How-To: Import CSV Data with Neo4j Desktop
You will learn how to import data from CSV files to a Neo4j graph database using the Neo4j Desktop application. This tutorial is designed for you to follow along and step through the process.
This guide builds upon the basic concepts discussed in earlier guides. You should be familiar with the following:
You should also have downloaded Neo4j Desktop and be familiar with navigating the application, as well as creating and starting a database.
Intermediate
Neo4j Desktop Import
Neo4j Desktop provides a user-friendly interface for starting and creating Neo4j instances, adding or removing plugins, changing configurations, and other functionality. It also includes some shortcuts and easy access for importing files (such as CSVs) into Neo4j.
In this guide, you will work with a zipped folder containing three CSV files and import the data to a graph with Neo4j Desktop. The CSV files contain data for products, orders, and order line items. You will look at the data in the files later in this guide.
1. Creating and starting the Neo4j instance
If you already know how to create a project, create a Neo4j instance (DBMS), and start the DBMS, you can skip to Step 2.
When you open Neo4j Desktop for the first time you will see a Neo4j Primer Project with the Movie Database already started as shown here:
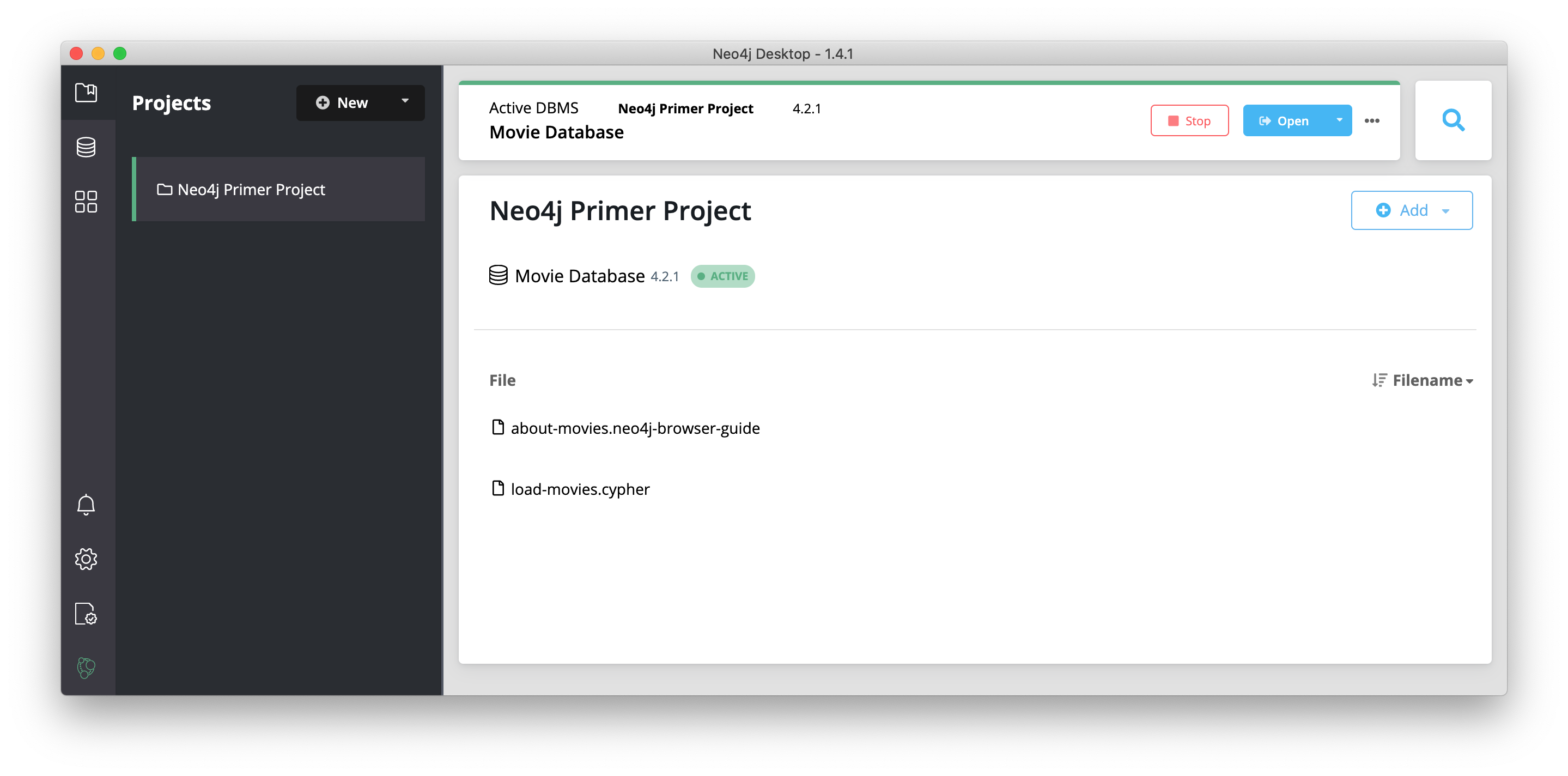
You can use this already-started DBMS if you want to begin learning about using Neo4j and Cypher. For your development, you typically create one or more projects where a project can contain one or more DBMSs.
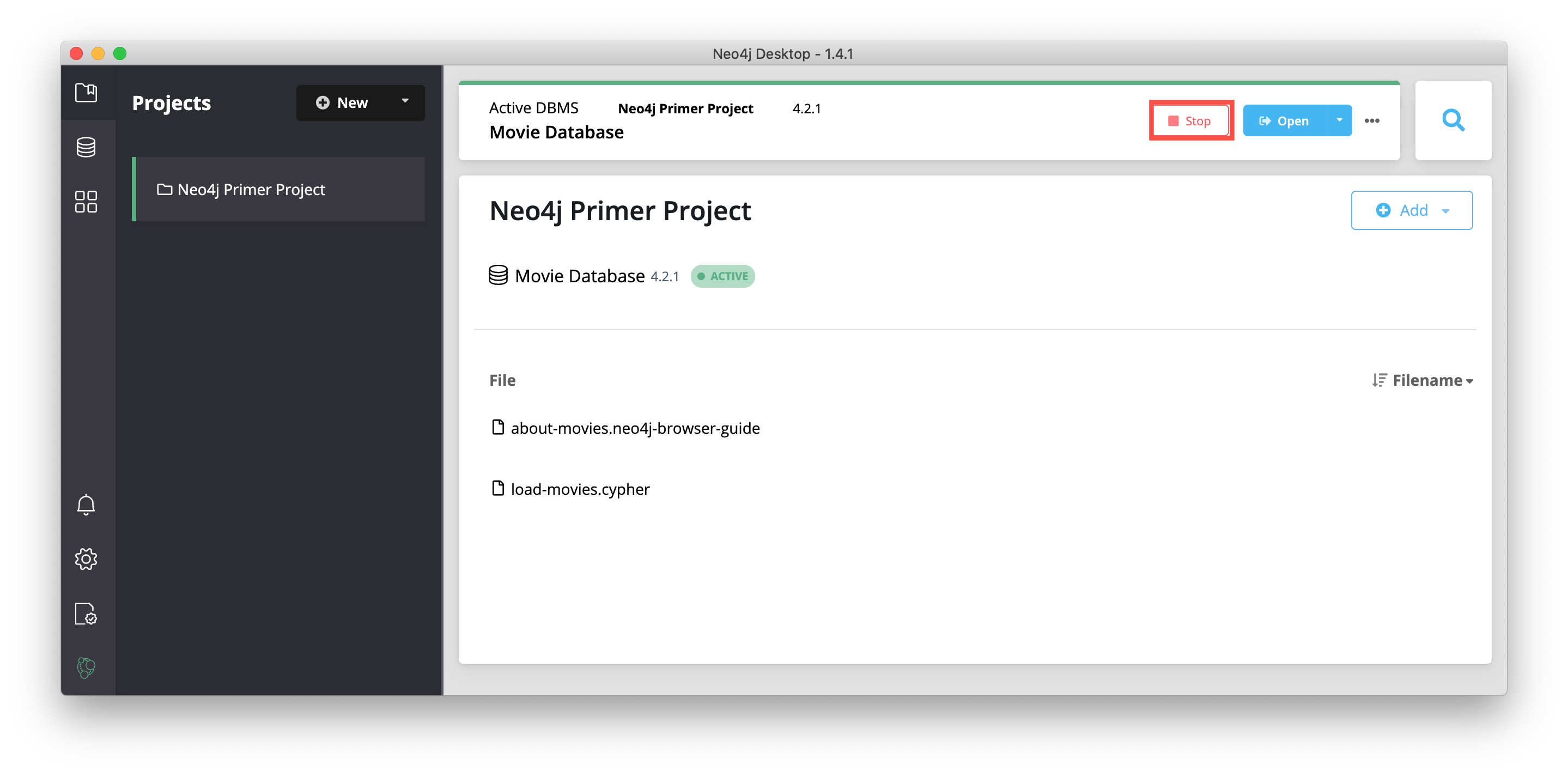
Next, you will create a new project in Neo4j Desktop. You can only have a single DBMS running, so you must first stop the DBMS that is started by clicking the Stop button:
