClassOf","SUB_CAT_OF");
CALL n10s.mapping.add("http://www.w3.org/2000/01/rdf-schema#label","name");
CALL n10s.mapping.add("http://www.w3.org/2002/07/owl#Class","Category");And now we can preview the import on the ontology by running the following query:
CALL n10s.rdf.preview.fetch("http://www.nsmntx.org/2020/08/swStacks","Turtle");
It looks good, so let’s import it by running the following query:
CALL n10s.rdf.import.fetch("http://www.nsmntx.org/2020/08/swStacks","Turtle")
YIELD terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams
RETURN terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams;| terminationStatus | triplesLoaded | triplesParsed | namespaces | callParams |
|---|---|---|---|---|
"OK" |
58 |
58 |
NULL |
{} |
We can now re-run the similarity query, which will now return the following results:
| other.title | other.uri | otherCategories | pathToOther |
|---|---|---|---|
"A Beginner’s Guide to GraphQL" |
"https://dev.to/leonardomso/a-beginners-guide-to-graphql-3kjj" |
["GraphQL", "JavaScript"] |
[["Neo4j", "GRAND Stack", "GraphQL"]] |
"Learn how YOU can build a Serverless GraphQL API on top of a Microservice architecture, part I" |
"https://dev.to/azure/learn-how-you-can-build-a-serverless-graphql-api-on-top-of-a-microservice-architecture-233g" |
["Node.js", "GraphQL"] |
[["Neo4j", "GRAND Stack", "GraphQL"]] |
"The Ultimate Postgres vs MySQL Blog Post" |
"https://dev.to/dmfay/the-ultimate-postgres-vs-mysql-blog-post-1l5f" |
["Structured Query Language", "Extensible Markup Language", "PostgreSQL", "MariaDB", "JSON", "MySQL", "Microsoft SQL Server", "MongoDB", "comma-separated values", "JavaScript", "YAML", "Python", "NoSQL database management system"] |
[["Neo4j", "proprietary software", "Microsoft SQL Server"], ["Neo4j", "free software", "PostgreSQL"]] |
"Couchbase GeoSearch with ASP.NET Core" |
"https://dev.to/ahmetkucukoglu/couchbase-geosearch-with-asp-net-core-i04" |
["ASP.NET", "Couchbase Server"] |
[["Neo4j", "proprietary software", "Couchbase Server"], ["Neo4j", "free software", "ASP.NET"], ["Neo4j", "free software", "Couchbase Server"]] |
"Building a Modern Web Application with Neo4j and NestJS" |
"https://dev.to/adamcowley/building-a-modern-web-application-with-neo4j-and-nestjs-38ih" |
["JavaScript", "TypeScript", "Neo4j"] |
[["Neo4j", "free software", "TypeScript"]] |
This time we’ve now got a couple of extra articles at the top about GraphQL, which is one of the tools in the GRANDstack, of which Neo4j is also a part.
Was this page helpful?