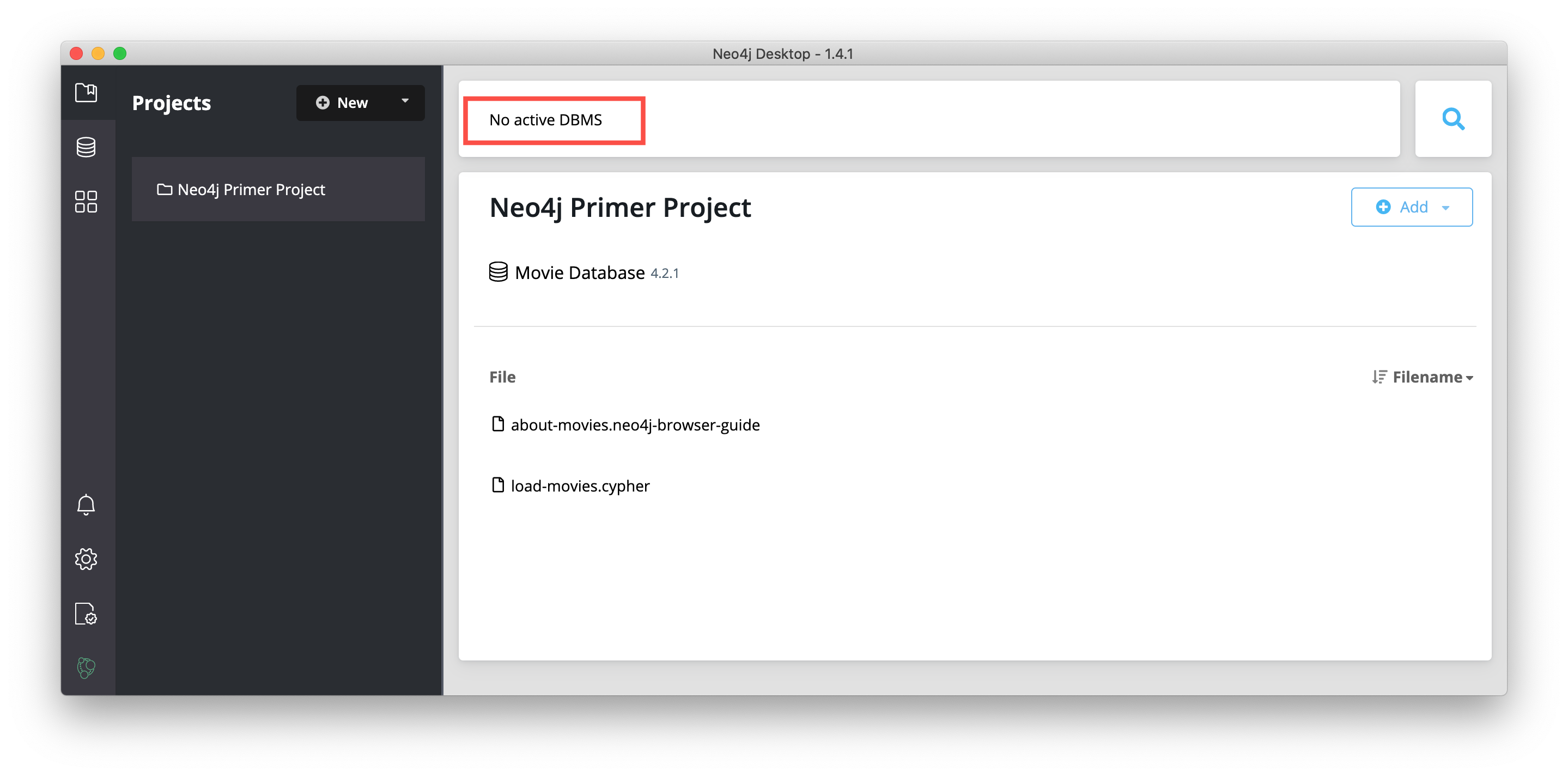
You should now see that there is no active DBMS:
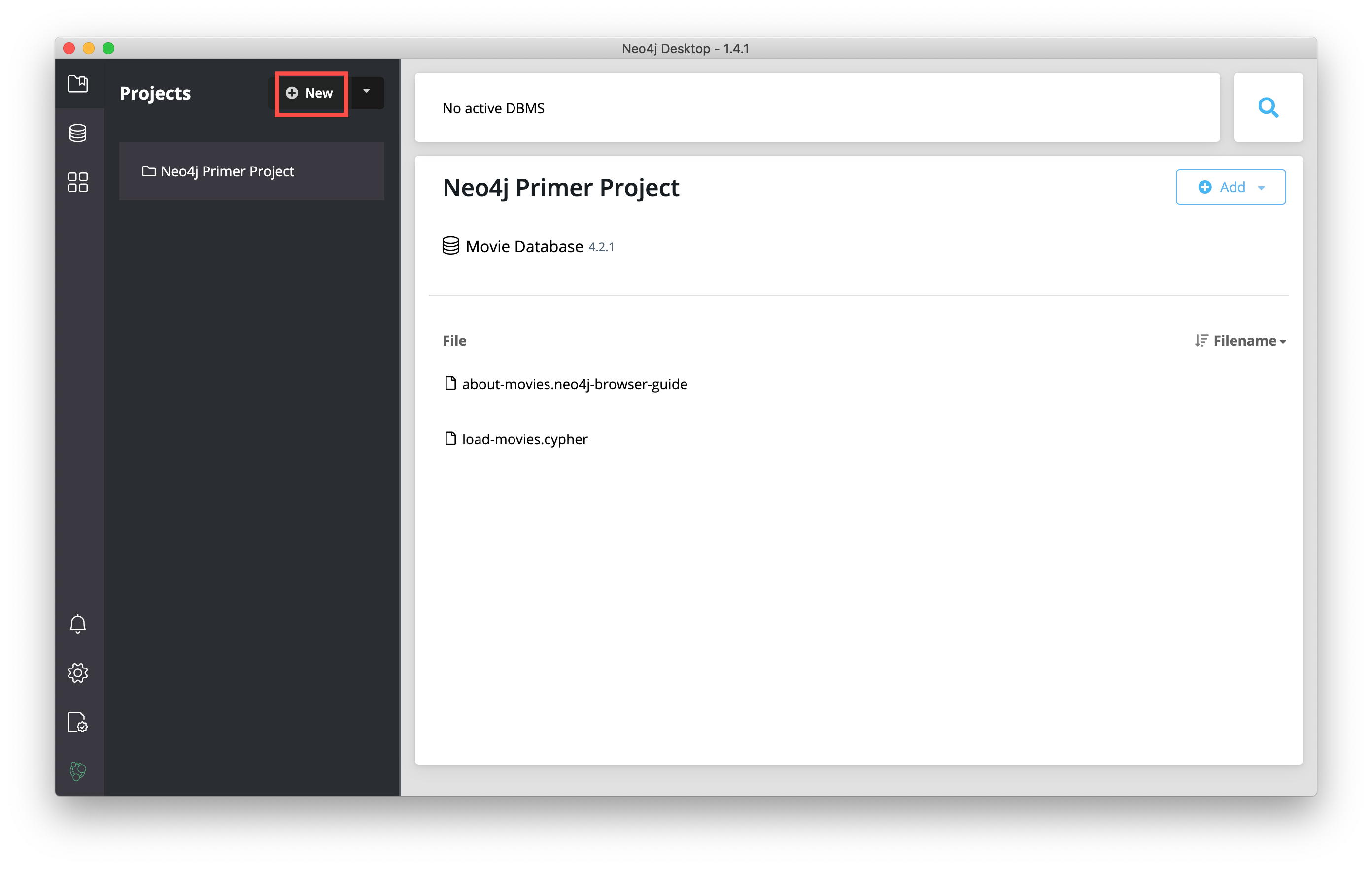
Add a new project by clicking New at the top of the sidebar:
This creates a project named Project:
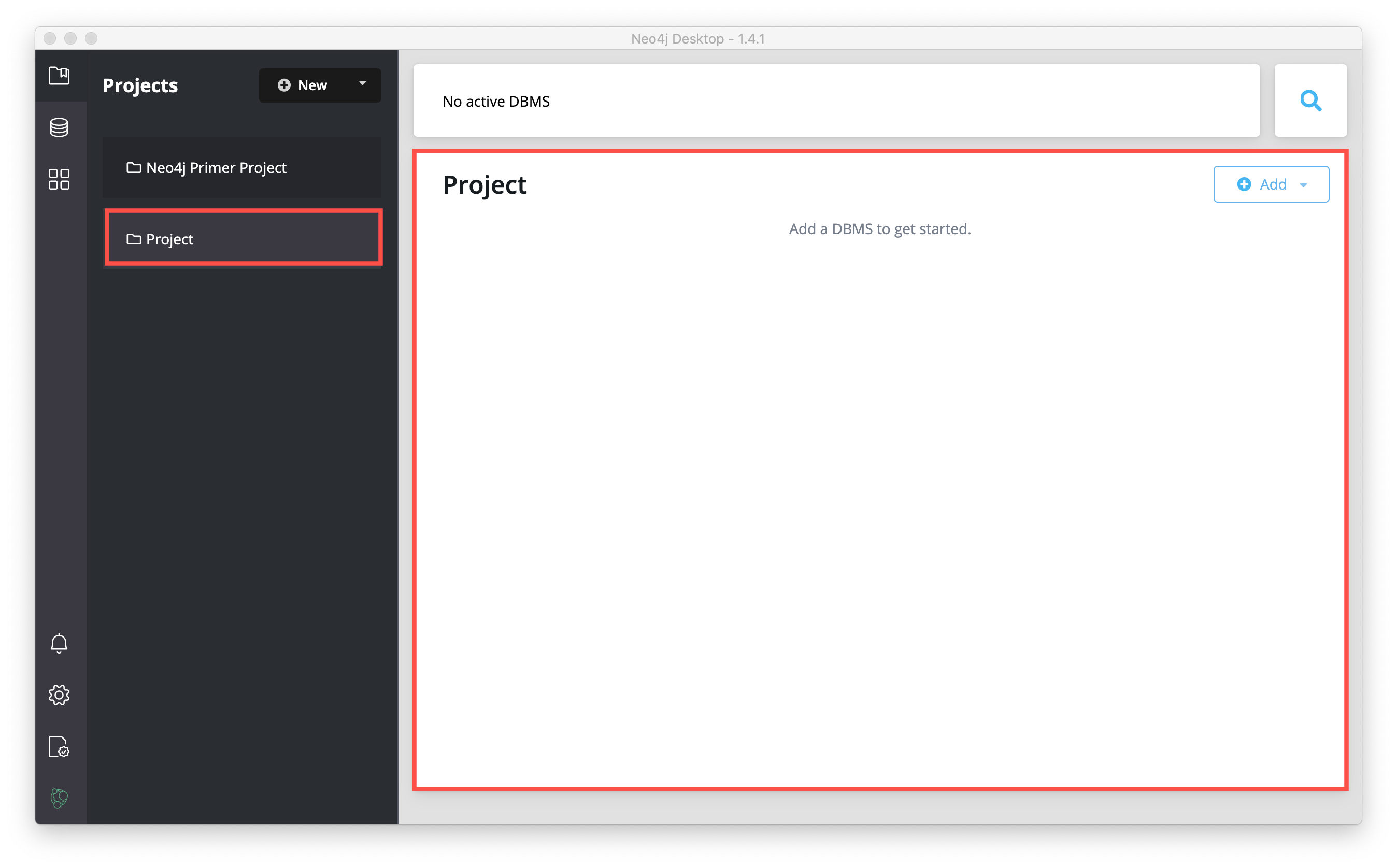
You want your projects to be named something that describes the goal of the project. You can change the name of a project by hovering over the area to the right of the project name and selecting the Edit button:
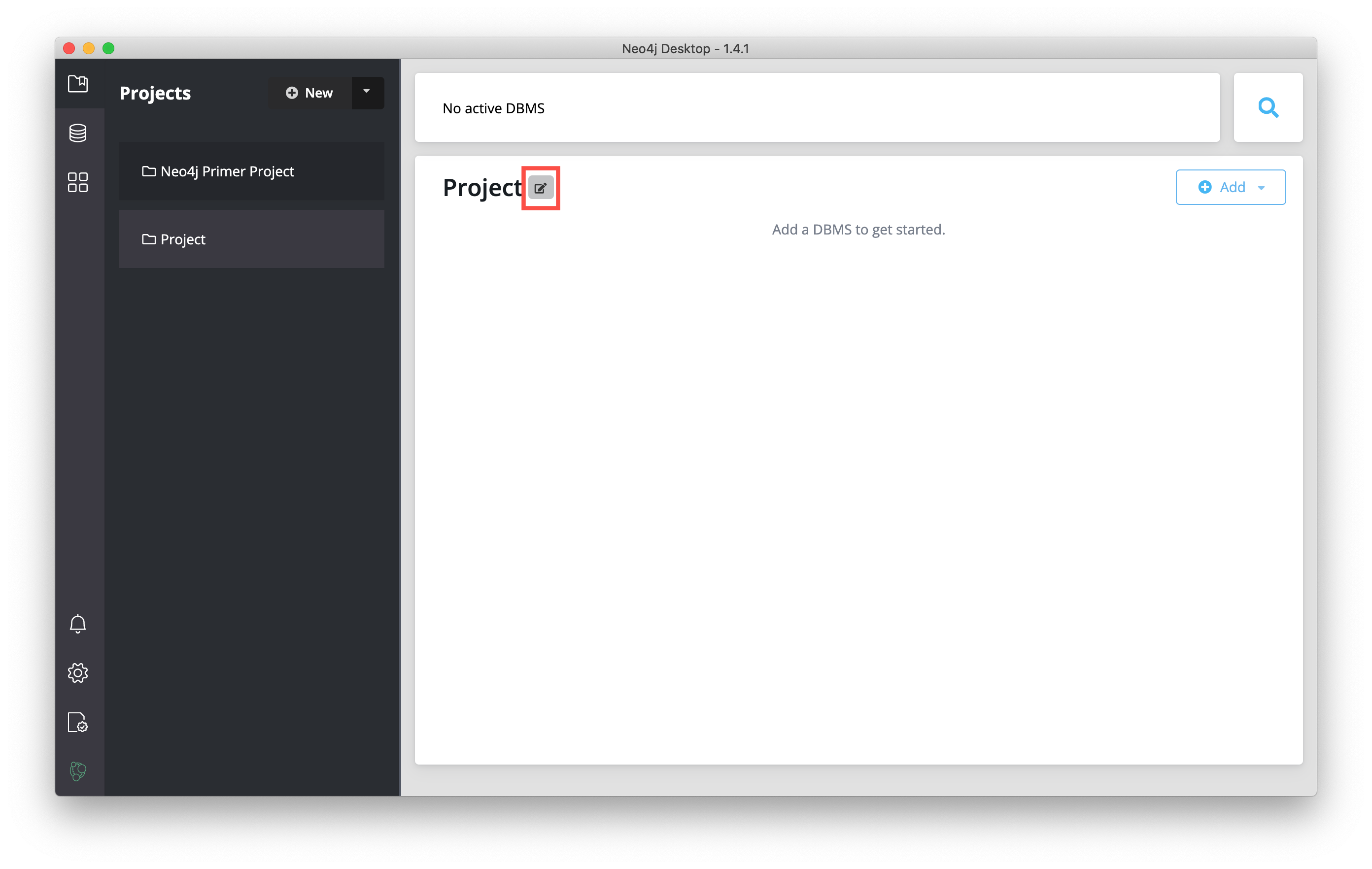
Then you type a name for the project and select the "Check" button to save the name.
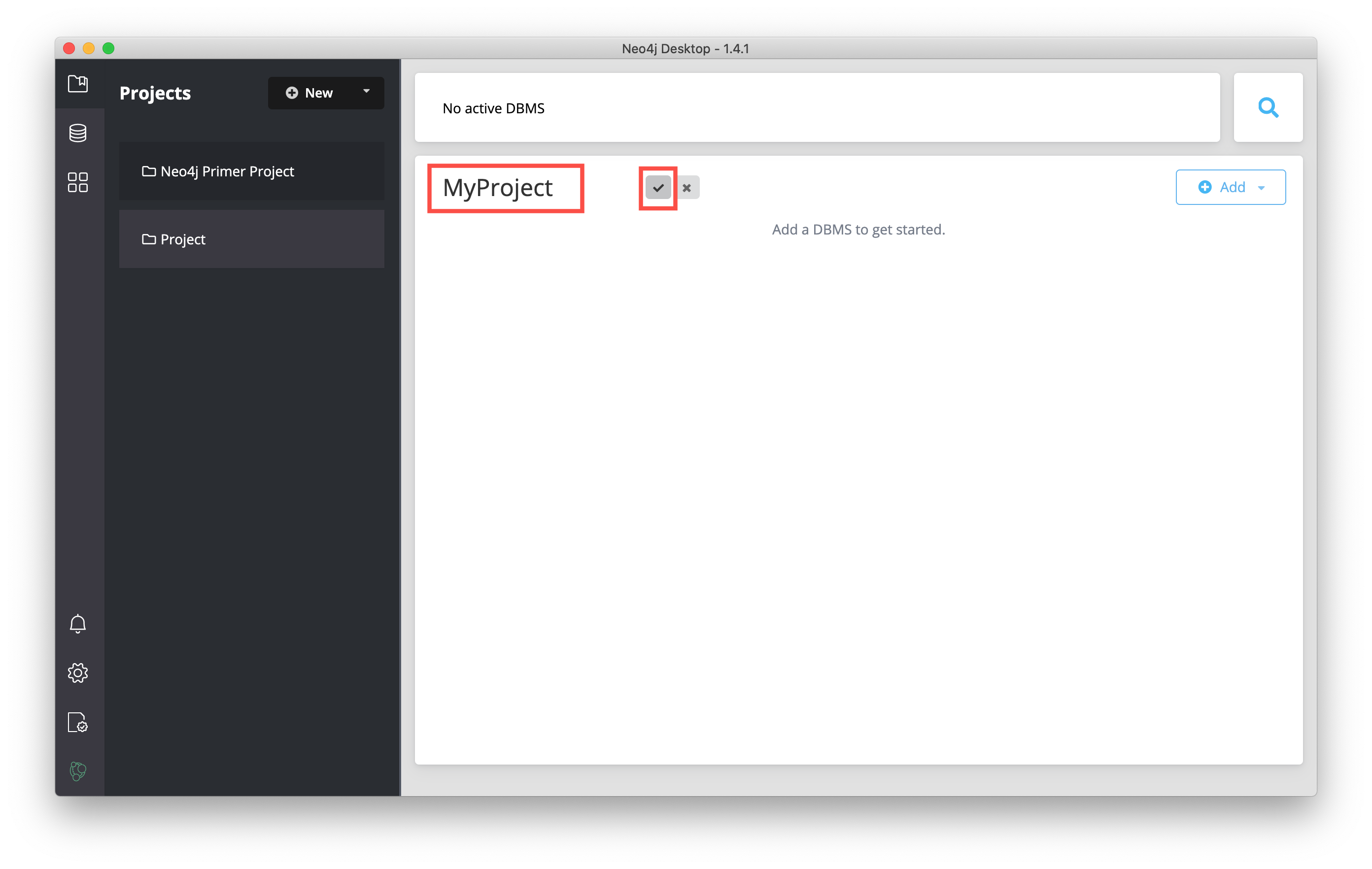
And here we see the project with the changed name:
In a Neo4j Desktop project, you can create one or more DBMSs. Next, you will create a local DBMS in a project and start it.
In the project where you want to add the DBMS, click the Add button, and then select Local DBMS:
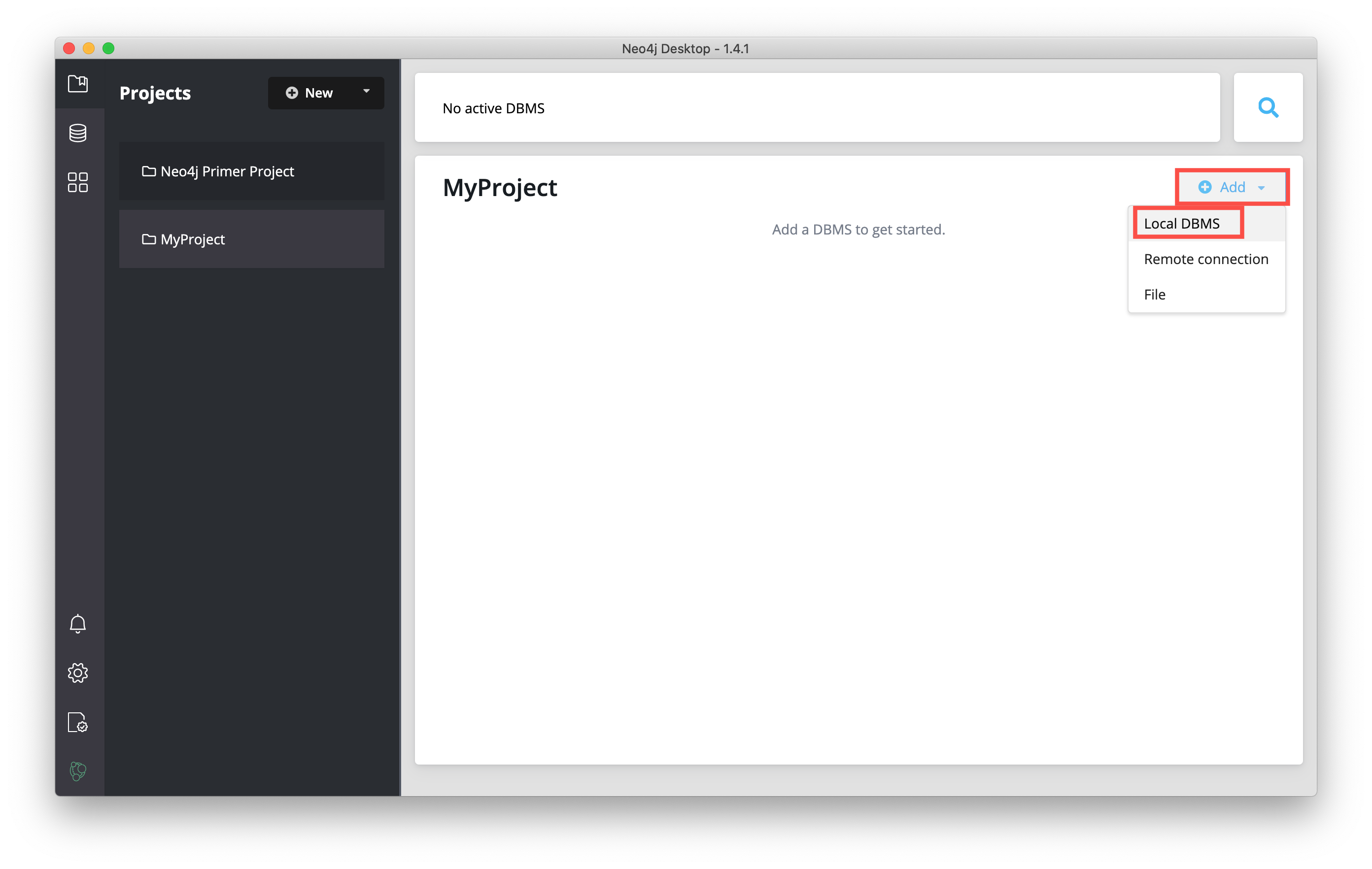
This opens a dialog where you will specify the details of the DBMS. You can use the default name for the DBMS, which is Graph DBMS, but you should name it something that helps to identify the use case for the DBMS. Here we specify MyDBMS as the name:
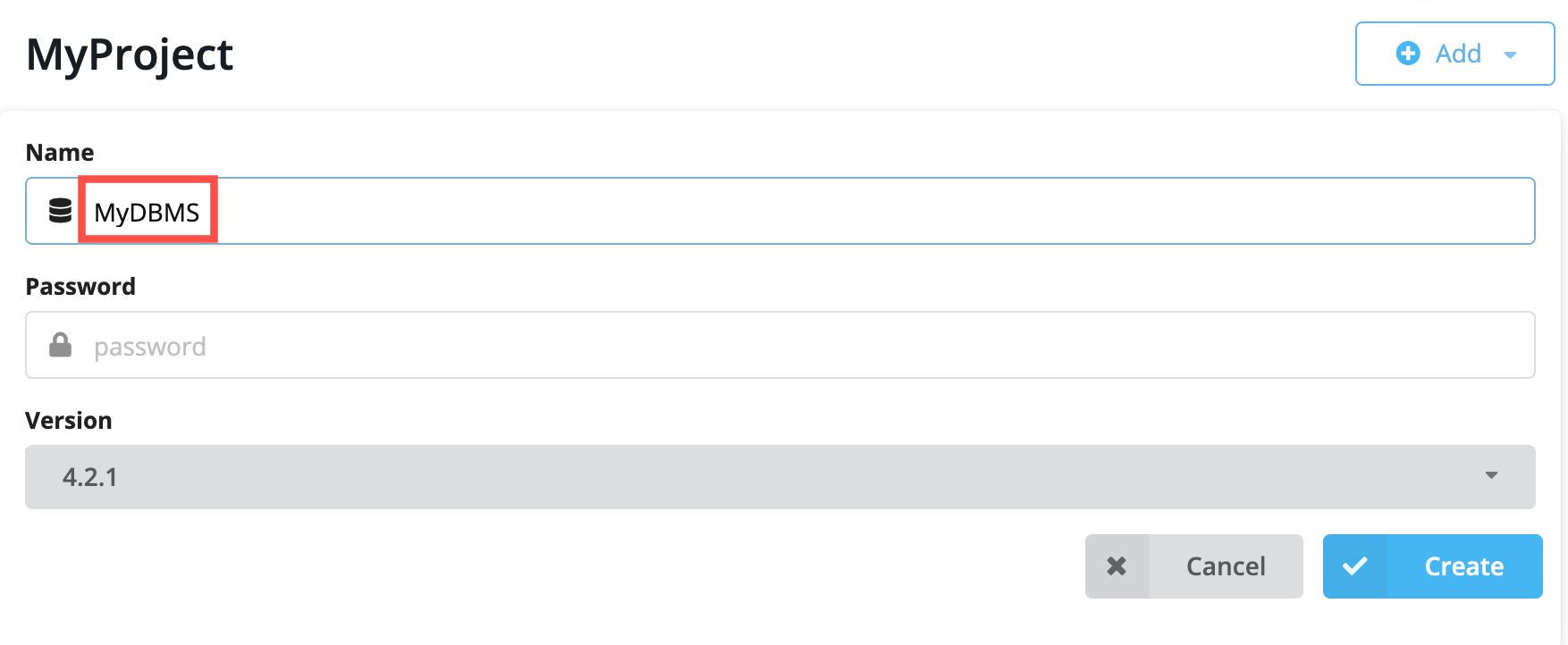
You must specify a password for the DBMS so enter a password that you will remember:
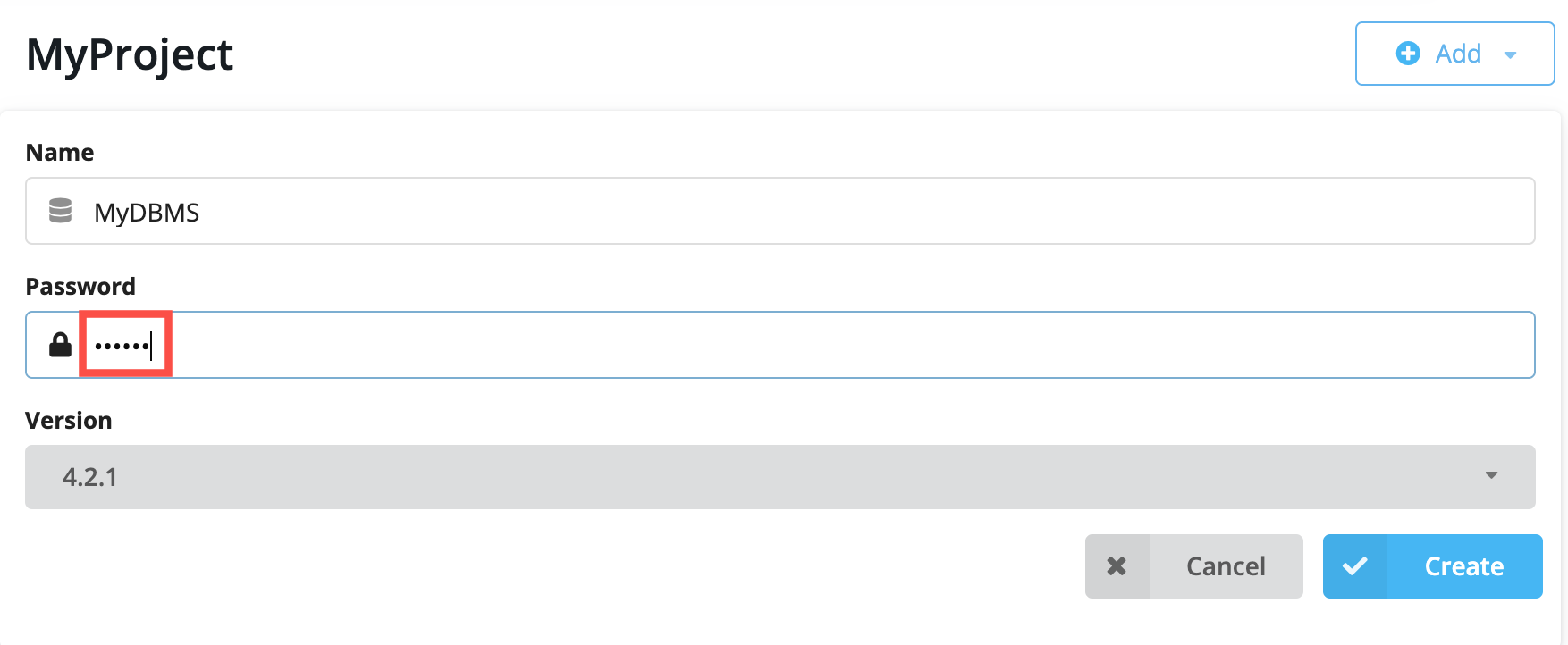
Neo4j Desktop will create a DBMS with the default version for Neo4j Desktop. However, you can select a different version. Keep in mind that if there is a down arrow shown next to the version, this means that Neo4j Desktop will need to download resources for that particular version of the DBMS. To do this you must be connected to the Internet:
After you have specifed the details for the DBMS you want to create, you click the Create button:
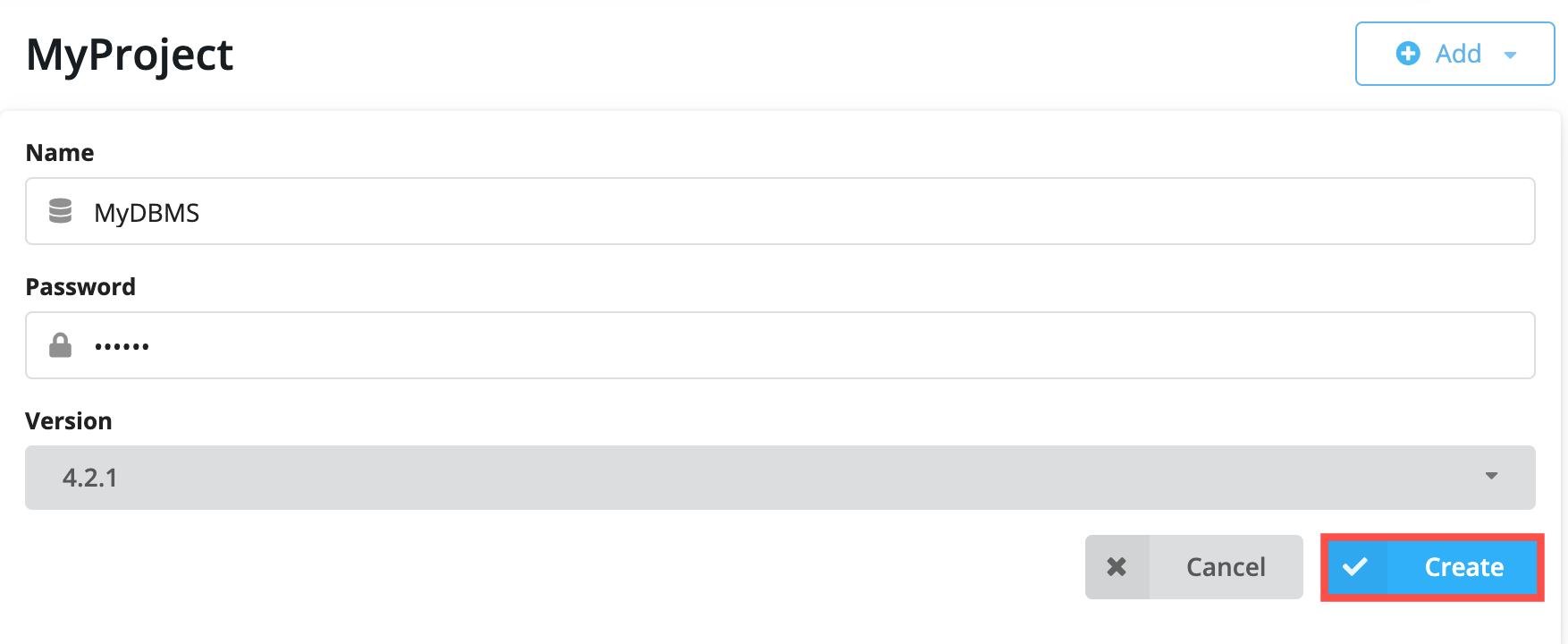
And here is what you should see after the DBMS is successfully created:
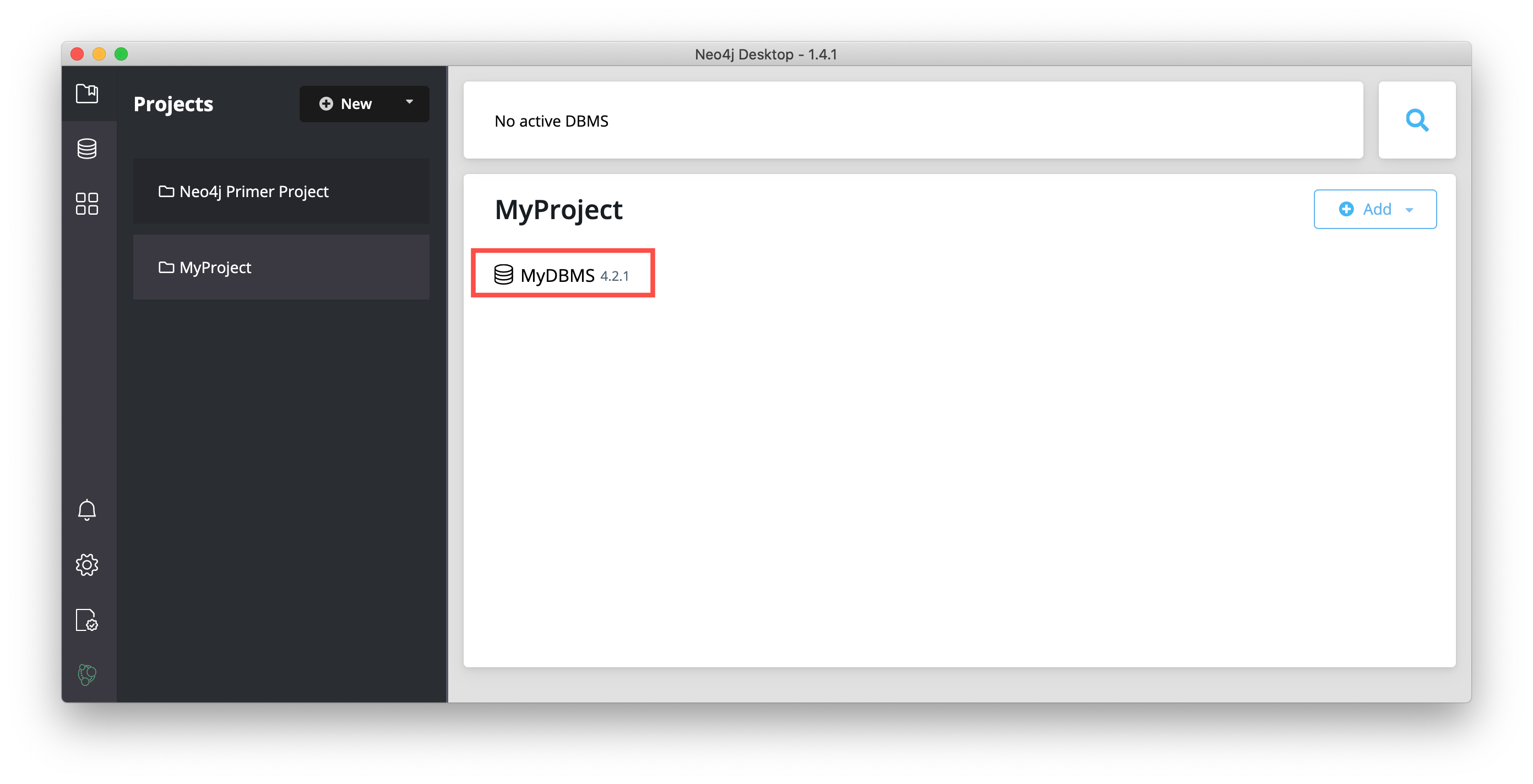
Recall that you cannot have more than one DBMS started. Provided you have no other DBMSs started in Neo4j Desktop, you can start your newly-created DBMS by hovering to the right of the DBMS name and clicking the Start button:

The DBMS will take a few seconds to start. After it is started, you should see something like this:
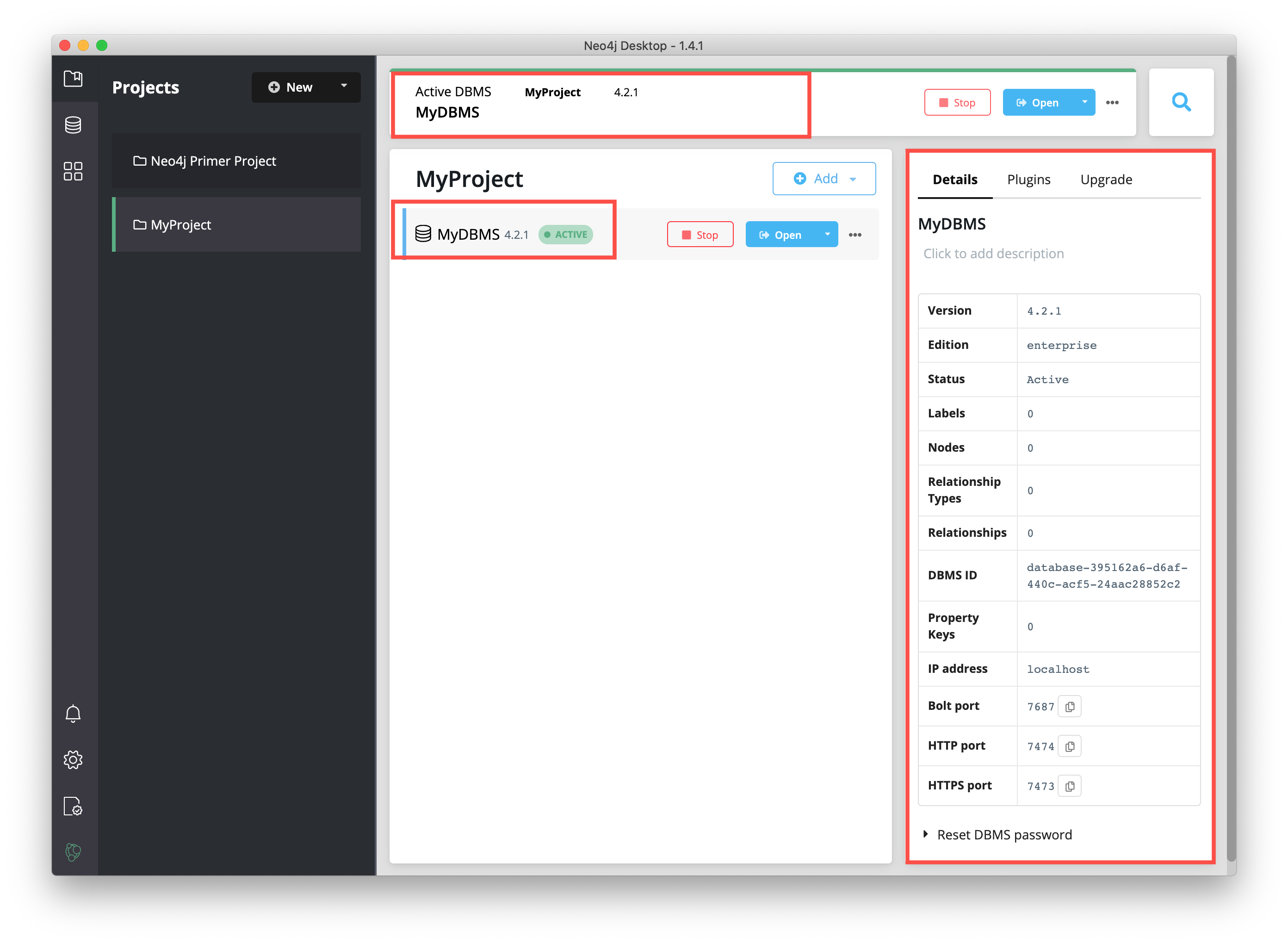
After the DBMS is started, you can access it with clients running on your system such as Neo4j Browser, Neo4j Bloom, etc. In Neo4j Desktop, the DBMS is an Enterprise Server, but it can only be accessed locally.
2. Putting CSV files in the import folder
First, download this zip file. Uncompress/unzip this file which should yield three CSV files for products, orders, and order details. You will put these files in the import folder that Neo4j expects for imports.
Open a finder window on your system by hovering over the three dots to the right started DBMS and selecting Open folder, and then Import:
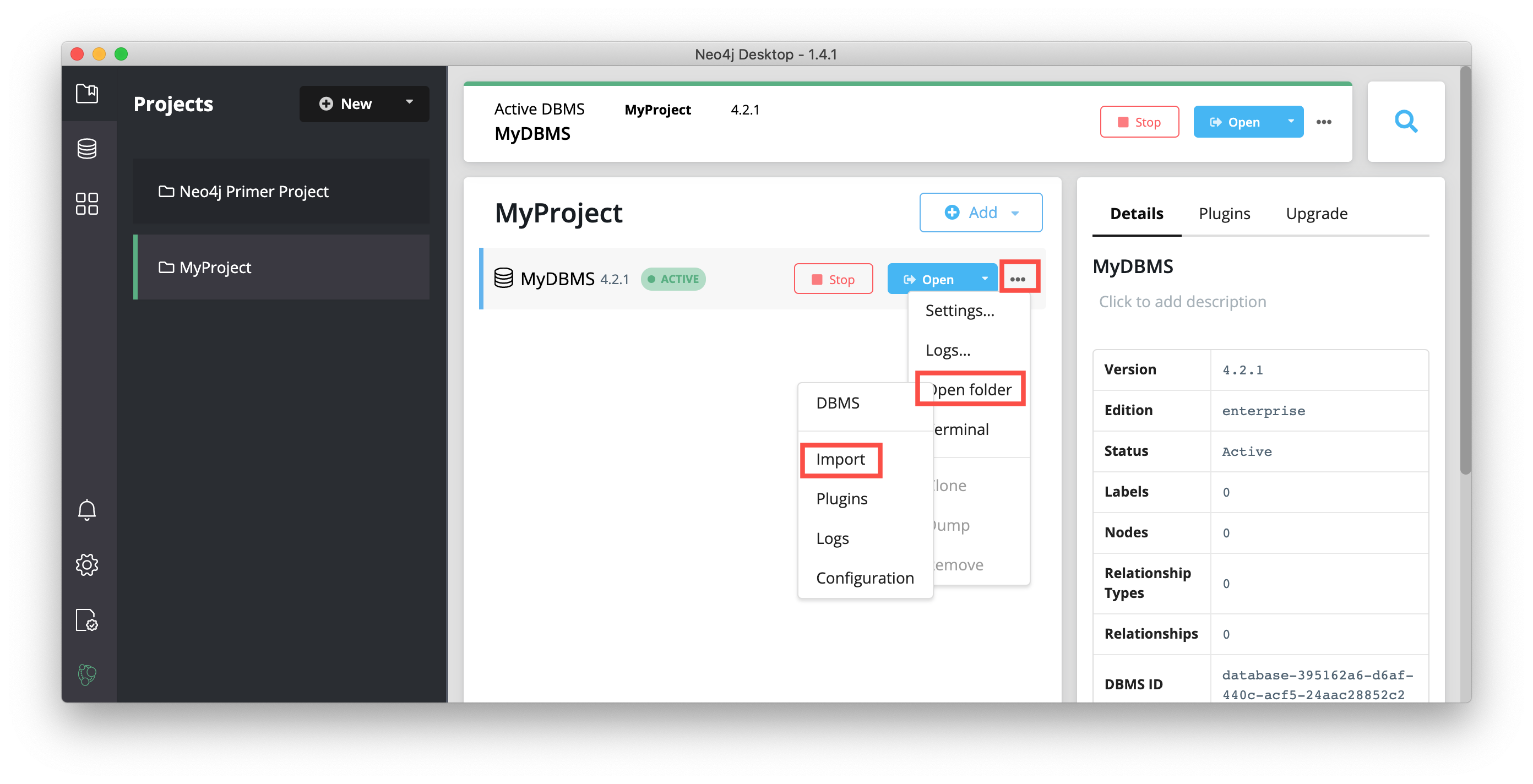
Copy or move the three CSV files into this import folder on your system:
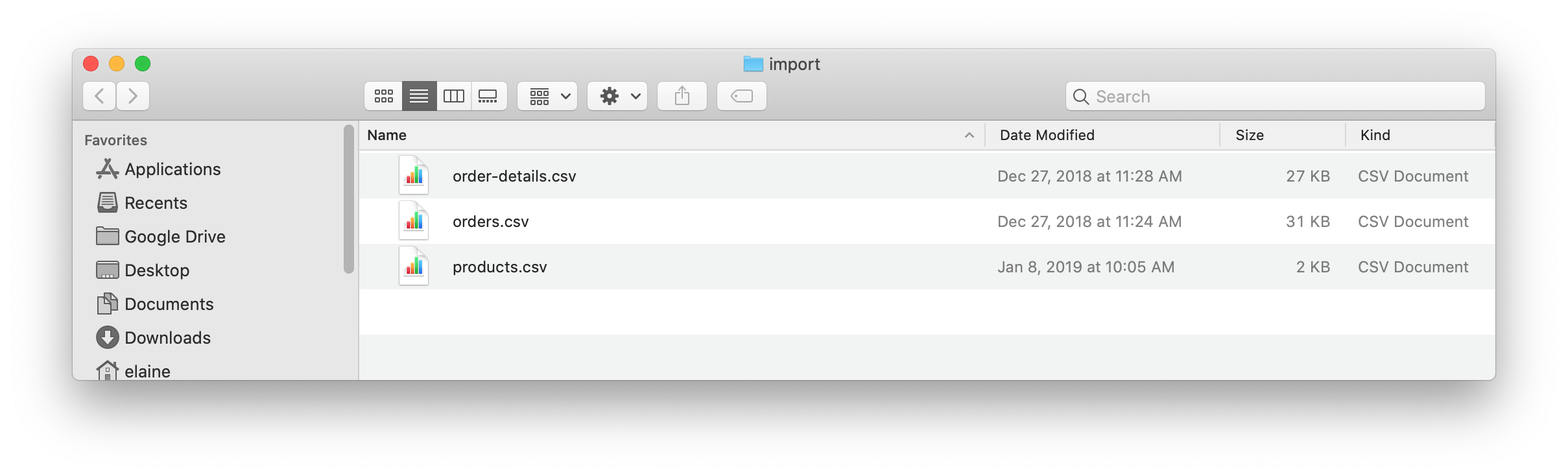
Now that your files are in the import folder, you can import the data into the database managed by the DBMS.
You will use the current table and column format in the CSV files and translate it into nodes and relationships.
This can be done a few different ways, but you will use Cypher’s LOAD CSV command in this guide.
LOAD CSV
LOAD CSV is a built-in command in Cypher that allows you to read CSV files and append regular Cypher statements to create or update the data as a graph.
You can also use LOAD CSV without creating the graph to output samples, counts, or distributions.
This helps to detect incorrect header column counts, delimiters, quotes, escapes, or spelling of header names before the data is written and stored.
To enter and run Cypher statements on a started DBMS, you can:
-
Use Neo4j Browser:
-
Click the Open button for the started DBMS
-
Type or copy Cypher statements into the edit pane.
-
Execute the Cypher with the
playbutton on the right.
-
-
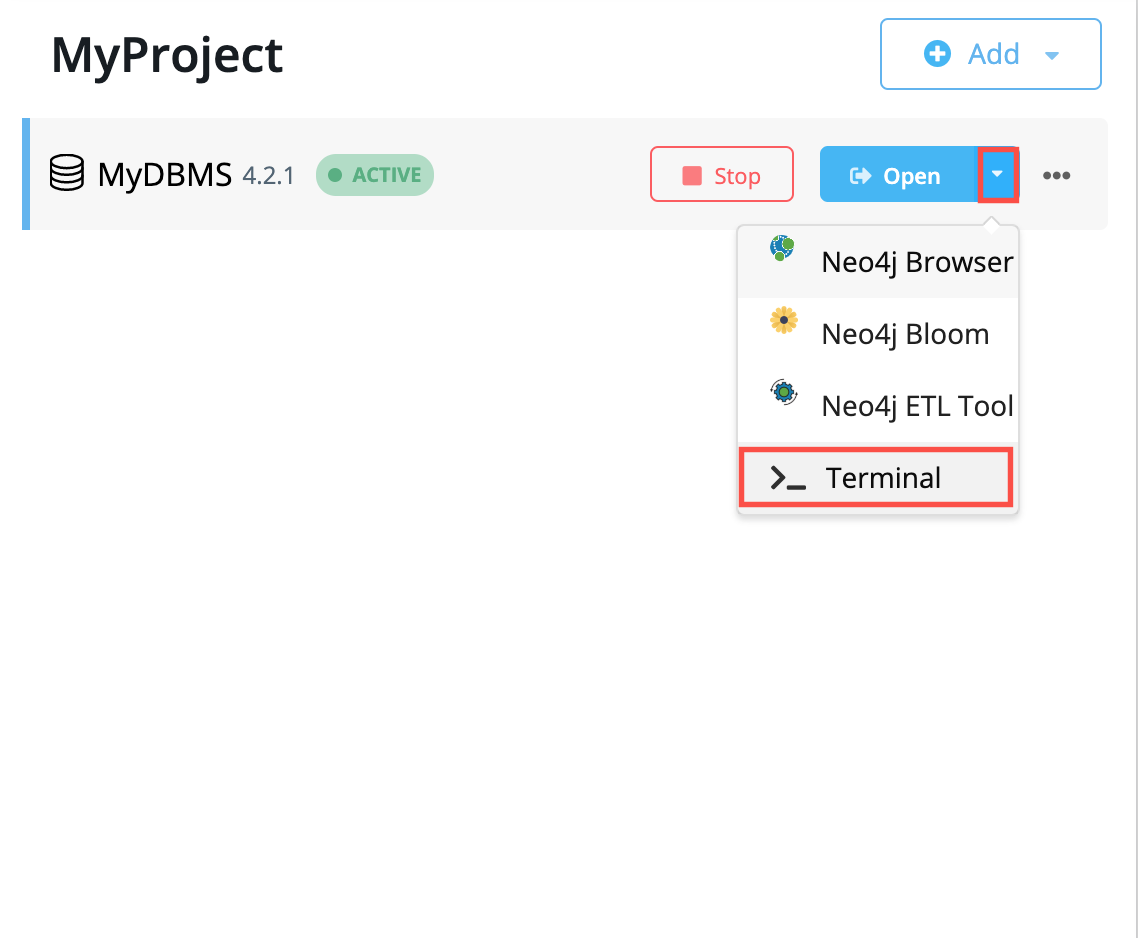
Use cypher-shell:
-
Click the drop-down menu to the right of the Open button and select Terminal.
-
-
Enter
bin/cypher-shell. -
Enter neo4j for the user.
-
Enter the password you specified for the DBMS.
-
All Cypher statements must end with ";"
-
Use
:exitto quit.
In Step 2, you downloaded the .zip file and copied its CSV files to the import folder for the DBMS.
Before you insert anything into your graph database, you should inspect the data in the files a bit.
To do this, you can use the LOAD CSV statement.
If you opened the files previously, you may have noticed that two of the files have headers and one does not (products.csv).
Let us see how to inspect each type of file.
First, you can check how many lines are in the CSV files to ensure they didn’t get corrupted or cut off from a potential export process.
For the files with headers, you simply add the WITH HEADERS clause after LOAD CSV, so that it excludes the header row in the count and only counts the rows of data.
You should execute this Cypher:
//count data rows in products.csv (no headers)
LOAD CSV FROM 'file:///products.csv' AS row
RETURN count(row);//count data rows in orders.csv (headers)
LOAD CSV WITH HEADERS FROM 'file:///orders.csv' AS row
RETURN count(row);//count data rows in order-details.csv (headers)
LOAD CSV WITH HEADERS FROM 'file:///order-details.csv' AS row
RETURN count(row);Running these statements should return the following counts:
-
77 rows for products.csv
-
830 rows for orders.csv
-
2155 rows for order-details.csv
View Data with LOAD CSV
Next, you can take a look at what the data looks like in the CSV files and how LOAD CSV sees it.
The only line you need to change from the Cypher above is the RETURN statement.
Since all of these files have several rows, you will use LIMIT to only get a sample.
//view data rows in products.csv
LOAD CSV FROM 'file:///products.csv' AS row
RETURN row
LIMIT 3;Your results should look something like this:
| row |
|---|
["1", "Chai", "18"] |
["2", "Chang", "19"] |
["3", "Aniseed Syrup", "10"] |
//count data rows in orders.csv (headers)
LOAD CSV WITH HEADERS FROM 'file:///orders.csv' AS row
RETURN row
LIMIT 5;Your results should look something like this:
| row |
|---|
|
|
|
|
|
//count data rows in order-details.csv (headers)
LOAD CSV WITH HEADERS FROM 'file:///order-details.csv' AS row
RETURN row
LIMIT 8;Your results should look something like this:
| row |
|---|
|
|
|
|
|
|
|
|
Notice that the orders.csv and the order-details.csv return in a different format from the products.csv.
This is because those files have headers, so the column names are returned with the values for those rows.
Since the products.csv does not have column names, then LOAD CSV just returns the plain data row from the file.
Filtering what you load with LOAD CSV
After inspecting the data, you may only want to view or load a subset of the data in the CSV file. You can filter what you view (or load) as follows:
//count data rows in orders.csv (headers)
LOAD CSV WITH HEADERS FROM 'file:///orders.csv' AS row
WITH row WHERE row.shipCountry = 'Germany'
RETURN row
LIMIT 5;Your results should look something like this:
| row |
|---|
|
|
|
|
|
Data types
The LOAD CSV command reads all values as a string.
No matter how the value appears in a file, it will be loaded as a string with LOAD CSV.
So, before you import, you want to ensure you convert any values that are non-string.
There are a variety of conversion functions in Cypher. The ones you will use for this exercise are as follows:
-
toInteger(): converts a value to an integer.
-
toFloat(): converts a value to a float (in this case, for monetary amounts).
-
datetime(): converts a value to a datetime.
We will look at the values in each CSV file to determine what needs to be converted.
The values in the products.csv files are for product ID, product name, and unit cost.
Product ID looks like an integer value that increases with each row, so you can convert this to an integer using the toInteger() function in Cypher.
Product name can remain a string since it consists of characters.
The final column is the product unit cost.
Though the sample values from your inspection are all whole numbers, we know that monetary amounts often have decimal place values, so we will convert these values to floats using the toFloat() function.
You can see the Cypher to handle all of these conversions below; however, you are still not loading the values into Neo4j yet. You will be just viewing the CSV files with converted values.
LOAD CSV FROM 'file:///products.csv' AS row
WITH toInteger(row[0]) AS productId, row[1] AS productName, toFloat(row[2]) AS unitCost
RETURN productId, productName, unitCost
LIMIT 3;Your results should look something like this:
| productId | productName | unitCost |
|---|---|---|
1 |
"Chai" |
18.0 |
2 |
"Chang" |
19.0 |
3 |
"Aniseed Syrup" |
10.0 |
Note that we are using collection positions (row[0], row[1], row[2]) to refer to the columns in the row and improve readability by using aliases to reference them in the return. In a file that has no headers, this is how to reference values in each position.
The values in the orders.csv (per the column names) are for orderID, orderDate, and shipCountry. Again, you can evaluate the values and determine any conversions to apply.
OrderID looks like an integer, so you can convert that using the toInteger() function.
The orderDate column is certainly in a date format and will require us to format it using the datetime() function.
Finally, the shipCountry values are characters, so you can leave that as a string.
Just as you did with the last CSV files, let us look at the results of these conversions without importing the data.
LOAD CSV WITH HEADERS FROM 'file:///orders.csv' AS row
WITH toInteger(row.orderID) AS orderId, datetime(replace(row.orderDate,' ','T')) AS orderDate, row.shipCountry AS country
RETURN orderId, orderDate, country
LIMIT 5;Your results should look something like this:
| orderId | orderDate | country |
|---|---|---|
10248 |
"1996-07-04T00:00:00Z" |
"France" |
10249 |
"1996-07-05T00:00:00Z" |
"Germany" |
10250 |
"1996-07-08T00:00:00Z" |
"Brazil" |
10251 |
"1996-07-08T00:00:00Z" |
"France" |
10252 |
"1996-07-09T00:00:00Z" |
"Belgium" |
There was one tricky thing with this CSV in the orderDate column.
Neo4j’s datetime uses the ISO 8601 format which uses the delimiter T between the date and time values.
The CSV file does not have the 'T' joining the date and time values but has a space between them instead.
You used the replace() function to change the space to the character 'T' and get the string into the expected format.
Then, you wrapped the datetime() function around that to convert the changed string to a datetime value.
The values in the order-details.csv (from column names) are for productID, orderID, and quantity. Let us look at which ones need to be converted.
product ID is also from the products.csv file, where you converted that value to an integer.
You will do the same here to ensure you match formats.
The order ID field contains values from the orders.csv file, so you will match your previous conversion and translate this field to an integer, as well.
The quantity field in this file is a numeric value.
You can convert this to an integer with the toInteger() function you have been using.
The results of these conversions are in the code below. Remember that you still are not loading any data yet.
LOAD CSV WITH HEADERS FROM 'file:///order-details.csv' AS row
WITH toInteger(row.productID) AS productId, toInteger(row.orderID) AS orderId, toInteger(row.quantity) AS quantityOrdered
RETURN productId, orderId, quantityOrdered
LIMIT 8;Your results should look something like this:
| productId | orderId | quantityOrdered |
|---|---|---|
11 |
10248 |
12 |
42 |
10248 |
10 |
72 |
10248 |
5 |
14 |
10249 |
9 |
51 |
10249 |
40 |
41 |
10250 |
10 |
51 |
10250 |
35 |
65 |
10250 |
15 |
Loading the data!
Now that you have determined that the CSV file data looks OK, and you have verified how LOAD CSV sees the data and converted any non-string values, you are almost ready to create the data in our graph database!
To do that, you will use Cypher statements alongside the LOAD CSV commands you used above.
The LOAD CSV will read the files, and the Cypher statements will create the data in your database.
Graph data model
An important step you need before writing Cypher statements, though, is to determine what the graph structure should look like once you import your file data. After all, importing the data in the existing table and column data will not provide the value you want to achieve from a graph. To utilize the graph database fully, you need a graph data model.
Though there are a variety ways to organize the products and orders in your files, we will save that for another guide and use the below version of the model for this exercise.

We have two nodes - one for a product and one for an order.
Each of those nodes have properties from the CSV files.
For the Product, we have ID, name, and unit cost.
For the Order, we have ID, date/time, and country where it is going.
The order-details.csv file defines the relationship between those two nodes.
That file has the product ID, the order ID it belongs to, and the quantity of the product on the order.
So, in the data model, this becomes the CONTAINS relationship between Product and Order nodes.
We also include a property of quantityOrdered on the relationship because the product quantity value only exists when a product is related to an order.
Now that you know the types of nodes and relationships you will have and the properties involved, you can construct the Cypher statements to create the data for this model.
Avoiding duplicates and increasing performance
One final thing you need to think about before you create data in the graph is ensuring values are unique and performance is efficient. To handle this, you can use constraints. Just as with other databases, constraints ensure data integrity criteria is not violated, while simultaneously indexing the property with the constraint for faster query performance.
There are cases for applying indexes to a database before any data and with existing data.
In this exercise, you will add two constraints before you create any data - one for productId and one for orderId.
This will ensure that, when you create a new node of each of those types or a relationship to connect them, you know the entities are unique and indexed.
Below is the Cypher for adding indexes.
CREATE CONSTRAINT UniqueProduct ON (p:Product) ASSERT p.id IS UNIQUE;
CREATE CONSTRAINT UniqueOrder ON (o:Order) ASSERT o.id IS UNIQUE;Cypher
Now you are ready to write the Cypher for creating the data in the graph!
You could use CREATE statements where you are sure that you will not have duplicate rows in your CSV file and use MATCH to find existing data for updates.
However, since it is hard to completely scrub all data and import perfectly clean data from any source, you will use MERGE statements to check if the data exists before inserting.
If the node or relationship exists, Cypher will match and return (without any writes), but if it does not exist, Cypher will insert it.
Using MERGE can have some performance overhead, but often it is the better approach to maintain high data integrity.
|
Why both constraints and MERGE?
Using constraints is different from using MERGE.
Statements that create data in violation of the constraint will error, while statements that use |
To start, you will load the products into the graph.
You start with your LOAD CSV statement from above, then you add the Cypher to create the data from the CSV into your graph model.
You will use the MERGE statement to check if the Product already exists before you create it.
The properties will be set to the converted values you handled earlier in this guide.
LOAD CSV FROM 'file:///products.csv' AS row
WITH toInteger(row[0]) AS productId, row[1] AS productName, toFloat(row[2]) AS unitCost
MERGE (p:Product {productId: productId})
SET p.productName = productName, p.unitCost = unitCost
RETURN count(p);If you run that statement, it will return the number of product nodes (count(p)) that were created in the database.
You can cross-check that number with the number of rows in the CSV file from earlier (77 rows in products.csv).
You can also run a validation query to return a sample of nodes and review that the properties look accurate.
//validate products loaded correctly
MATCH (p:Product)
RETURN p LIMIT 20;Here are the results in Neo4j Browser:

Next, you will load the orders.
Again, since you want to verify you do not create duplicate Order nodes, you can use the MERGE statement.
Just as with products, you start with the LOAD CSV command, then add Cypher statements and include your data conversions.
LOAD CSV WITH HEADERS FROM 'file:///orders.csv' AS row
WITH toInteger(row.orderID) AS orderId, datetime(replace(row.orderDate,' ','T')) AS orderDate, row.shipCountry AS country
MERGE (o:Order {orderId: orderId})
SET o.orderDateTime = orderDate, o.shipCountry = country
RETURN count(o);You can also run a validation query, as before, to verify the graph data looks correct.
//validate orders loaded correctly
MATCH (o:Order)
RETURN o LIMIT 20;Here are the results in Neo4j Browser:

Last, but not least, you will create the relationship between the products and the orders.
Since you expect all of your products and all of your orders to already exist in the graph (that data should have been loaded with the last two files), then you start with MATCH to find the existing Product and Order nodes.
Then, the MERGE statement will add the new relationship or match an existing one.
As you found when you ran a count on the order-details file above, there are 2,155 rows in the CSV.
While this is not a huge number for file imports, you will have Cypher periodically commit the data to the database to reduce the memory overhead of the transaction state.
For this, you can add the :auto USING PERIODIC COMMIT clause before the LOAD CSV command.
The default value for periodic commit is 1,000, but for this exercise, you will ask Cypher to commit every 500 rows.
You could decrease this number if you have a lot of memory already allocated to other tasks, or if it is limited.
:auto USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM 'file:///order-details.csv' AS row
WITH toInteger(row.productID) AS productId, toInteger(row.orderID) AS orderId, toInteger(row.quantity) AS quantityOrdered
MATCH (p:Product {productId: productId})
MATCH (o:Order {orderId: orderId})
MERGE (o)-[rel:CONTAINS {quantityOrdered: quantityOrdered}]->(p)
RETURN count(rel);Just as you did above, you can validate the data with the query below.
MATCH (o:Order)-[rel:CONTAINS]->(p:Product)
RETURN p, rel, o LIMIT 50;Here are the results in Neo4j Browser:

Wrapping up
Congratulations! You have successfully loaded 3 CSV files into a Neo4j graph database using Neo4j Desktop!
The LOAD CSV functionality, coupled with Cypher, is exceptionally useful for getting data from files into a graph structure.
The best way to advance your skills in this area is to load a variety of files for various data sets and models.
Practice makes perfect!
If you work through this exercise again at a later time, feel free to increase the challenge by coming up with your own data model for these files or try to load some other CSV files to a graph.
If you have any questions or need assistance using LOAD CSV, reach out to us on the Community Site!
To learn more about LOAD CSV and its uses, check out our guide on LOAD CSV.
Was this page helpful?